内存的分区

目录
内存分区介绍
区域功能
内存分区运行前后的区别
运行之后(代码区+数据区+未初始化数据区+栈区+堆区)
缓冲区有什么用?
缓冲区的三种类型
缓冲区的刷新
内存分布图
栈与堆的区别
内存分区介绍
我们的内存一般分为四个区域提供使用
且每个区域存放的数据不同,使用效果也不同
它们分别是:堆区、栈区、全局区(静态区)、代码区
而对于一个程序的编译而言
编译程序占用的内存分为以下五个部分 :堆区、栈区、全局区(静态区)、文字常量区、代码区
区域功能
首先我们需要了解一下这几个区的功能:
- 代码区:存放程序的编译后的可执行二进制代码,CPU执行的机器指令,只读
- 文字常量区:存放常量字符串,只读
- 全局区(静态区):存放全局变量,static修饰的全局、局部变量以及static修饰的函数,并且在这里面还分为data区和bss区,可读可写
- 栈区(heap):存放函数的参数值,局部变量的值等,可读可写
- 堆区(stack):允许程序在运行时动态地申请某个大小的内存空间,一般由程序员自己手动释放空间,或者程序结束时由OS(计算机系统)释放空间,可读可写
int a = 0; //存放在全局初始化区
char* p1; //存放在全局未初始化区
int main(){int b;//栈区char s[] = "abc";//栈区char* p2;//栈区char* p3 = "123456";//123456\\0在常量区,p3在栈区。static int c = 0;//全局(静态)初始化区p1 = (char*)malloc(10);p2 = (char*)malloc(20);//分配得来得10和20字节的区域就在堆区。strcpy(p1, "123456");//123456\\0放在常量区,编译器可能会将它与p3所指向的"123456"优化成一个地方。
}
内存分区运行前后的区别
-
运行之前(代码区+数据区+未初始化数据区)
程序运行之前,分为代码区、数据区(data)和未初始化数据区(bss)三个部分
对于代码区(text)而言,他存放了程序在编译时的二进制指令,是共享的,也就意味着所有程序在运行是都需要访问代码区来获取编译指令,也正因为如此,为了使代码区的指令不受改变,从而影响其他程序的编译,代码区是只读的
对于数据区(data)而言,这里存放的是已初始化的全局变量,static修饰的全局、局部变量以及static修饰的函数
对于未初始化数据区(bss)而言,这里存放的是未初始化的全局变量,static修饰的全局、局部变量以及static修饰的函数(初始化数据区的数据在程序开始执行之前被内核初始化为0或者NULL)
而数据区(data)和未初始化数据区(bss)一并存放在全局区(静态区)中 ~
QS:为什么要将程序的指令与程序的数据分开存放?
1.由于程序的指令是所有程序公用的,指令不能被随意修改,所以设为只读,且分开存放可以降低指令被修改的可能性
2.当系统中运行着多个同样的程序的时候,这些程序执行的指令都是一样的,所以只需要内存中保存一份程序的指令就可以了,只是每一个程序运行中数据不一样而已,这样可以节省大量的内存
-
运行之后(代码区+数据区+未初始化数据区+栈区+堆区)
程序运行之后,分为代码区、数据区(data)、未初始化数据区(bss)、栈区和堆区
由于在程序运行之前,就已经分为了代码区,数据区(data)和未初始化数据区(bss),对于这三个区域而言它们的大小都是固定的,程序运行期间不可改变
代码区:此时所有可执行代码段都加载到代码区(不可修改)
数据区:所有已初始化的全局变量,static修饰的全局、局部变量和static修饰的函数存放在此(不可修改)生命周期是直至程序结束
未初始化数据区:所有未初始化的全局变量,static修饰的全局、局部变量和static修饰的函数存放在此(不可修改)生命周期是直至程序结束
栈区:存放函数的参数值、返回值、局部变量等,程序实时调用与释放(函数栈帧的创建与销毁)生命周期是调用期间到释放
堆区:用于动态内存管理分配(空间远大于栈)且没有栈那样先进后出的要求顺序,生命周期是程序员分配到主动释放或者程序结束系统自动释放
缓冲区
缓冲区是内存的一块空间,这块空间用来缓冲输入或输出的数据
缓冲区有什么用?
举一个例子,我们从磁盘中读取1000000数据,若是计算机直接从中读取,这样就会造成两个问题
1.计算机也许无法一口气读取那么多的数据,需要多次读取
2.在读取期间计算机无法做其他事情
为了解决这两个问题,我们可以先将一定量的数据传输到缓冲区中,等到缓冲区存放满以后,再由计算机来读取,这样计算机不仅在数据传输到缓冲区的时候可以处理其他事情,在缓冲区存放完毕以后还可以一口气读取全部数据处理,这样就减少了读取次数,也提高了计算机工作效率
缓冲区的三种类型
1.全缓冲:在这种情况下,当填满标准I/O缓存后才进行实际I/O操作
(全缓冲的典型代表是对磁盘文件的读写)
2.行缓冲:在这种情况下,当在输入和输出中遇到换行符时,执行真正的I/O操作
这时,我们输入的字符先存放在缓冲区,等按下回车键换行时才进行实际的I/O操作
(行缓冲的典型代表是键盘输入数据)
3.不带缓冲:为了使信息更快的显示出来,不进行缓冲操作
(不带缓冲的典型代表是标准出错情况stderr)
缓冲区的刷新
以下这三种情况会刷新清空缓冲区
1.缓冲区满时
2.执行flush语句
3.执行endl语句
4.关闭文件
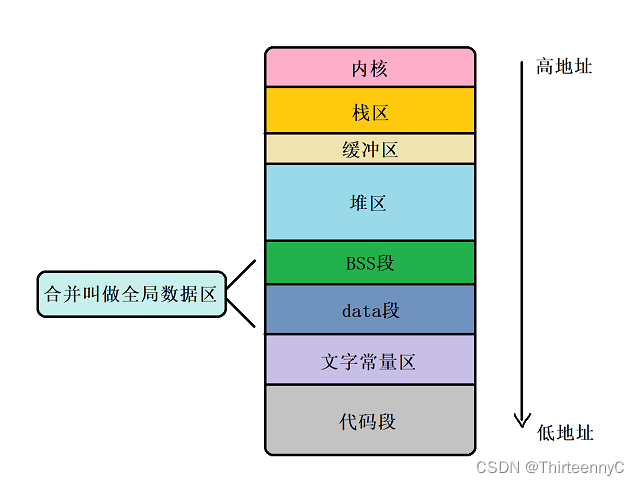
内存分布图
如图所示:
栈与堆的区别
