初识NoSQL(一文读懂)

最近参加了Oracle的数据库培训,对NoSQL非常好奇,总结一下关于NoSQL的认识。
- NoSQL是Not Only SQL,并不是去除掉SQL,泛指非关系型的数据库。
- 关系,指关系模型,具体指同一个对象在不同属性上的值 以及 不同对象在相同属性上的值是与关系的,这里的关系不仅指数值关系(大于、小于、相同)也包括业务关系(比如需要做联合查询)
为什么要引入NoSQL
原因一:传统的关系型数据库(SQL)在某些场景下无法适用,或者说支持不足。
关系型数据库与结构化数据的匹配较好,可以采用类似于二维表格的形式进行数据存储。结构化数据指的是由二维表结构来逻辑表达和实现的数据,严格遵循数据格式与长度规范,也称作为行数据,特点为:数据以行为单位,一行数据表示一个实体的信息,每一行数据的属性是相同的。例如:

对于非结构化数据,数据结构不规则或不完整,没有任何预定义的数据模型,不方便用二维逻辑表来表现的数据,例如办公文档(Word)、文本、图片、HTML、各类报表、视频音频等。
以及半结构化数据(介于结构化与非结构化数据之间的数据),它是结构化数据的一种形式,虽然不符合二维逻辑这种数据模型结构,但是包含相关标记,用来分割语义元素以及对记录和字段进行分层。常见的半结构化数据有XML和JSON,例如:

非结构化数据和半结构化数据使用关系型数据库非常麻烦,无法填充二维表格或无法完全填充。
原因二:关系型数据库的缺点。
- 高并发下IO压力大:只要操作(读/写)某个具体值,就需要把整行都读入内存。
- 维护索引代价高:插入和修改数据需要更新涉及到的全部索引,降低读写能力,索引越多读写能力越差占用空间也大。
- 维护数据一致性代价高:
- 为维护数据一致性付出的代价大:采用锁机制控制并发,SQL中的不同隔离级别带来了复杂的运算处理,降低读写能力。
- 水平扩展容易产生问题:分库分表后需要跨库跨表查询,做分布式事务处理比较麻烦。
- 表结构不易扩展:表结构是固定的,新增和删除操作影响整张表,需要锁表。
- 搜索功能弱:对于搜索关键字需进行完整精确匹配,不支持分词。
关系型数据库遵循ACID规则(原子性、一致性、独立性、持久性),在高并发时存在性能瓶颈,容易出现数据库CPU高、Sql执行慢、客户端报数据库连接池不够等情况。因此超大规模数据的存储通常需要使用NoSQL。
NoSQL的特点
优点:
- - 高可扩展性
- - 分布式计算
- - 低成本
- - 架构的灵活性,半结构化数据
- - 没有复杂的关系
缺点:
- - 没有标准化
- - 有限的查询功能(到目前为止)
- - 最终一致是不直观的程序
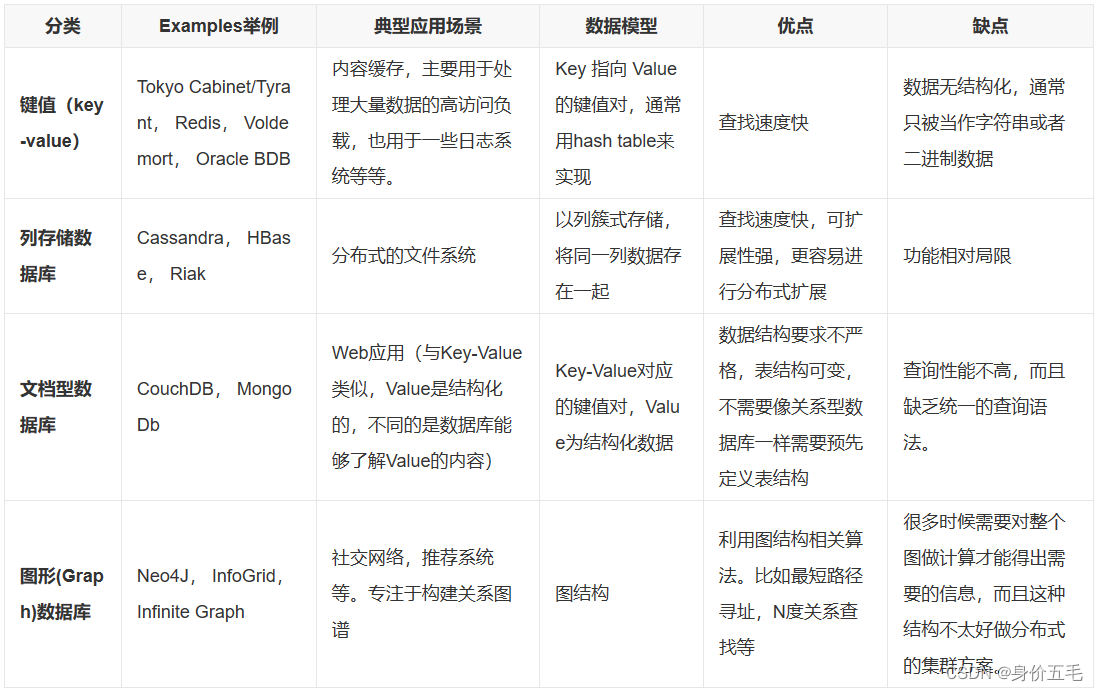
常见的NoSQL类型
主要包括:键值(Key-Value)存储数据库、列存储数据库、文档型数据库、图形(Graph)数据库。
什么时候使用NoSQL
关系型数据库与非关系型数据库的选择需要考虑两点:
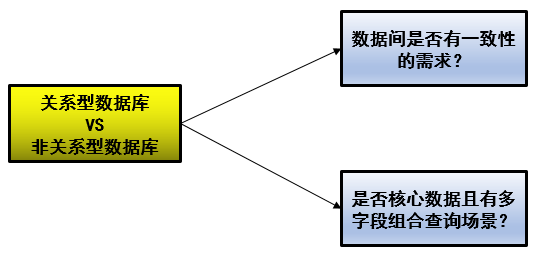
第一点,非关系型数据库都是通过牺牲了ACID特性来获取更高的性能的,假设两张表之间有比较强的一致性需求,那么这类数据是不适合放在非关系型数据库中的。
第二点,核心数据不走非关系型数据库,例如用户表、订单表,但是这有一个前提,就是这一类核心数据会有多种查询模式,例如用户表有ABCD四个字段,可能根据AB查,可能根据AC查,可能根据D查,假设核心数据,但如果是个KV形式,比如用户的聊天记录,那就需要使用NoSQL。
通常情况下,非核心数据尤其是日志、流水一类中间数据必须使用非关系型数据库,以及具有写远高于读和写入量巨大这两个特点的数据也需要使用NoSQL。这类数据一旦使用关系型数据库作为存储引擎,将大大降低关系型数据库的能力,正常读写QPS不高的核心服务会受这一类数据读写的拖累。
目前,谷歌和Facebook每天都需要为他们的用户收集万亿比特的数据,包括用户的个人信息,社交网络,地理位置,用户生成的数据和用户操作日志等,这些数据存储不需要固定的模式,采用NoSQL以便于横向扩展。此外,Mozilla、Adobe和LinkedIn也都广泛使用了NoSQL。
参考资料(引用)
博客园:https://www.cnblogs.com/xrq730/p/11039384.html(非常经典、强烈推荐)
菜鸟教程:https://www.runoob.com/mongodb/nosql.html
百度百科:https://baike.baidu.com/item/%E5%85%B3%E7%B3%BB%E5%9E%8B%E6%95%B0%E6%8D%AE%E5%BA%93/8999831