在金融领域使用机器学习的 9个技巧

机器学习已经倍证明可以预测结果和发掘隐藏的数据模式。但是必须小心使用,并遵循一些规则,否则就会在数据的荒野中徘徊而无所获。使用机器学习进行交易的道路充满了陷阱和挑战,只有那些勤奋认真地遵循规则的人才能从中获得收益。下面是一些技巧可以帮助你更好的使用机器学习进行交易。
技巧1:缩放数据
价格数据是金融任务中最常见的数据,不同的资产价格数据存在很大的差别。通过缩放数据可以减少模型在不同尺度数据上的泛化偏差,并增加收敛速度。
常见的数据缩放方法有三种:最小-最大缩放(Min-Max Scaling)、Z-Score缩放(Z-Score Scaling)和对数缩放(Log Scaling)。
-
最小-最大缩放是将数据的值线性映射到一个特定的区间内(通常是[0, 1]或[-1, 1])。这种方法可以用于已经有固定区间的情况(如图像处理),但对于金融领域中存在异常值的情况则不太适用。因为最小-最大缩放对异常值比较敏感,容易受到极端值的影响。
-
Z-Score缩放是通过将数据归一化,使其均值为0,标准差为1来实现的。这种方法通常用于服从正态分布的数据,但也可以用于非正态分布的数据,因为它可以在一定程度上降低异常值的影响。这种方法在机器学习算法中被广泛应用,可以帮助模型更快地学习,并提高算法的准确性。
-
对数缩放是通过对数据取对数来实现的,通常用于对包含极端值的数据进行缩放。对数缩放可以把大范围的数值压缩到一个比较小的区间内,从而更容易可视化和比较数据的变化。这种方法在金融领域中非常有用,因为财务数据通常具有大范围的数值变化。
选择缩放方法必须符合您的模型目标——有时它更像是一门艺术而不是一门科学。一种简单但有效的方法是使用百分比回报。虽然这不会将数据置于任何固定范围内,但它将遵循相当一致的分布(即大多数回报以零为中心)。对于某些模型(如ARIMA),假定平稳性,如果没有它,您可能无法捕获数据的潜在关系。
技巧2:避免前瞻性偏差
前瞻性偏差是指你不小心向你的模型展示未来数据的情况。听起来很难做到,不是吗?已经发布的新闻文章和推文可以被再次编辑。没有什么能够阻止这些最初包含虚假信息的内容会在后来进行修改(或反之亦然),从而导致价格波动并引起关注?基本面数据也可能会在未来被调整,这意味着你可能没有看到实际的数据,而这些数据可能会导致股票价格的波动。
如果你使用集中方法(如移动平均法)平滑时间序列数据,你可能会用未来的数据来调整过去的数据。我曾经犯过这个错误,在训练和测试中得到了看起来会让我一夜暴富的结果。因此,如果你的结果看起来过于美好,那么请检查是否存在前瞻性偏差!
技巧3: 不要将重点放在价格预测上
预测价格是很难的。如果它很容易,那么其他人也会发现同样的事情,你的优势会很快消失。在金融领域,机器学习有更好、更易于掌握的用途。
-
模式识别 - 例如,可以创建自己的扫描器来识别股市的任意模式。
-
学习你的策略何时起作用 - 你可以让机器学习算法为你提供基于数据支持的决策成功的概率。
技巧4:不要直接使用神经网络
神经网络是非常强大和令人惊叹的工具——但只有在用于正确的问题并且具有大量的数据时才是如此。如果你的问题很简单,例如特征小于10个,样本数量为100-1000,那么可以使用逻辑回归!如果你的问题更复杂,有更多的样本和特征,那么应该使用随机森林!这些模型的优点在于更易于解释、不容易过拟合,训练速度也通常较快,且无需使用大量的计算资源。
在拥有足够大的训练集时,使用神经网络也有优势,特别是在时间序列分类领域,可以使用最新的LSTM层等高级技术。我的模式扫描器就是用这种方法实现的!
技巧5: 注意不要让模型过拟合
如果你正在使用神经网络,那么过度拟合是很容易发生的。这通常表明两件事情:
-
你的数据量不够 - 因此模型很容易学习到数据所需的准确模式。
-
你的模型容量太大 - 你应该降低它的容量以迫使它更好地进行泛化学习。
你可以使用一些技术,如dropout层和正则化来帮助避免过度拟合问题。另一个建议的技术是使用验证数据集来评估模型在训练期间对未见过的数据的表现。如果你的验证数据集准确率上升的速度和训练数据集准确率一样,则说明模型并没有发生过拟合。
但是,你也可能会通过其他方式出现过度拟合的情况。例如,你是否只考虑了单一的市场条件?如果是这样,你可能会“过度拟合”到该情况,并且如果市场发生变化,你的模型可能会出现困难。
技巧6: 不要盲目复制他人的代码和模型
在当今信息量极大的时代,获取和使用他人工作的诱惑很大,但我们必须谨慎地评估和理解这些代码和模型。不能简单地复制并希望它会像预期的那样工作,必须经过深思熟虑、审慎评估后再进行决策。这是确保机器学习模型的准确性和可靠性的关键。
技巧7:适当分割训练数据
如果我给你一枚有偏向性的硬币,70%几率抛出正面,那么你会一直猜正面。机器学习有时也是如此。如果展示一个不平衡的数据集,它可能很快学会猜测主导类别以获得成功的预测。为了避免这种情况发生,在二分类问题中,我们可以考虑将训练数据按类别分成50/50的比例来迫使模型进行泛化学习,这样训练出来的模型准确率高于50%时,我们可以确定该模型不是随机猜测的。这个技巧有助于提高机器学习模型的性能和准确性。
技巧8: 分析模型失误的原因
很可能你的模型不会100%准确 - 如果是,我会怀疑你是不是误把答案告诉它了!一个好的做法是深入研究你的测试结果:你的模型在哪里失败了?这些例子是否能让你更好地了解如何进行特征工程来帮助模型更好地学习?
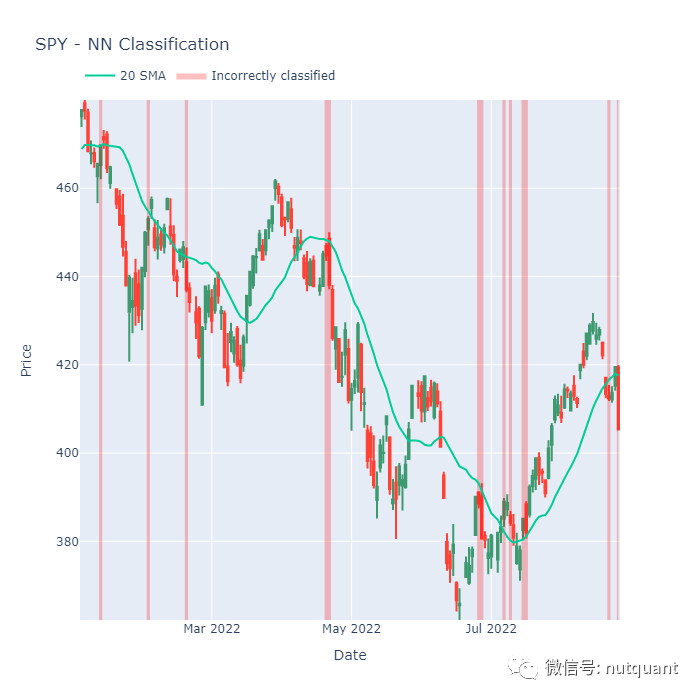
做分类问题?使用混淆矩阵!它将帮助你了解模型预测错误的哪些类别。做回归问题?深入研究差异最大的示例!有时,一个简单的绘图可以代表千言万语,真正帮助你了解模型的弱点。例如,本文中我展示了一个简单的绘图,可视化出哪些分类是错误的。
以下图为例,模型在处理更多的"横向"价格波动方面遇到了困难,那么可能需要增加与梯度相关的特征来改善模型表现。
技巧9: 注意维度灾难
当我们试图在高维特征空间中使用有限数量的数据样本来学习自然状态时,就会出现这种情况。由于每个特征包含一定范围的可能值,因此确保所有值的组合都可以充分地在训练数据中表示变得具有挑战性。但是,通过仔细的特征选择和降维技术,我们可以克服这个障碍,并建立准确有效的模型。