每日学术速递4.21

CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
1.Pretrained Language Models as Visual Planners for Human Assistance

标题:预训练语言模型作为人工协助的视觉规划器
作者:Dhruvesh Patel, Hamid Eghbalzadeh, Nitin Kamra, Michael Louis Iuzzolino, Unnat Jain, Ruta Desai
文章链接:https://arxiv.org/abs/2304.09302
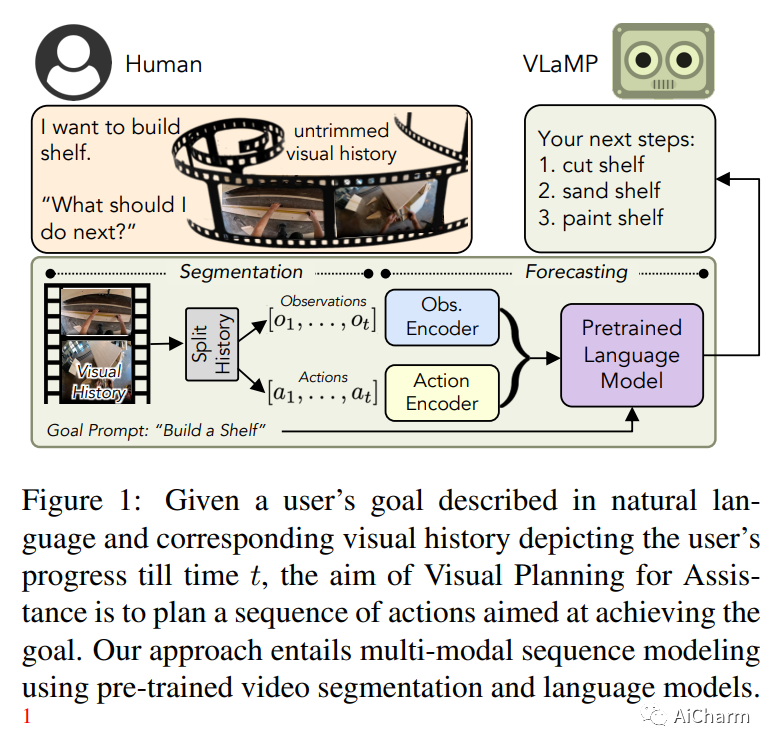
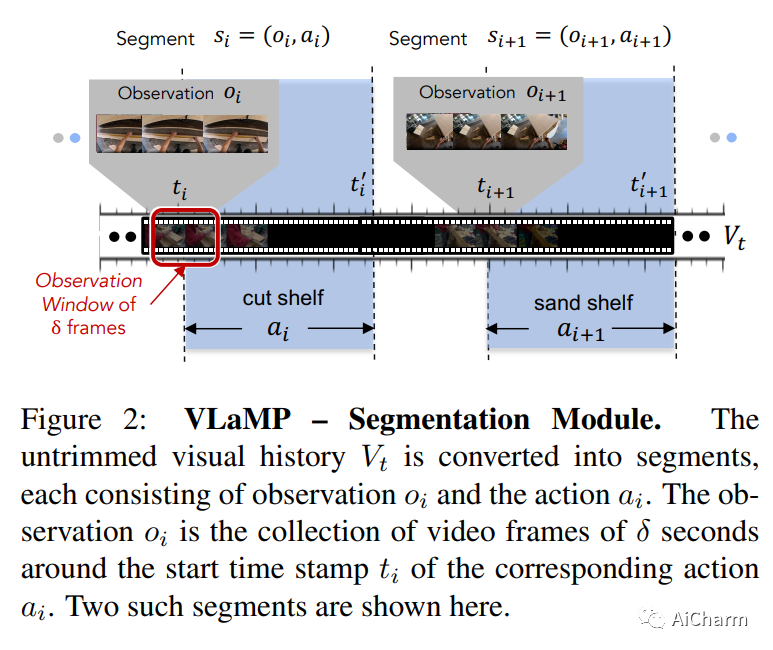
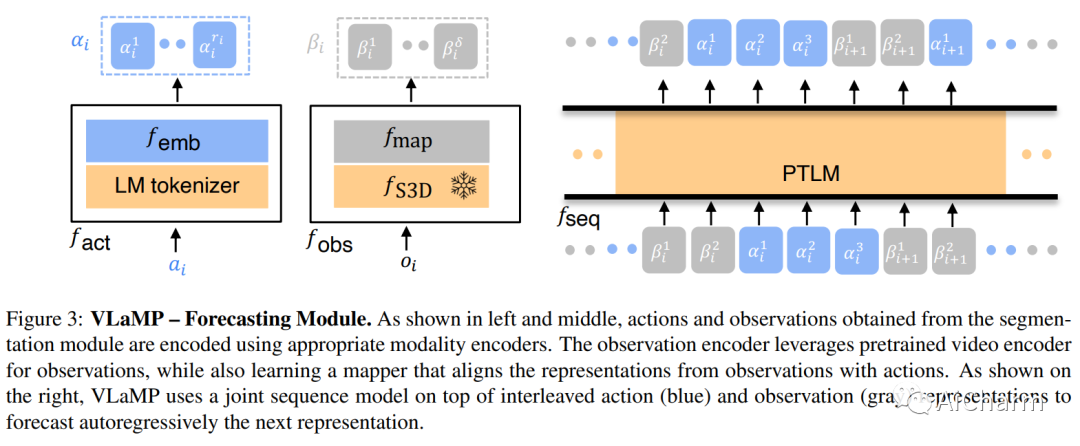
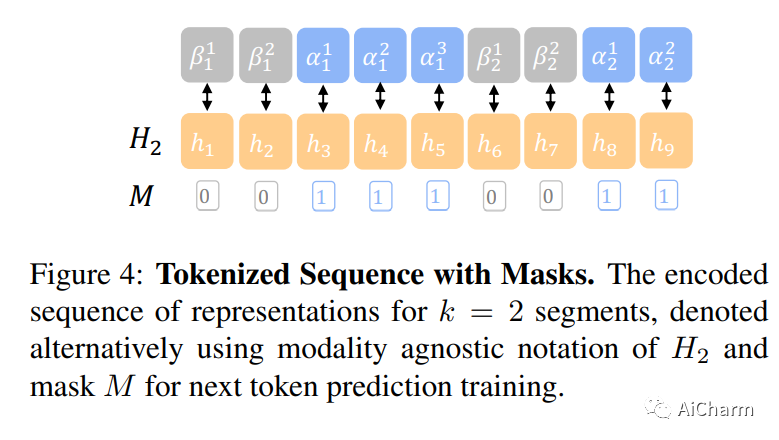
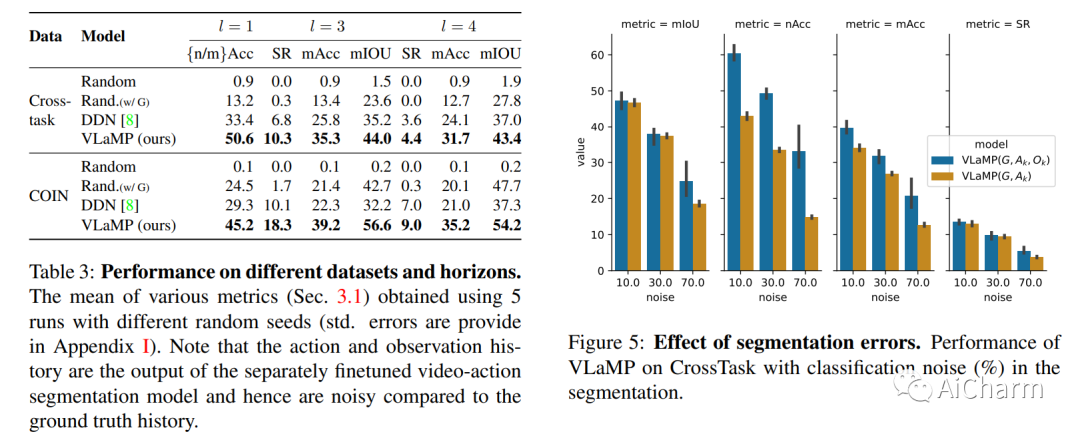
摘要:
为了在可以指导用户实现复杂的多步目标的多模式人工智能助手方面取得进展,我们提出了视觉规划辅助(VPA)任务。给定一个用自然语言简要描述的目标,例如“制作一个架子”,以及到目前为止用户进度的视频,VPA 的目的是获得一个计划,即一系列动作,例如“沙架”, “油漆架”等,达到目的。这需要评估用户未修剪视频的进度,并将其与基本目标的要求相关联,即动作的相关性和它们之间的排序依赖性。因此,这需要处理很长的视频历史记录和任意复杂的动作依赖性。为了应对这些挑战,我们将 VPA 分解为视频动作分割和预测。我们将预测步骤制定为多模态序列建模问题,并提出基于视觉语言模型的规划器 (VLaMP),它利用预训练的 LM 作为序列模型。我们证明 VLaMP 的性能明显优于基线 w.r.t 所有评估生成计划的指标。此外,通过广泛的消融,我们还分离了语言预训练、视觉观察和目标信息对性能的价值。我们将发布我们的数据、模型和代码,以支持未来对视觉规划的研究以提供帮助。
2.NeuralField-LDM: Scene Generation with Hierarchical Latent Diffusion Models(CVPR 2023)

标题:NeuralField-LDM:使用分层潜在扩散模型生成场景
作者:Seung Wook Kim, Bradley Brown, Kangxue Yin, Karsten Kreis, Katja Schwarz, Daiqing Li, Robin Rombach, Antonio Torralba, Sanja Fidler
文章链接:https://arxiv.org/abs/2304.09787
项目代码:https://research.nvidia.com/labs/toronto-ai/NFLDM/

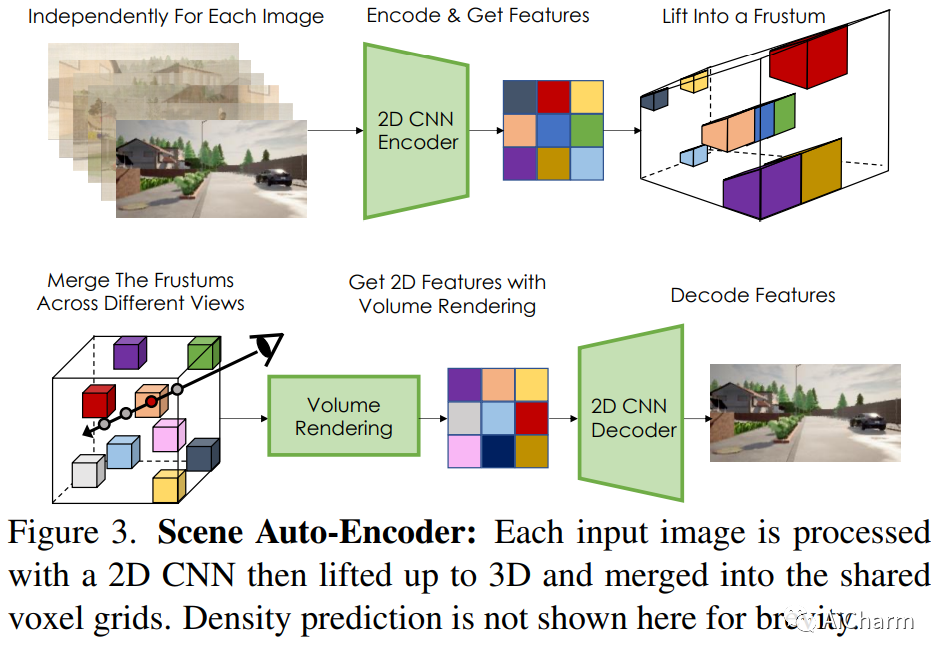
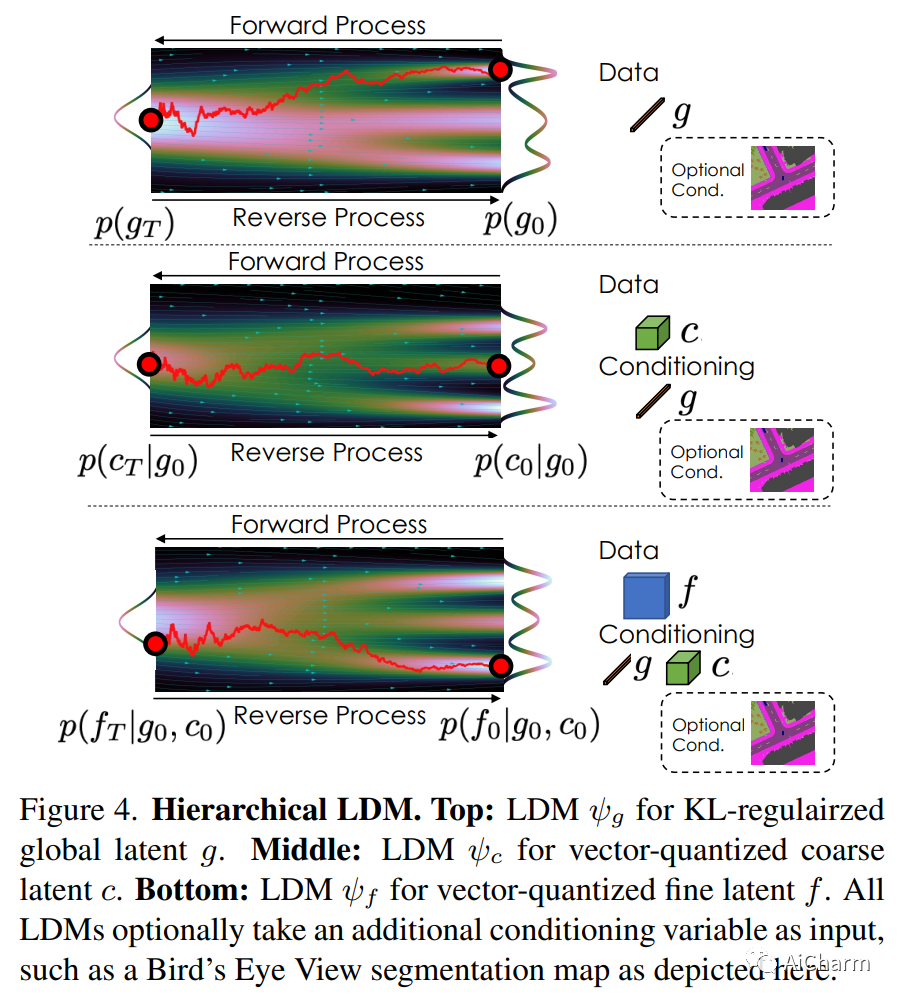
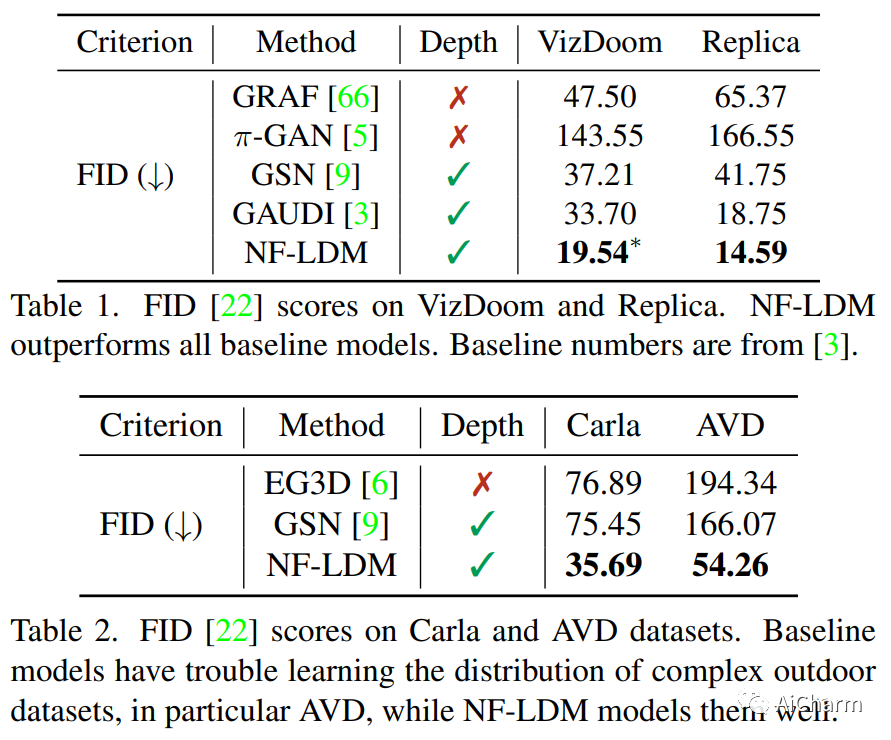
摘要:
自动生成高质量的真实世界 3D 场景对于虚拟现实和机器人模拟等应用具有极大的吸引力。为实现这一目标,我们引入了 NeuralField-LDM,这是一种能够合成复杂 3D 环境的生成模型。我们利用已成功用于高效高质量 2D 内容创建的潜在扩散模型。我们首先训练场景自动编码器将一组图像和姿势对表示为神经场,表示为密度和特征体素网格,可以投影这些网格以产生场景的新视图。为了进一步压缩这种表示,我们训练了一个潜在的自动编码器,它将体素网格映射到一组潜在的表示。然后将层次扩散模型拟合到潜在以完成场景生成管道。我们实现了对现有最先进场景生成模型的实质性改进。此外,我们还展示了 NeuralField-LDM 如何用于各种 3D 内容创建应用程序,包括条件场景生成、场景修复和场景样式操作。
3.Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models

标题:Chameleon:使用大型语言模型进行即插即用的组合推理
作者:Pan Lu, Baolin Peng, Hao Cheng, Michel Galley, Kai-Wei Chang, Ying Nian Wu, Song-Chun Zhu, Jianfeng Gao
文章链接:https://arxiv.org/abs/2304.05977
项目代码:https://chameleon-llm.github.io/
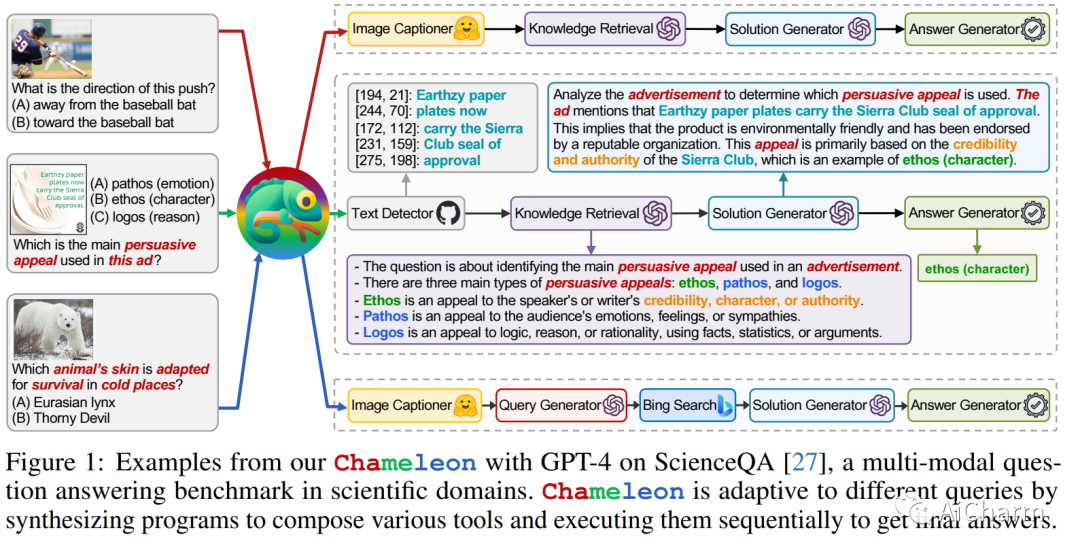
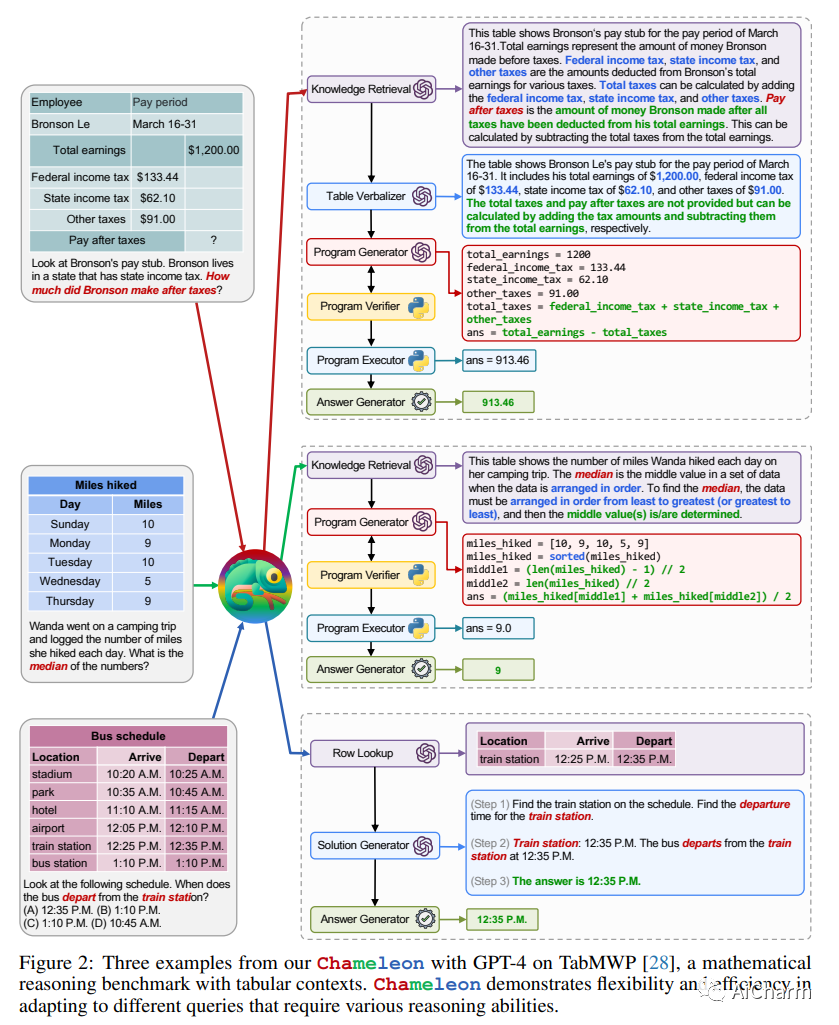
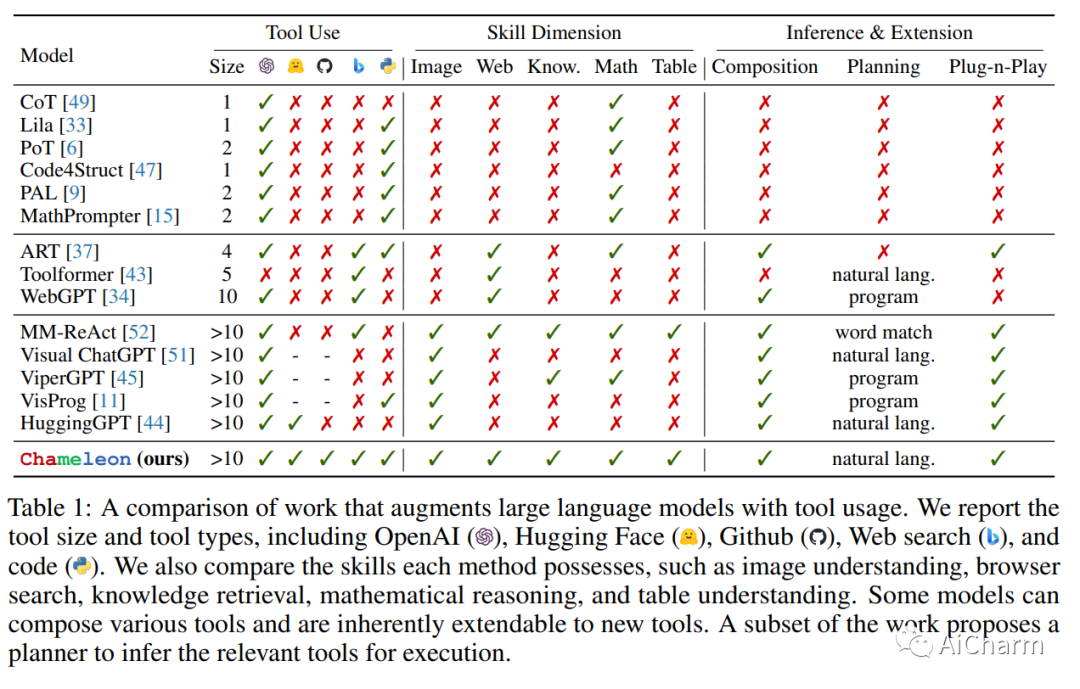
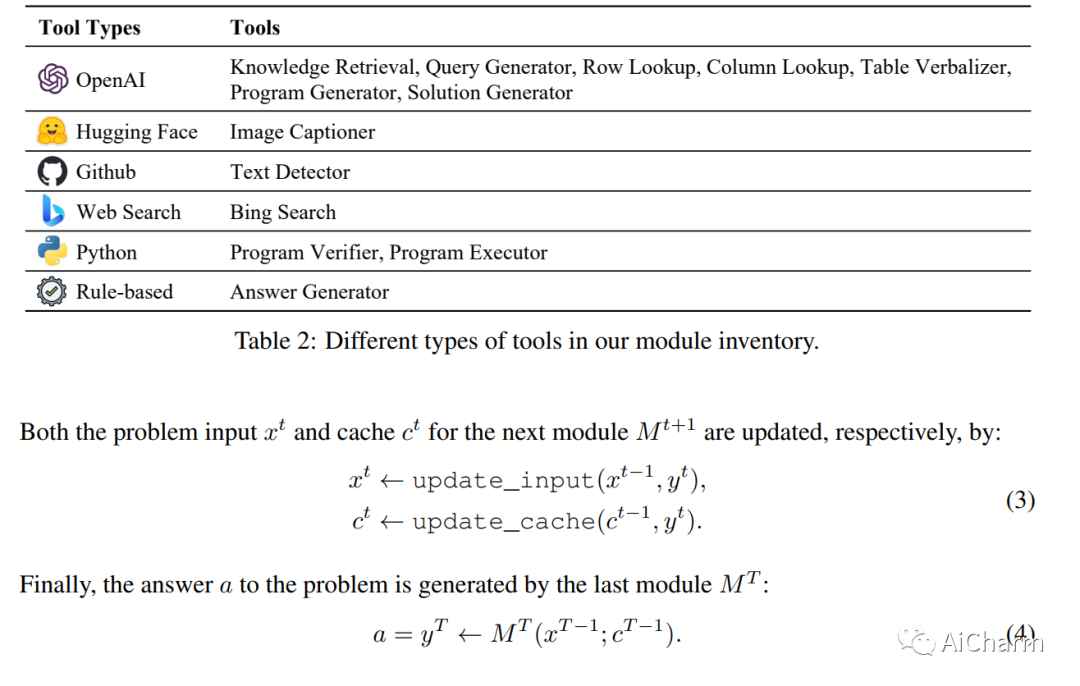
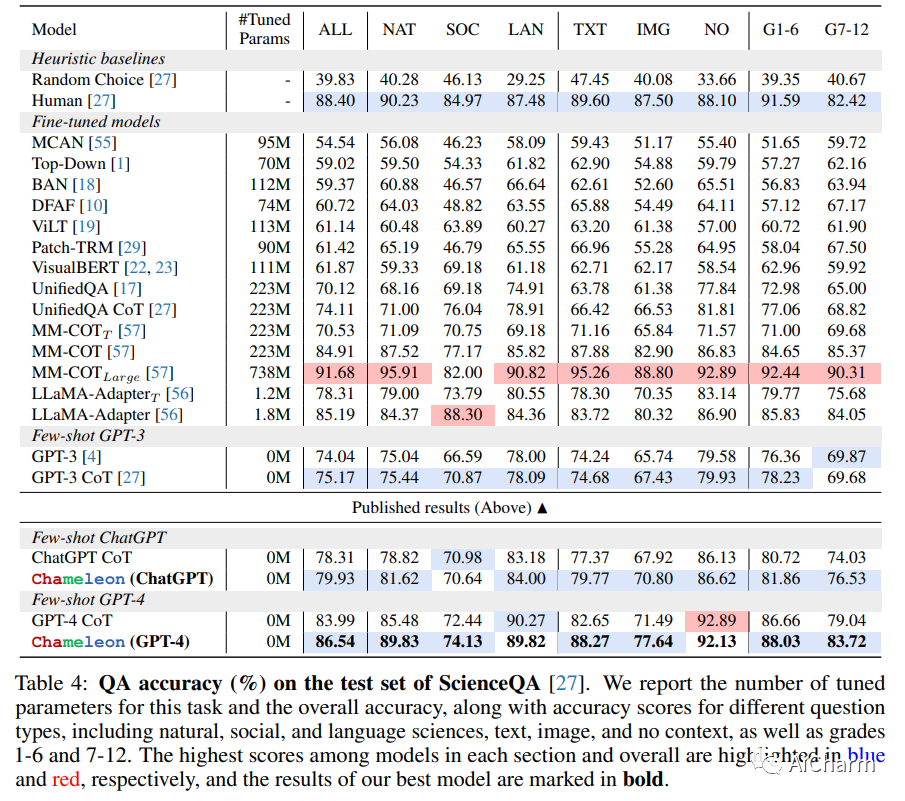
摘要:
大型语言模型(LLM)在各种具有涌现能力的自然语言处理任务中取得了显着进步。然而,他们面临着固有的局限性,例如无法访问最新信息、无法使用外部工具或进行精确的数学推理。在本文中,我们介绍了 Chameleon,这是一种即插即用的组合推理框架,可增强 LLM 以帮助应对这些挑战。Chameleon 综合程序以组成各种工具,包括 LLM 模型、现成的视觉模型、网络搜索引擎、Python 函数和根据用户兴趣定制的基于规则的模块。Chameleon 建立在 LLM 之上作为自然语言规划器,推断出适当的工具序列来组合和执行以生成最终响应。我们展示了 Chameleon 在两个任务上的适应性和有效性:ScienceQA 和 TabMWP。值得注意的是,带有 GPT-4 的 Chameleon 在 ScienceQA 上达到了 86.54% 的准确率,比已发表的最好的 few-shot 模型显着提高了 11.37%;使用 GPT-4 作为底层 LLM,Chameleon 比最先进的模型提高了 17.8%,从而在 TabMWP 上实现了 98.78% 的整体准确率。进一步的研究表明,与 ChatGPT 等其他 LLM 相比,使用 GPT-4 作为规划器表现出更加一致和合理的工具选择,并且能够根据指令推断出潜在的约束。
更多Ai资讯:公主号AiCharm