day19_Set

今日内容
零、 复习昨日
一、作业
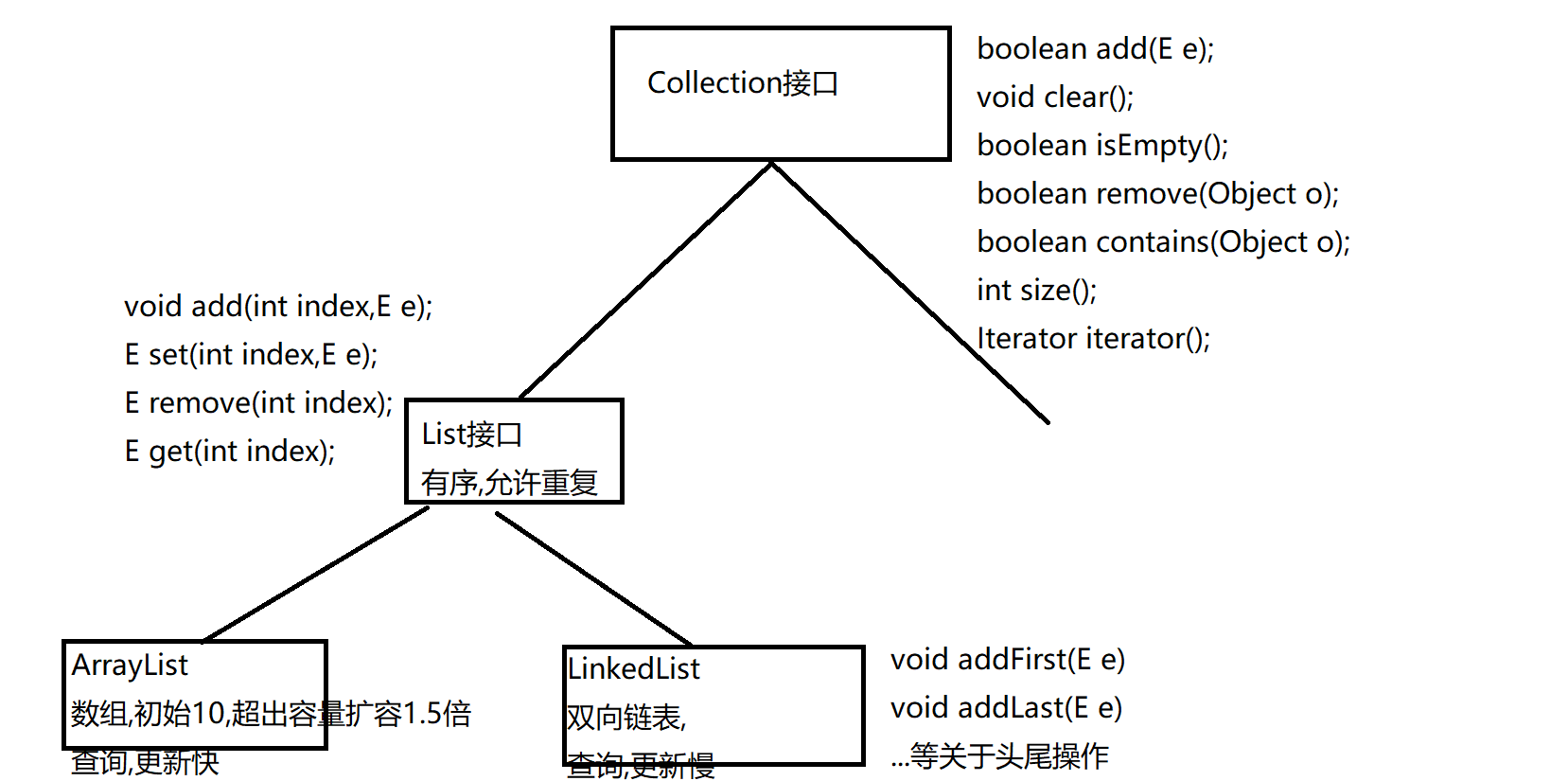
二、Set
三、HashSet[重点]
四、LinkedHashSet
五、TreeSet[难点,熟悉]
六、Collections
零、 复习昨日
一、作业
见代码
二、Set
Set是Collection集合的子接口,主要特性是
不允许重复元素Set接口中的操作集合的API与Collection中一模一样
Set接口有两个主要的实现类:HashSet,TreeSet
三、HashSet[重点]
HashSet类实现了Set接口,也是
不允许重复元素HashSet集合底层是HashMap,存储的元素
无序,无序是指迭代顺序和插入顺序不一致不保证线程安全,线程不同步
3.1 方法演示
构造方法
HashSet()构造一个新的空 set,其底层 HashMap 实例的默认初始容量是 16,加载因子是 0.75。HashSet(Collection<? extends E> c)构造一个包含指定 collection 中的元素的新 set- HashSet(int initialCapacity) 构造一个新的空 set,其底层 HashMap 实例具有指定的初始容量和默认的加载因子(0.75)。
- HashSet(int initialCapacity, float loadFactor) 构造一个新的空 set,其底层 HashMap 实例具有指定的初始容量和指定的加载因子。
方法
HashSet类中的方法与父接口Set接口中的方法一致,即又跟Collection接口中方法一致
package com.qfset;import java.util.HashSet;
import java.util.Iterator;/* --- 天道酬勤 --- @author QiuShiju* @desc*/
public class TestHashSet {public static void main(String[] args) {// 创建HashSet集合HashSet<Integer> set = new HashSet<>( );// 存储元素boolean add1 = set.add(11);boolean add2 = set.add(21);boolean add3 = set.add(13);boolean add32 = set.add(13);// 重复元素会添加失败,返回falseboolean add4 = set.add(24);System.out.println(add1 );System.out.println(add2 );System.out.println(add3 );System.out.println(add32 );System.out.println(add4 );// 打印的顺序是随机,无法预测,没有排序也不是插入顺序System.out.println(set );// 之后要看看是否去重,顺序?// 其他方法(判断,大小,删除)// ...// 迭代(标准语法,foreach)Iterator<Integer> iterator = set.iterator( );while (iterator.hasNext( )) {System.out.println(iterator.next( ));}System.out.println("-------------" );for(Integer i : set) {System.out.println(i);}}
}
3.2 扩容机制[面试]
HashSet底层是Hash表,其实是HashMap
默认初始容量16,加载因子0.75 —> 扩容的阈值= 容量 * 因子 = 16 * 0.75 = 12
即超过12个元素时就要触发扩容,扩容成原来的2倍(ps: 初始容量和加载因子是可以通过构造方法创建时修改的…)
3.3 去重原理[面试]
练习1: 将学生存储到HashSet集合中,如果属性一致则去重
- 调用add(E e)方法时,会在底层调用元素e的hashcode方法来获得对象的地址值
- 如果地址值不一样,直接存储
- 如果地址值一样时,会再调用元素的equals方法判断元素的内容是否一样
- 如果equals为false,那么存储 但是如果equals判断值为true,那么去重
总结: 以后只需要使用工具生成hashcode和equals就可以再HashSet中去重!
package com.qf.set;import java.util.HashSet;/* --- 天道酬勤 --- @author QiuShiju* @desc*/
public class TestHashSet2 {public static void main(String[] args) {/* 先调用hashcode比较地址* 如果hashcode不一致,则直接存储* 如果hashcode一致,再调用equals比较属性* equals比较后一致,不存储,即去重* equals比较后不一致,存储*/HashSet<Student> set = new HashSet<>( );set.add(new Student(18,"张三"));System.out.println("------------------" );set.add(new Student(18,"张三"));System.out.println("------------------" );set.add(new Student(19,"李四"));System.out.println("------------------" );set.add(new Student(19,"李四"));System.out.println("------------------" );set.add(new Student(20,"王五"));System.out.println("------------------" );for (Student student : set) {System.out.println(student );}}
}
// Student类要重写hashcode和equals
package com.qf.set;import java.util.Objects;public class Student {private int age;private String name;@Overridepublic boolean equals(Object o) {System.out.println("equals()...." );if (this == o) return true;if (o == null || getClass( ) != o.getClass( )) return false;Student student = (Student) o;return age == student.age && Objects.equals(name, student.name);}@Overridepublic int hashCode() {return Objects.hash(age, name);}// setget toString 构造...
}
四、LinkedHashSet
LinkedHashSet 既有Set的
去重的特性,又有Linked结构有序的特性,即
存储在LinkedHashSet 中的元素既不允许重复,又能保证迭代顺序
public static void main(String[] args) {LinkedHashSet<Integer> lhs = new LinkedHashSet<>( );lhs.add(211);lhs.add(111);lhs.add(111);lhs.add(44);lhs.add(44);lhs.add(23);System.out.println(lhs );}
五、TreeSet[难,熟悉]
TreeSet是基于
TreeMap的NavigableSet的实现.
可以使用元素的自然顺序对元素进行排序或者根据创建 TreeSet 时提供的Comparator进行排序,具体取决于使用的构造方法即TreeSet会对存储的元素排序,当然也会去重!
5.1 方法演示
构造方法
- TreeSet()构造一个新的空 set,该 set 根据其元素的
自然顺序进行排序。- TreeSet(Comparator<? super E> comparator) 构造一个新的空 TreeSet,它根据指定比较器进行排序。
方法
有常规的集合的方法(add,remove,Iterator,size等等),还有一些基于树结构能排序的特性才有的特殊方法,例如范围取值的(ceiling(),floor(),lower(),higher(),首尾取值(),first(),last()…)等操作
public class TestTreeSet {public static void main(String[] args) {// 创建TreeSet集合TreeSet<Integer> set = new TreeSet<>( );// 添加元素set.add(18);set.add(19);set.add(20);set.add(20);// 会去重set.add(17);set.add(16);set.add(21);// 结果会排序,按照元素的自然顺序System.out.println(set );// 取出排序后第一个Integer first = set.first( );System.out.println(first );// 取出排序后最后一个System.out.println(set.last( ));// 返回集合中大于等于给定元素的最小元素Integer ceiling = set.ceiling(18);System.out.println(ceiling );// 返回集合中小于等于给定元素的最大元素System.out.println(set.floor(18));// 返回集合中严格大于给定元素的最小元素System.out.println(set.higher(18) );}
}
5.2 去重排序原理
通过下方的练习,默认的排序是实现Comparable接口,实现该接口的类会进行自然排序.
前提知识: TreeSet底层是TreeMap,TreeMap是红黑树,是一种平衡二叉树(AVL)
练习1:新建User类(age,name),创建TreeSet集合,创建多个User对象,将user对象存入TreeSet集合,实现去重排序,1) 年龄和姓名一致则去重 2) 按照年龄从小到大排序
package com.qf.set;
public class User implements Comparable<User> {private String name;private int age;// ... set get toString 构造/* 当前正在存储的对象小于之前存储过的对象 负整数,放树杈左边* 当前正在存储的对象等于之前存储过的对象 零,不存储* 当前正在存储的对象大于之前存储过的对象 正整数放树杈右边* 取值时从根节点开始按照左中右取值*/@Overridepublic int compareTo(User o) {System.out.println("this --> " + this );System.out.println("o --> " + o );return o.getAge() - this.age;}
}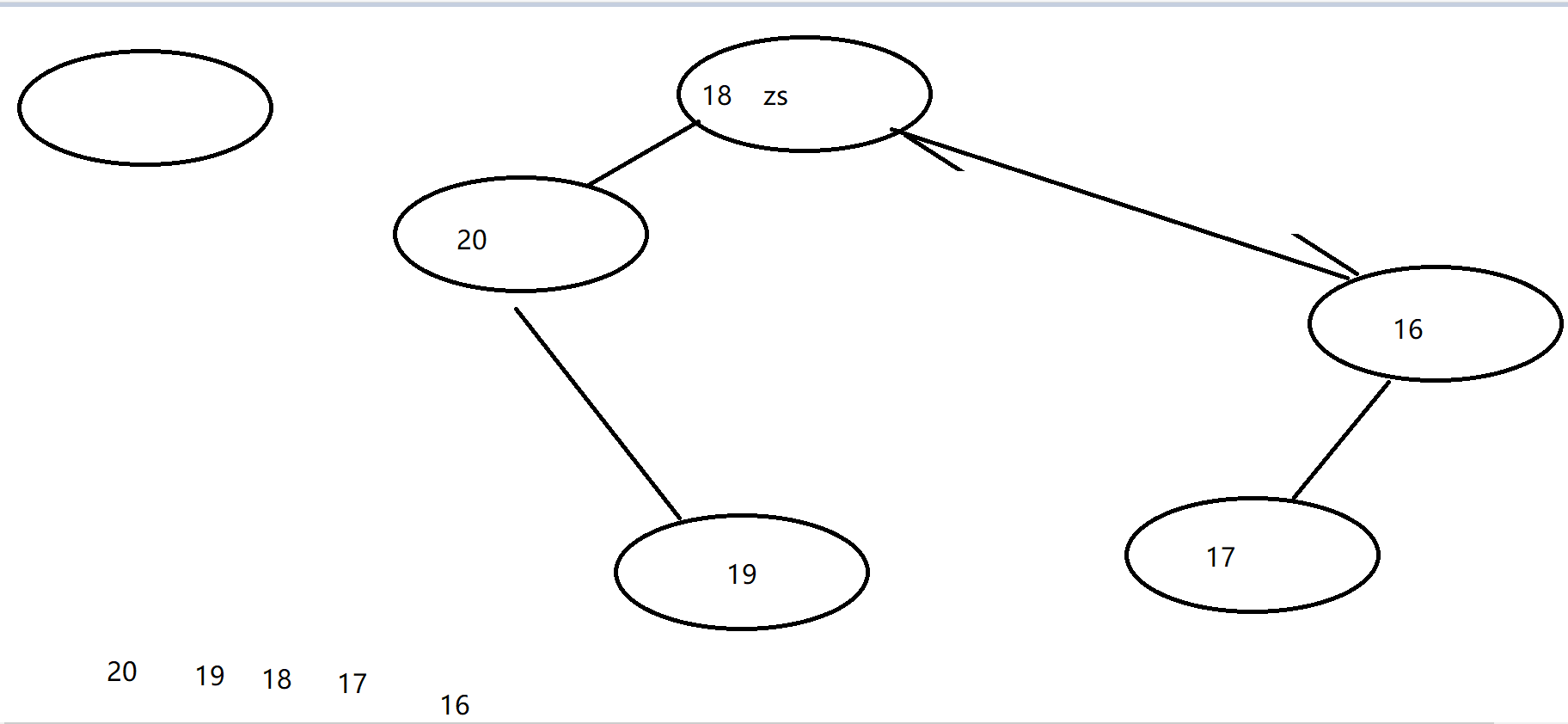
// 1) 年龄和姓名一致则去重 2) 按照年龄从小到大排序@Overridepublic int compareTo(User o) {System.out.println("this --> " + this );System.out.println("o --> " + o );if (this.age == o.getAge() && this.name.equals(o.getName())) {return 0;// 返回0则去重}if (this.age - o.getAge() <= 0 ) {return -1;// 返回负数则放左边} else {return 1; // 返回正数则放右边}}
5.3 练习
需求:创建 5个老师信息(姓名,语文成绩,数学成绩,英语成绩),放入TreeSet集合,输出时按照总分从高到低输出到控制台
public class Teacher implements Comparable<Teacher>{private String name;private int yuwen;private int shuxue;private int yingyu;// set get toString 构造...@Overridepublic int compareTo(Teacher o) {return o.getSum() - this.getSum();}
}
六、总结
Set 集合不允许重复元素
HashSet 无序,遍历顺序和插入顺序不一致
TreeSet 排序,按照元素的自然顺序
今天这些集合API昨天已经学过,就是基本的集合操作(创建,添加元素,遍历)
背住,理解,能说的