Elasticsearch painless脚本教程(包含Java API和SpringDataElasticsearch调用脚本)

Elasticsearch painless脚本
1.什么是painless
painless是ElasticStack在升级到5.0版本之后新增的脚本语言,而且针对性的优化了Elasticsearch的场景。由于支持了java的静态类型和Java的lambda表达式,对于Elasticsearch数据的操作更轻量和快速,而且painless脚本因此更加简单安全。 painless脚本分为inline script(api请求时使用)和stored script(存储使用),可类比如SQL查询语句和存储过程。
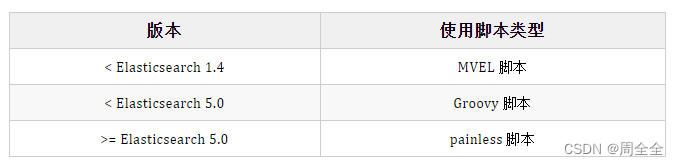
es的版本与脚本的演化过程:
本文仅介绍常用的es脚本操作语句可以快速入手,如果需要深入的学习,官方文档才是最好的学习资料
官方文档地址:https://www.elastic.co/guide/en/elasticsearch/painless/7.9/painless-guide.html
2.painless的特性
-
快速性能:painless脚本的运行速度是其他脚本的数倍
-
安全性:具有方法调用/字段粒度的细粒度allowlist。有关可用类和方法的完整列表,请参阅Painless API参考
-
可选类型:变量和参数可以使用显式类型或动态定义类型
-
语法:painless就继承自java8,是扩展Java语法的一个子集,以提供额外的脚本语言功能
-
优化:专门为Elasticsearch脚本设计
3.使用kibana进行准备操作
3.1 使用kibana创建索引和映射
如果你对于kibana不是很理解,可以参考我之前的文章:使用kibana对Elasticsearch索引创建删除和文档的CRUD操作命令
建立测试索引
PUT /painless_test

建立mapping属性映射
#建立mapping属性映射
PUT /painless_test/_mapping
{"properties": {"author": {"type": "text","analyzer": "ik_max_word","fields": {"keyword": {"type": "keyword"}}},"age": {"type": "integer"},"paperCount": {"type": "integer"},"coreJournal": {"type": "keyword"}}
}
3.2 使用kibana添加测试数据
PUT /painless_test/_doc/1001
{"author": "阿刘慈欣","paperCount": [15,20,56],"age": 45,"coreJournal": ["MED"," JCR"," EI"," SCIE"]
}PUT /painless_test/_doc/1002
{"author": "王晋康","paperCount": [23,7,32],"age": 63,"coreJournal": [" EI"," SCIE"]
}PUT /painless_test/_doc/1003
{"author": "周全","paperCount": [57,9,34],"age": 18,"coreJournal": [" JCR"," EI"]
}
4.使用painless执行查询操作
关于脚本查询须知
_search操作的query的查询结果会输出为字段脚本(script_fields)或排序脚本(sort)中的输入。因此在脚本中的操作通过Map类型的变量doc获取值,但是_search操作不会改变document的值,就像sql中的select语句。
4.1 字段查询脚本
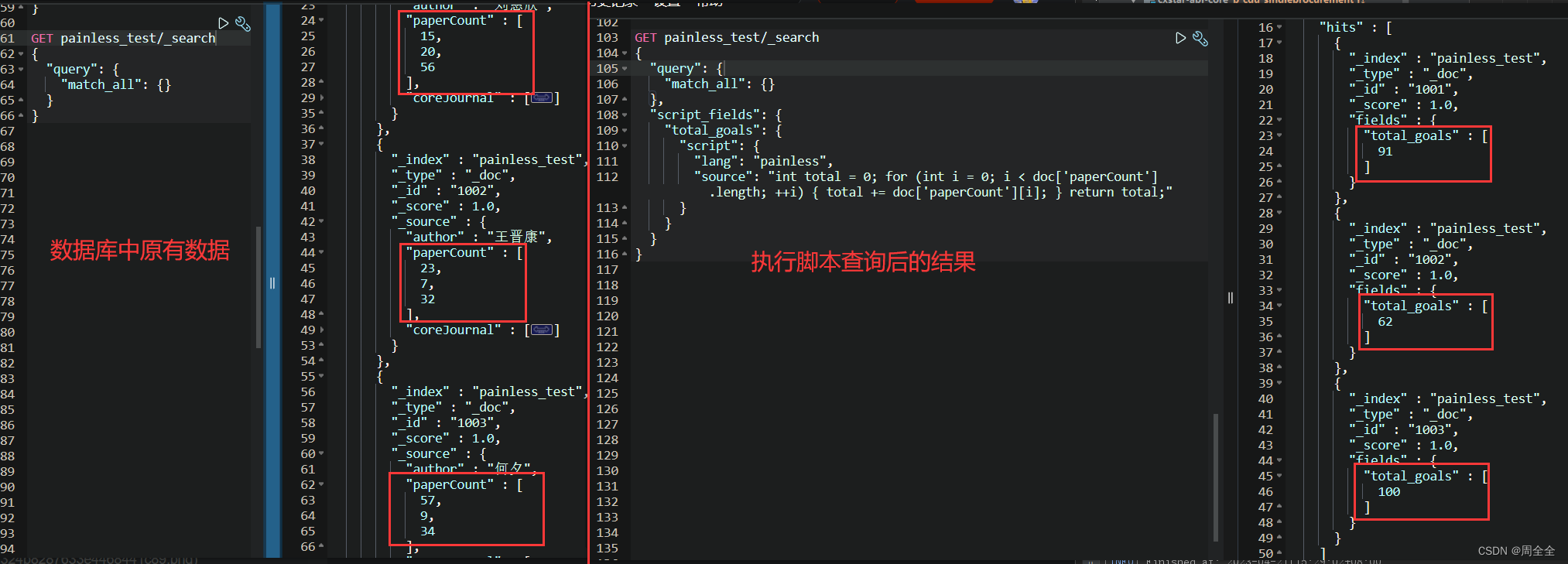
字段查询操作:将所有作者的作品数量数组(paperCount字段)累加后查询出来
GET painless_test/_search
{"query": {"match_all": {}},"script_fields": {"total_goals": {"script": {"lang": "painless","inline": "int total = 0; for (int i = 0; i < doc['paperCount'].length; ++i) { total += doc['paperCount'][i]; } return total;"}}}
}
脚本查询结果如下:
4.1 排序查询脚本
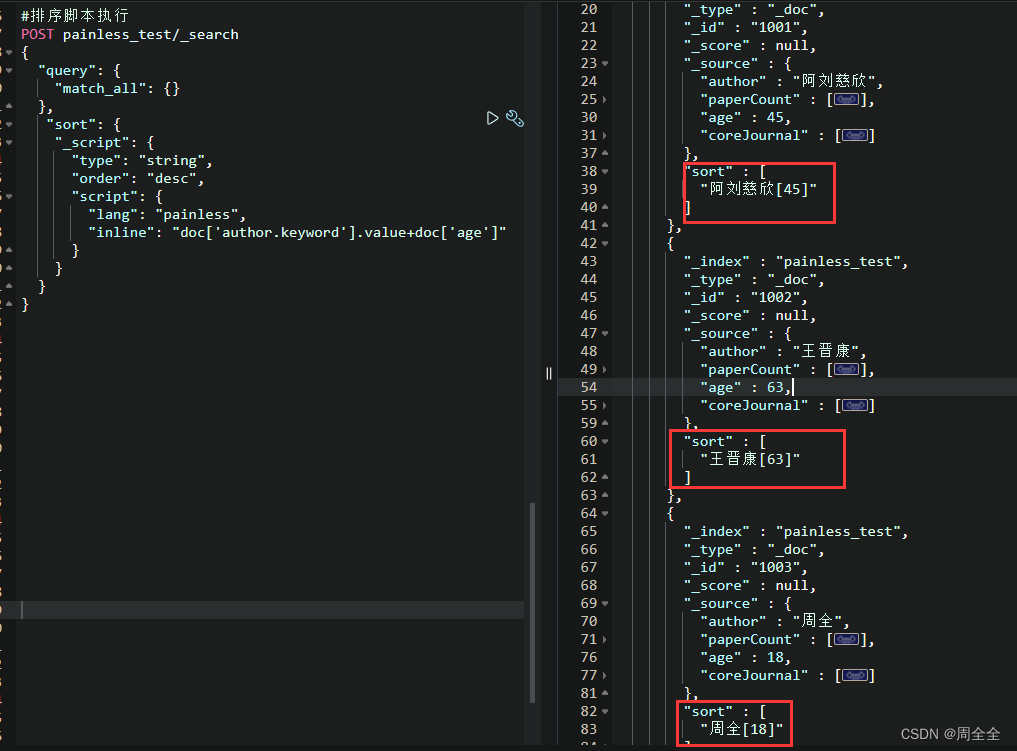
自定义排序操作:通过作者的名称和年龄相加进行排序(仅作示例,不考虑有无意义)
#排序脚本执行
POST painless_test/_search
{"query": {"match_all": {}},"sort": {"_script": {"type": "string","order": "desc","script": {"lang": "painless","inline": "doc['author.keyword'].value+doc['age']"}}}
}
5.如何使用painless执行更新操作
关于脚本查询须知
脚本更新操作推荐使用update_by_query的API,该API首先通过query语句(可以使用各种query语句)查询出满足条件的记录,再根据脚本中的操作更新查询出来的记录。需要注意的是,相对于查询使用doc访问文档的内容,更新使用的是ctx。
5.1 字段更新脚本
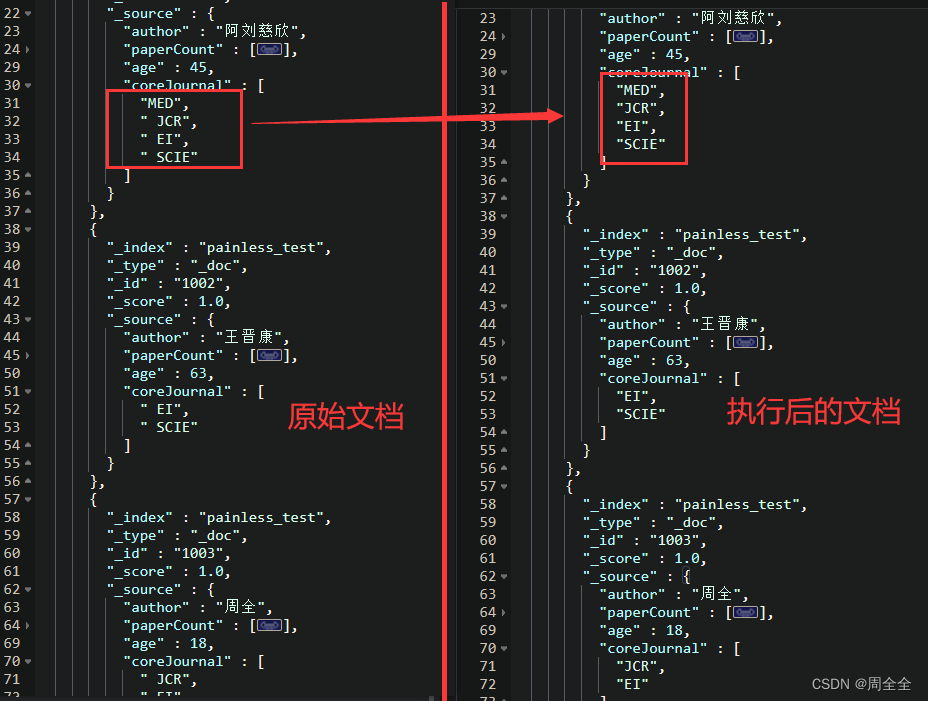
需求描述:原始文档中的coreJournal字段中值存在空格,现在要求将空格去除
实现步骤:首先根据查询条件为存在coreJournal字段的文档,然后再对coreJournal中的值进行遍历去除空格操作
POST cqu_dev_journal_paper/_update_by_query
{"script": {"source": " for (int i = 0; i < ctx._source.coreJournal.length; i++) { ctx._source.coreJournal[i]=ctx._source.coreJournal[i].trim(); }","lang": "painless"},"query": {"bool": {"must": [{"exists": {"field": "coreJournal"}}],"must_not": [],"should": []}}
}
执行效果如下:
5.2 带参数字段更新脚本
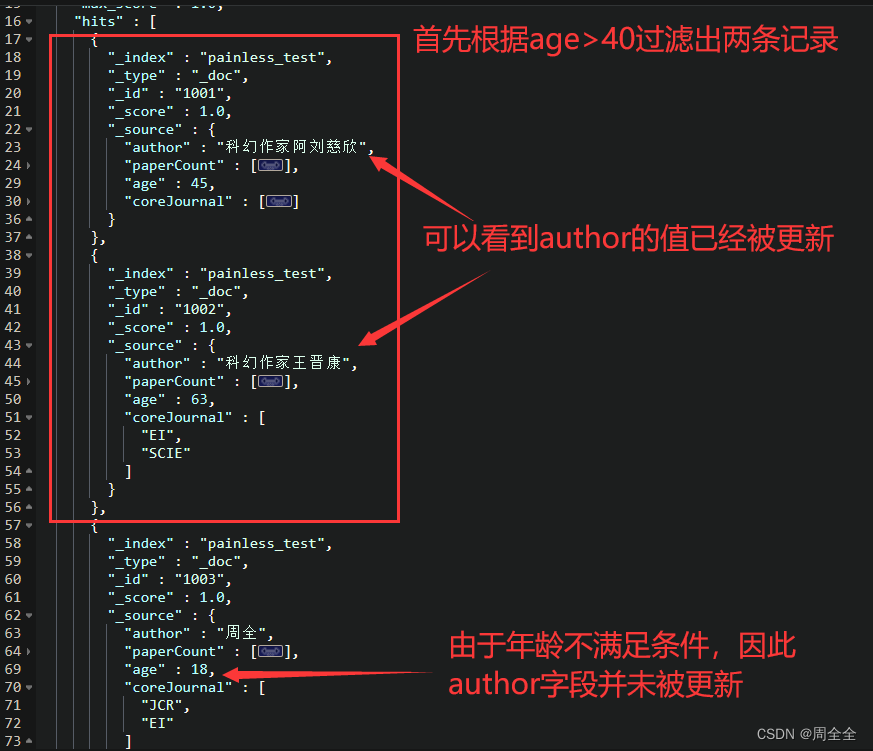
需求描述:原始文档中年龄在30岁以上的作者字段都要以"科幻作家”开头
实现步骤:首先根据查询条件为年龄在30岁以上的文档,然后再对作者字段进行更新
POST painless_test/_update_by_query
{"script": {"source": " ctx._source.author=params.prefix+ctx._source.author","lang": "painless", "params": {"prefix":"科幻作家"}},"query": {"bool": {"must": [{"range": {"age": {"from": 30}}}],"must_not": [],"should": []}}
}
执行效果如下:
6.stored script(存储使用)
# 创建单独的脚本
POST _scripts/add-age
{"script": {"lang": "painless","source": "doc['age'].value + params.myage"}
}# 获取脚本
GET _scripts/add-age# 通过指定scriptid进行调用查询
GET painless_test/_search
{"query": {"match_all": {}},"script_fields": {"addage": {"script": {"id": "add-age", "params": {"myage": 15}}}}
}# 删除脚本
DELETE _scripts/calculate-score6.使用Java API 更新ES
通过Java API实现 5.1章节的需求
需求描述:原始文档中的coreJournal字段中值存在空格,现在要求将空格去除
实现步骤:首先根据查询条件为存在coreJournal字段的文档,然后再对coreJournal中的值进行遍历去除空格操作
public static BulkByScrollResponse updateByQuery() {BulkByScrollResponse bulkResponse = null;try {UpdateByQueryRequest request = new UpdateByQueryRequest("painless_test");request.setConflicts("proceed");request.setQuery(QueryBuilders.existsQuery("coreJournal"));String strScript = "for (int i = 0; i < ctx._source.coreJournal.length; i++) {ctx._source.coreJournal[i]=ctx._source.coreJournal[i].trim(); }";Script script = new Script(ScriptType.INLINE, "painless",strScript,Collections.emptyMap());request.setScript(script);bulkResponse = restHighLevelClient.updateByQuery(request, RequestOptions.DEFAULT);} catch (IOException e) {log.error("ES更新异常", e.getMessage());}return bulkResponse;}
7.使用SpringDataElasticsearch执行脚本
通过SpringDataElaticsearch实现 5.1章节的需求
需求描述:原始文档中的coreJournal字段中值存在空格,现在要求将空格去除
实现步骤:首先根据查询条件为存在coreJournal字段的文档,然后再对coreJournal中的值进行遍历去除空格操作
public AjaxResult updateESScript() {int updatedCount = 0;try {//构建布尔查询语句,存在coreJournal字段的值BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();boolQueryBuilder.must(QueryBuilders.existsQuery("coreJournal"));NativeSearchQuery query = new NativeSearchQueryBuilder().withQuery(boolQueryBuilder).build();//构建查询更新语句UpdateQuery updateQuery = UpdateQuery.builder(query).withScriptType(ScriptType.INLINE).withScript("for (int i = 0; i < ctx._source.coreJournal.length; i++) {ctx._source.coreJournal[i]=ctx._source.coreJournal[i].trim(); }").withLang("painless").withAbortOnVersionConflict(false).build();/* 使用ElasticsearchOperations.updateByQuery()方法执行脚本更新* param: updateQuery 要执行的查询更新语句* param: IndexCoordinates.of("painless_test") 获取要执行的索引*/ByQueryResponse byQueryResponse = elasticsearchOperations.updateByQuery(updateQuery, IndexCoordinates.of("painless_test"));long updated = byQueryResponse.getUpdated();System.out.println("本次共更新es文档数量:" + updated);} catch (Exception e) {log.info("==============es更新报错===========");e.printStackTrace();return AjaxResultGenerator.error(e.getMessage());}return AjaxResultGenerator.success(updatedCount);}