15-721 Chapter9 数据压缩

Background
disk database的瓶颈在disk IO上的话(也就是说数据压缩的好处很大,可以比较放心的做),那么内存数据库的瓶颈是多方面的,其中包含cpu。所以我们要在计算量和压缩率(DRAM还是有点贵的,同时减少数据量也有利于计算和带宽什么的)上做一个trade off也就是本节的主要目的。
数据是无序的,但是相同的属性上又有相关性,对于列存数据库来说可以利用数据特点来优化
压缩原则

数据跳跃优化
取样估计不精确会导致lossy,如果用zone maps维护一张表的话,就可以精确的跳过


MySQL的压缩,对于mod log的压缩页,我们直接update他就行了,想bw树记录delta一样,因为第一个看到的就是最新的。

压缩策略
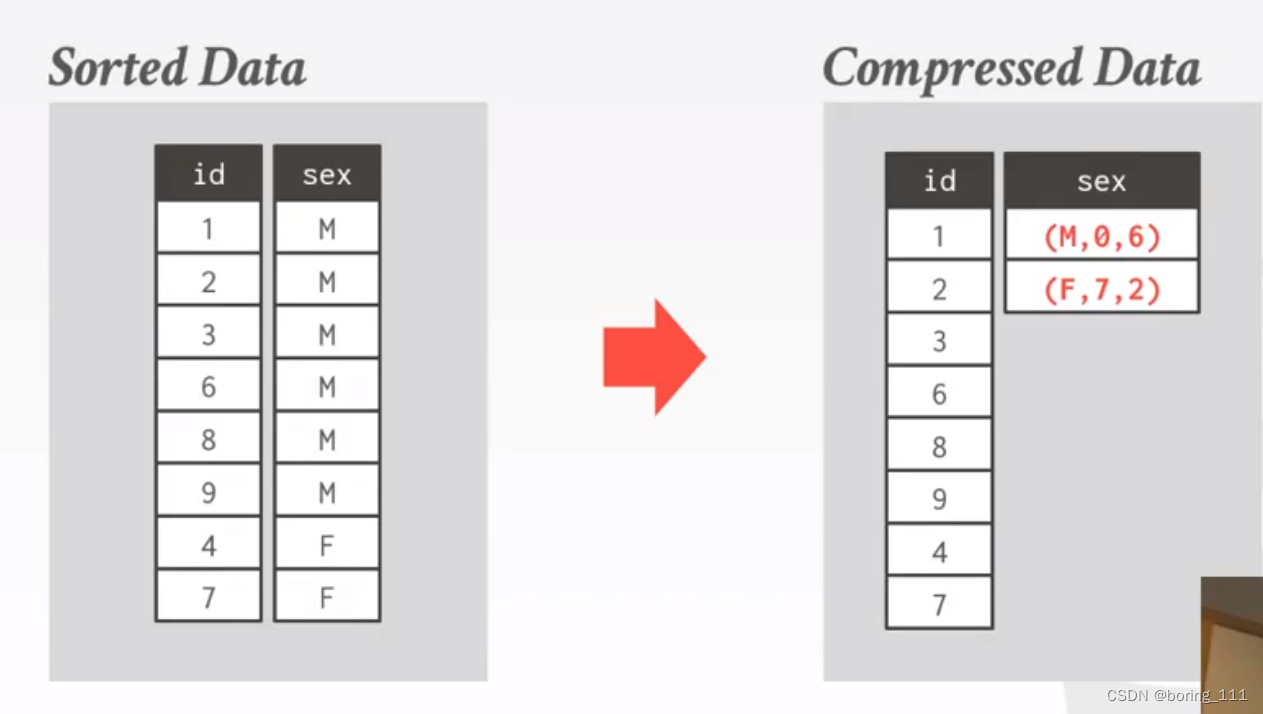
压缩空值(压缩重复值的特例):
记录空值的位置和数量,(NULL, dataoffset, num)
同时如果我们减其排序,我们将会节约更多的内存
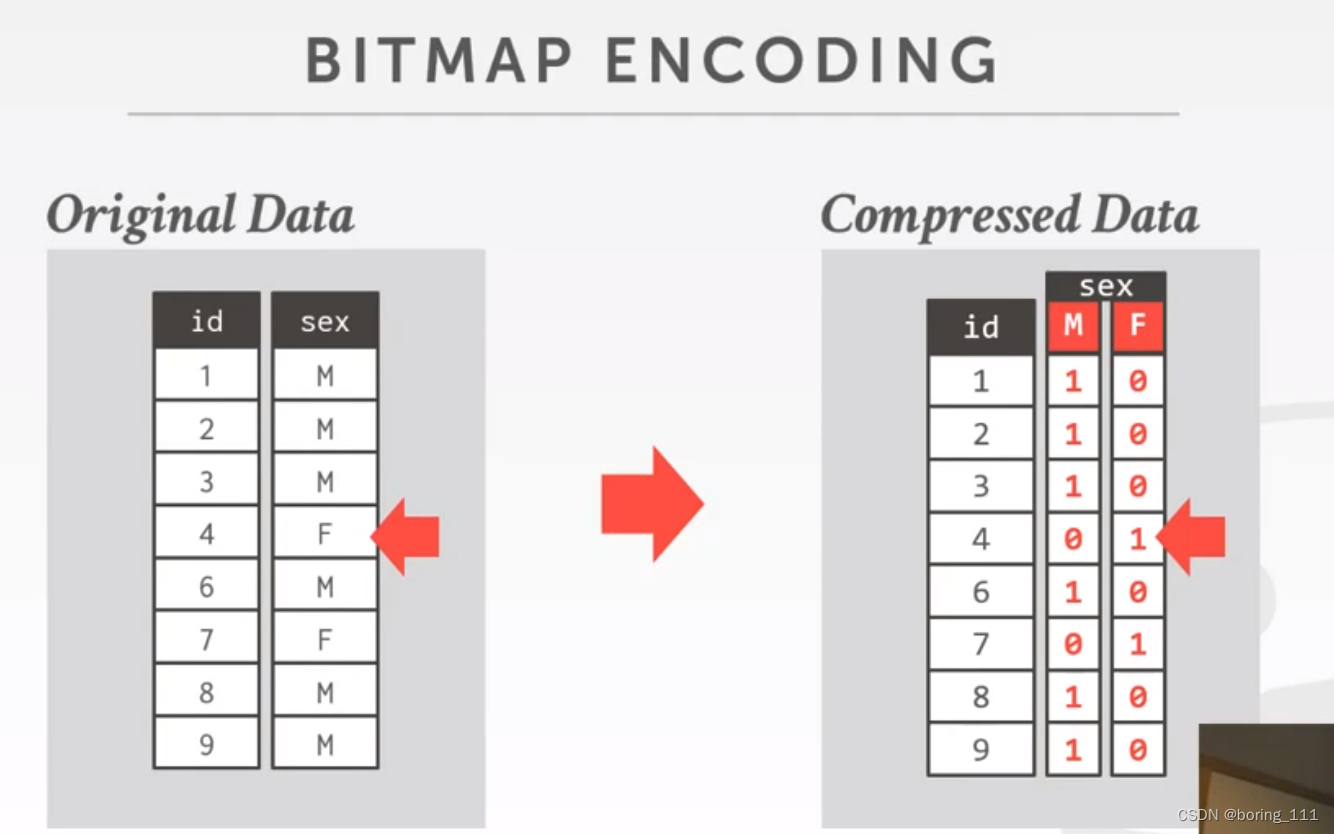
Bit map:
对于每个属性做个bitmap,时间上有点像用一个bit来代替原来的类型大小,但是如果属性太多的话,就得不偿失。
oracle BBC
就是记录一下按byte记录一下全0和有1的byte,对于0多的情况做一个优化。

比如我们010就是第一行有两个byte全0,然后1的话就是只有一个1在一个byte里面 ,就变1,最后是1在byte里面的位置,也就是4
然后如果我们我们第一个位置不能表示非0的大小的话,就设为111,然后后面00001101来作为大小。

存delta change
我们存的是变化,对于时间这样的东西变化都是缓慢的,很适合。

大多数尺寸
就是对于一些特别的大value的话,做个标记,然后去offset value表里面去查

字典压缩
字典的建立有两种策略。

字典需要可以在压缩后和压缩前的值之间相互查找,可惜的是没有hash function 能做到

压缩后的东西需要和之前一样的排序。比如下面这个查询。

字典的数据结构
第一个:数组
offset就是压缩后的值,然后就是更新太慢了。
第二个:
hahs table,单点快,range慢
第三个
B+树,内存占用多,就是中间节点这些,然后可以支持前缀查询(like andy%)和范围查询

B+树可以做成这样,是挺秀的,decode和encode的中间节点不同,但是存的值都是相同的。这样可以少存一份叶子节点,同时一致性的问题也没了。
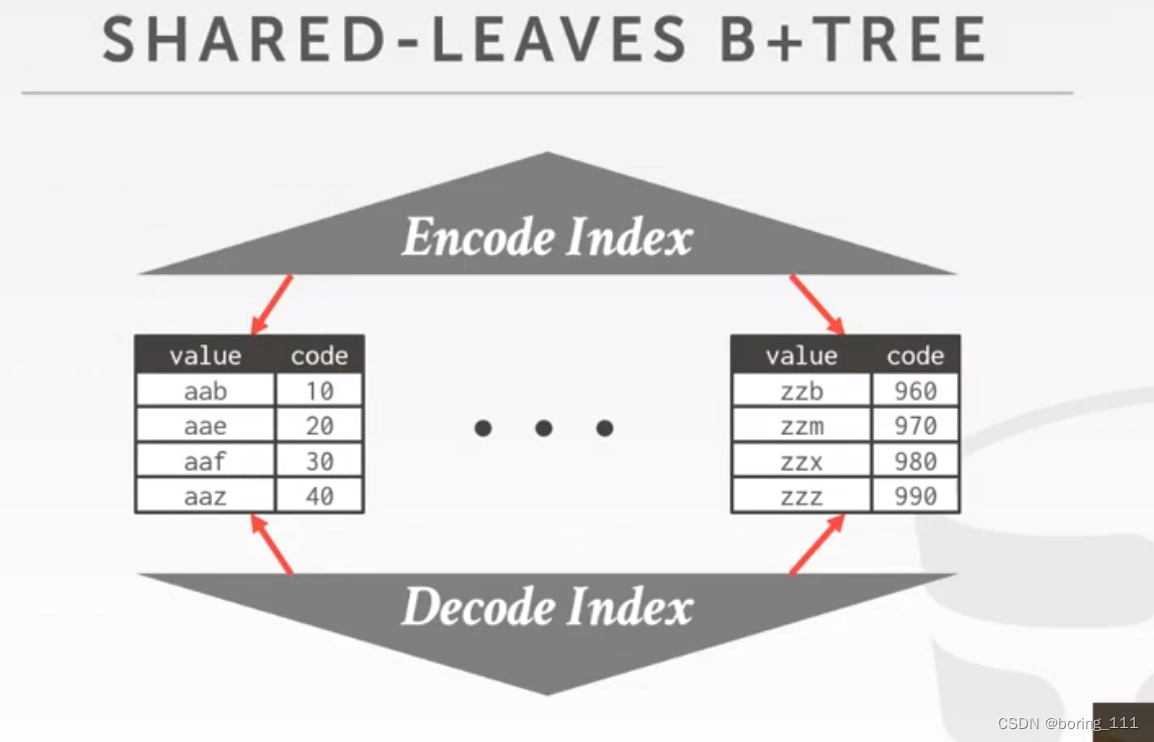
B+树压缩
1.节点空的entry
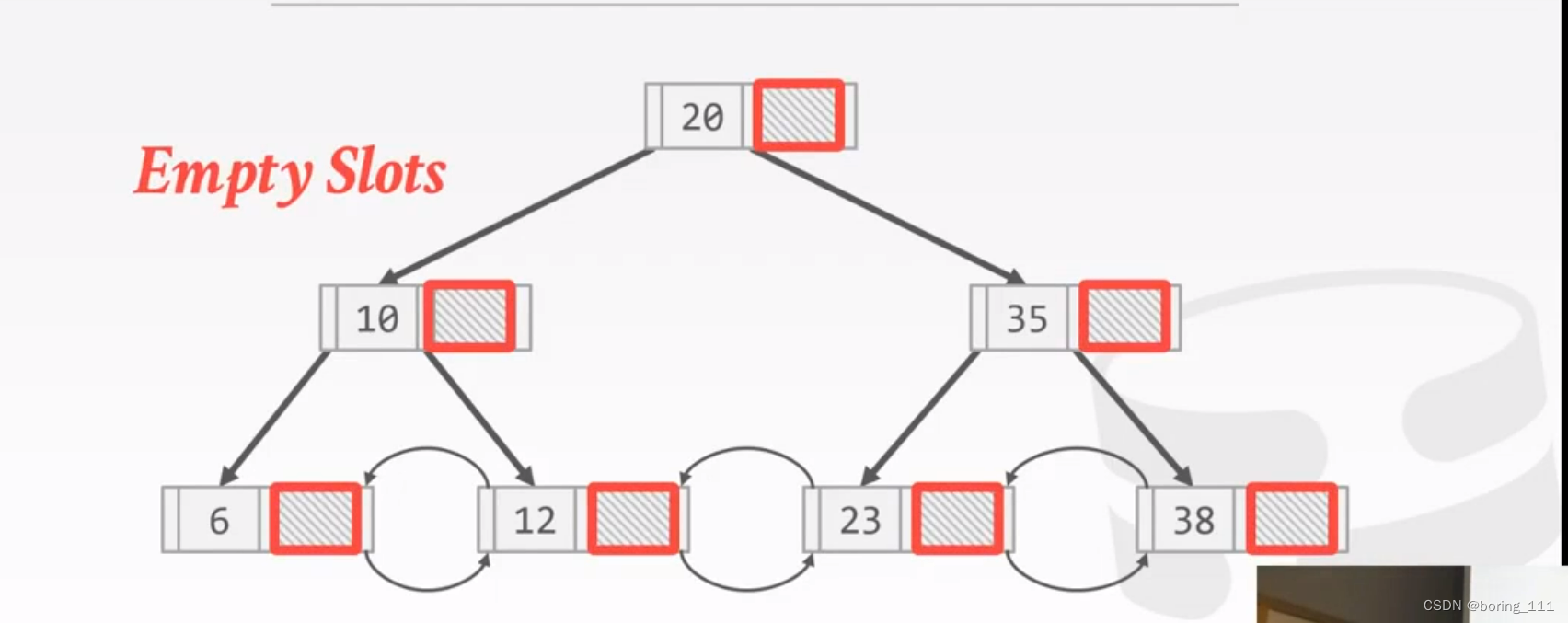
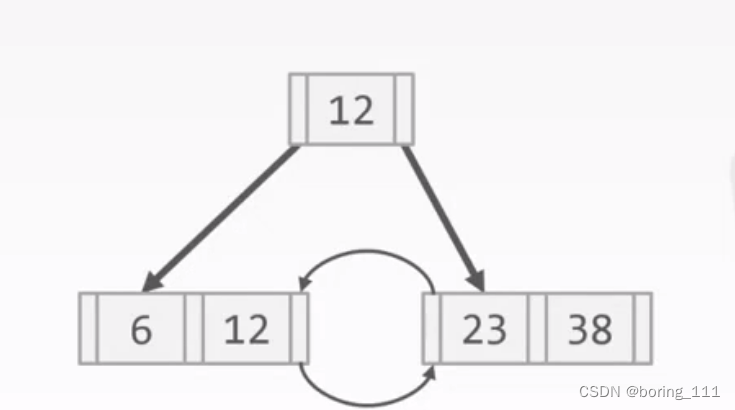
2.pointer变offset
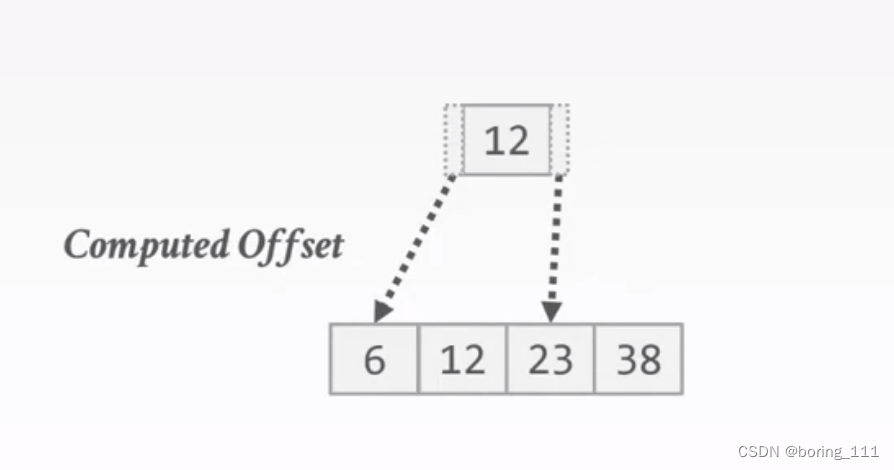
Summary
