Spark大数据处理学习笔记(2.2)搭建Spark Standalone集群

该文章主要为完成实训任务,详细实现过程及结果见【http://t.csdn.cn/DrziJ】
文章目录
- 一、在master虚拟机上安装配置Spark
-
- 1.1 将spark安装包上传到master虚拟机
- 1.2 将spark安装包解压到指定目录
- 1.3 配置spark环境变量
- 1.4 编辑spark环境配置文件
- 1.5 创建slaves文件,添加从节点
- 二、在slave1虚拟机上安装配置Spark
-
- 2.1 把master虚拟机上安装的spark分发给slave1虚拟机
- 2.2 将master虚拟机上环境变量配置文件分发到slave1虚拟机
- 2.3 在slave1虚拟机上让spark环境配置文件生效
- 三、在slave2虚拟机上安装配置Spark
-
- 3.1 把master虚拟机上安装的spark分发给slave2虚拟机
- 3.2 把master虚拟机上环境变量配置文件分发到slave2虚拟机
- 3.3 在slave2虚拟机上让spark环境配置文件生效
- 四、启动Spark Standalone集群
-
- 4.1 启动hadoop的dfs服务
- 4.2 启动Spark集群
- 五、访问Spark的WebUI
- 六、启动Scala版Spark Shell
- 七、提交Spark应用程序
-
- 7.1 提交语法格式
- 7.2 spark-submit常用参数
- 7.3 案例演示 - 提交Spark自带的圆周率计算程序
-
-
- (1)Standalone模式,采用client提交方式
- (2)Standalone模式,采用cluster提交方式
-
- 八、停止Spark集群服务
一、在master虚拟机上安装配置Spark
1.1 将spark安装包上传到master虚拟机
- 下载Spark:pyw2
- 进入
/opt目录,查看上传的spark安装包

1.2 将spark安装包解压到指定目录
- 执行命令:
tar -zxvf spark-3.3.2-bin-hadoop3.tgz
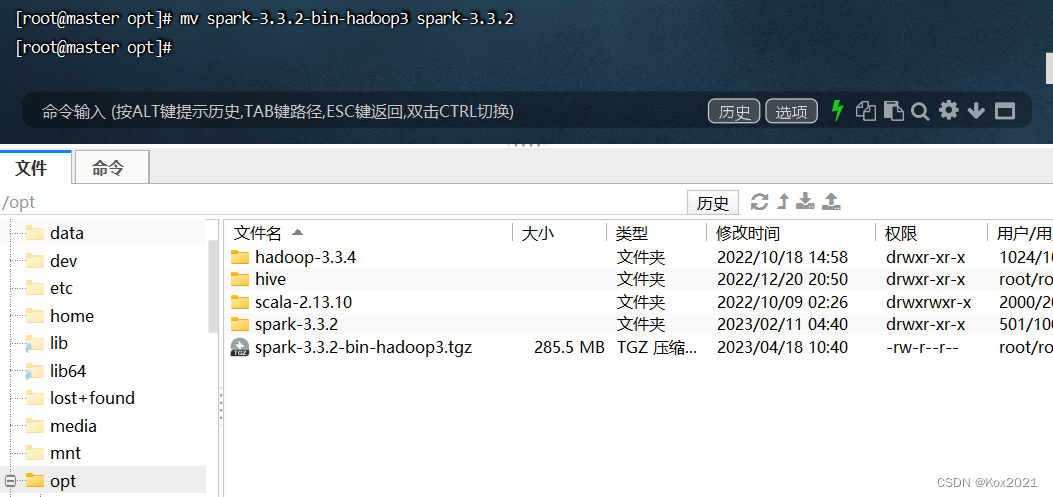
- 修改文件名:
mv spark-3.3.2-bin-hadoop3 spark-3.3.2
1.3 配置spark环境变量
- 执行命令:
vim /etc/profile
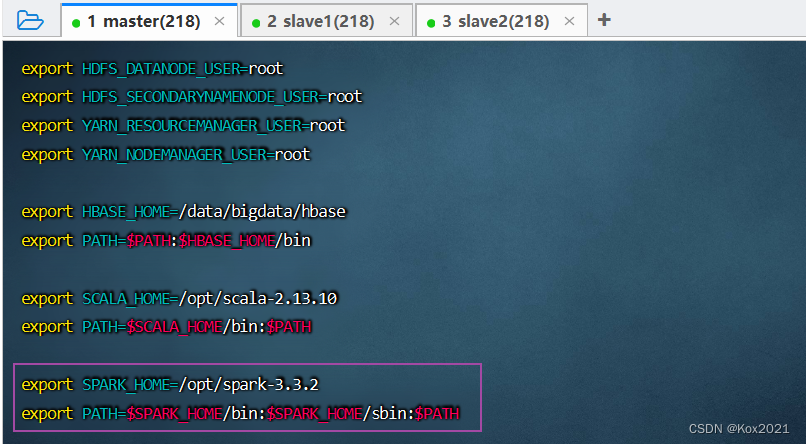
export SPARK_HOME=/opt/spark-3.3.2
export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
- 存盘退出后,执行命令:
source /etc/profile,让配置生效

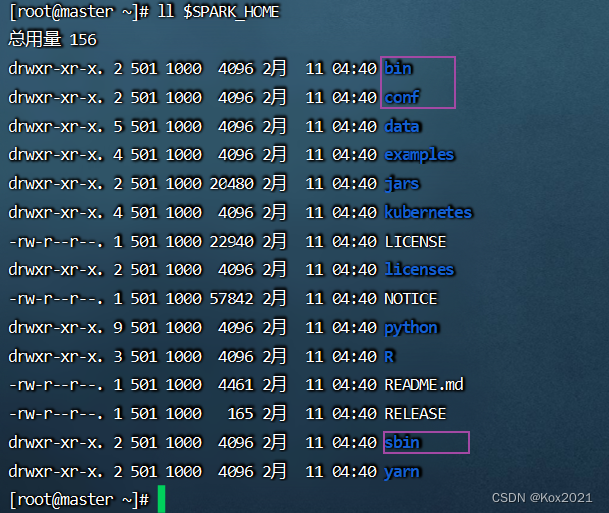
- 查看spark安装目录(bin、sbin和conf三个目录很重要)
1.4 编辑spark环境配置文件
- 进入spark配置目录后,执行命令:
cp spark-env.sh.template spark-env.sh与vim spark-env.sh

- 添加三行语句
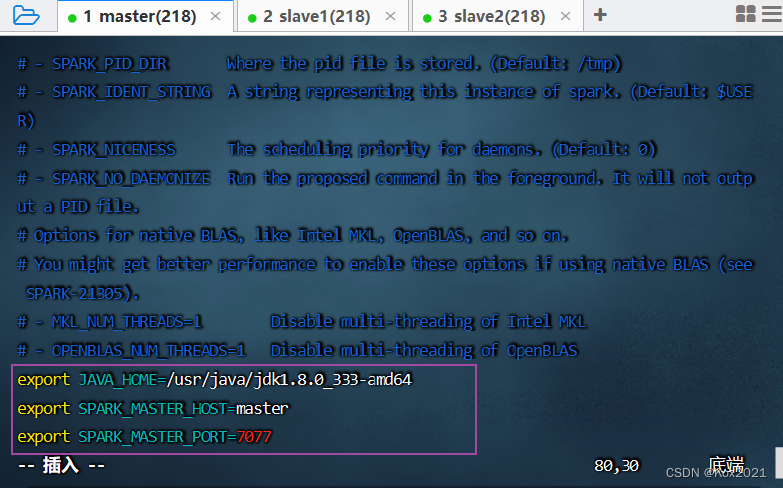
export JAVA_HOME=/usr/java/jdk1.8.0_333-amd64
export SPARK_MASTER_HOST=master
export SPARK_MASTER_PORT=7077
- 存盘退出,执行命令:
source spark-env.sh,让配置生效

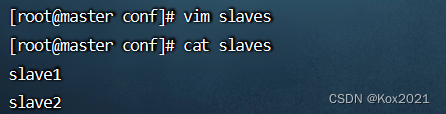
1.5 创建slaves文件,添加从节点
- 执行命令:
vim slaves,添加两个从节点主机名
二、在slave1虚拟机上安装配置Spark
2.1 把master虚拟机上安装的spark分发给slave1虚拟机
- 执行命令:
scp -r $SPARK_HOME root@slave1:$SPARK_HOME

2.2 将master虚拟机上环境变量配置文件分发到slave1虚拟机
-
在master虚拟机上,执行命令:
scp /etc/profile root@slave1:/etc/profile

-
在slave1虚拟机上,执行命令:
source /etc/profile,让环境配置生效

2.3 在slave1虚拟机上让spark环境配置文件生效
- 在slave1虚拟机上,进入spark配置目录,执行命令:
source spark-env.sh
三、在slave2虚拟机上安装配置Spark
3.1 把master虚拟机上安装的spark分发给slave2虚拟机
- 执行命令:
scp -r $SPARK_HOME root@slave2:$SPARK_HOME

3.2 把master虚拟机上环境变量配置文件分发到slave2虚拟机
- 在master虚拟机上,执行命令:
scp /etc/profile root@slave2:/etc/profile

- 在slave2虚拟机上,执行命令:
source /etc/profile,让环境配置生效

3.3 在slave2虚拟机上让spark环境配置文件生效
- 在slave2虚拟机上,进入spark配置目录,执行命令:
source spark-env.sh
四、启动Spark Standalone集群
4.1 启动hadoop的dfs服务
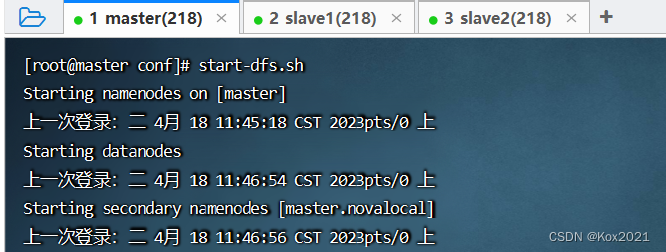
- 在master虚拟机上执行命令:
start-dfs.sh
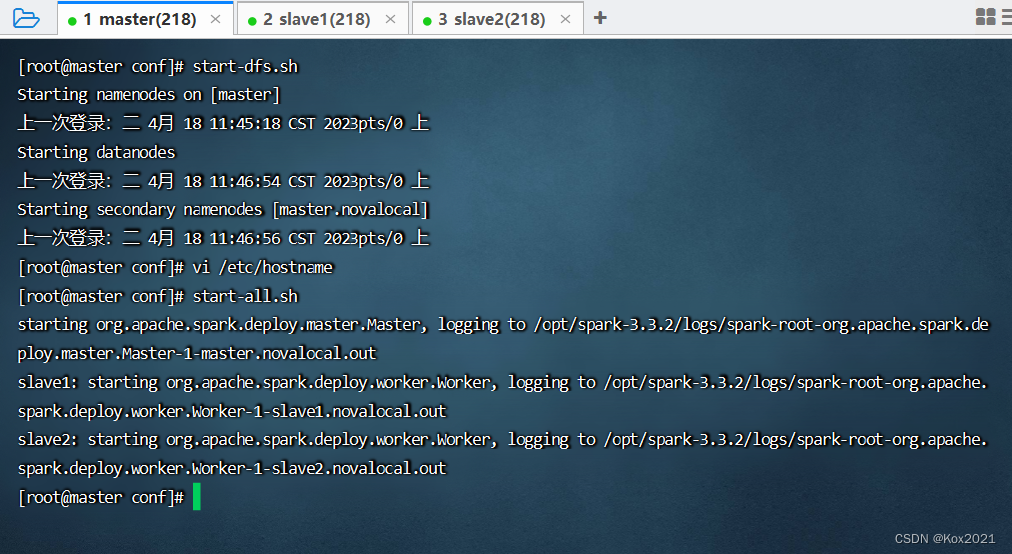
4.2 启动Spark集群
- 执行命令:
start-all.sh
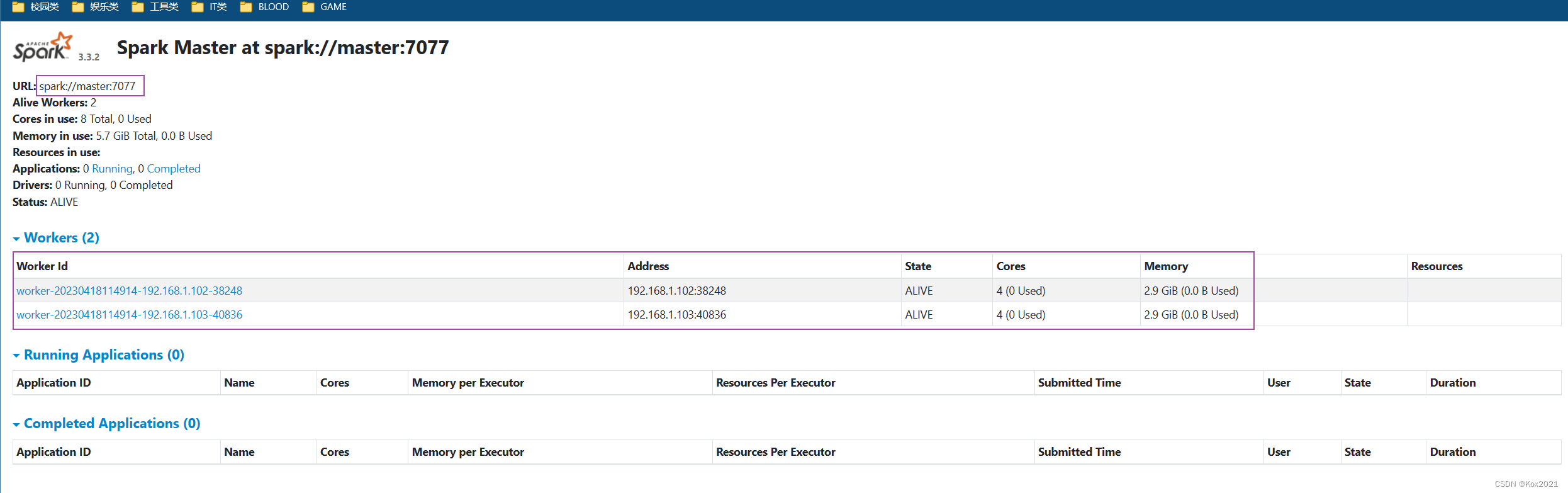
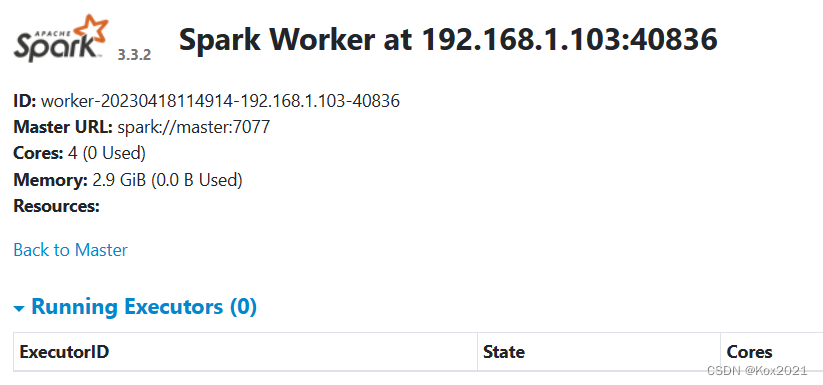
五、访问Spark的WebUI
- 在浏览器里访问
http://master:8080
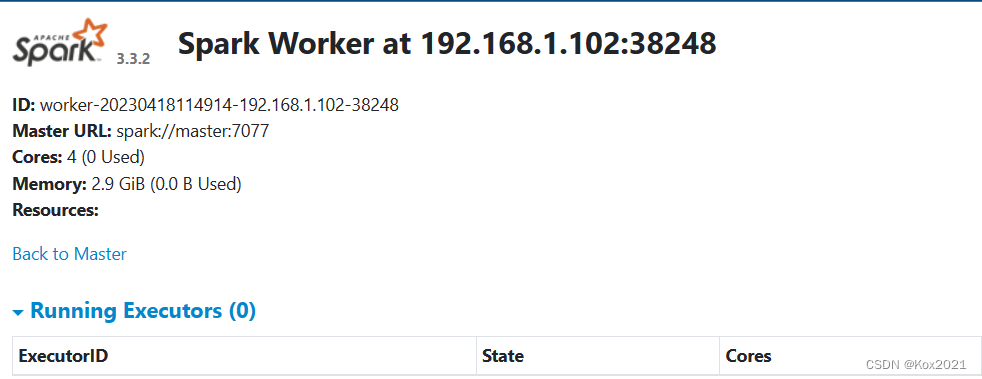
- 在浏览器访问
http://slave1:8081
- 在浏览器访问
http://slave2:8081
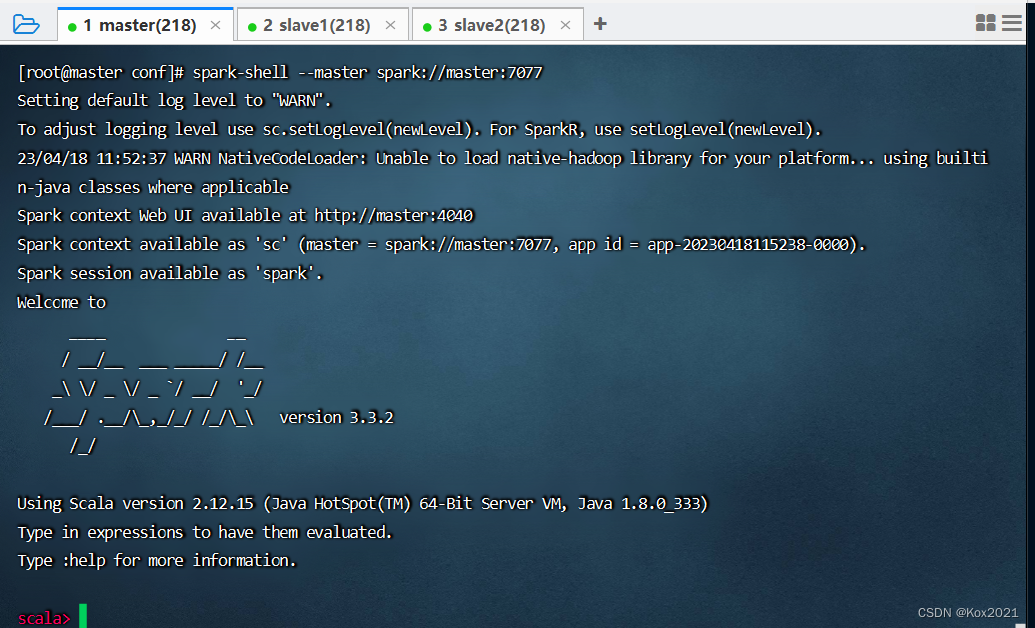
六、启动Scala版Spark Shell
- 执行命令:
spark-shell --master spark://master:7077(注意–master,两个-不能少)
- 在/opt目录里执行命令:
vim test.txt
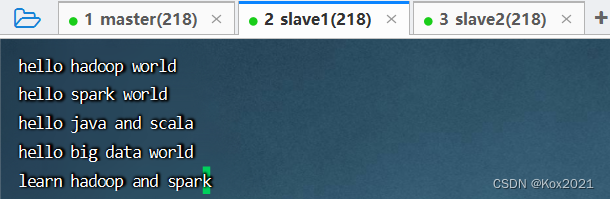
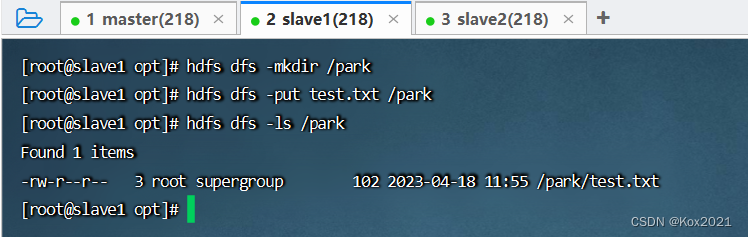
- 在HDFS上创建park目录,将test.txt上传到HDFS的/park目录
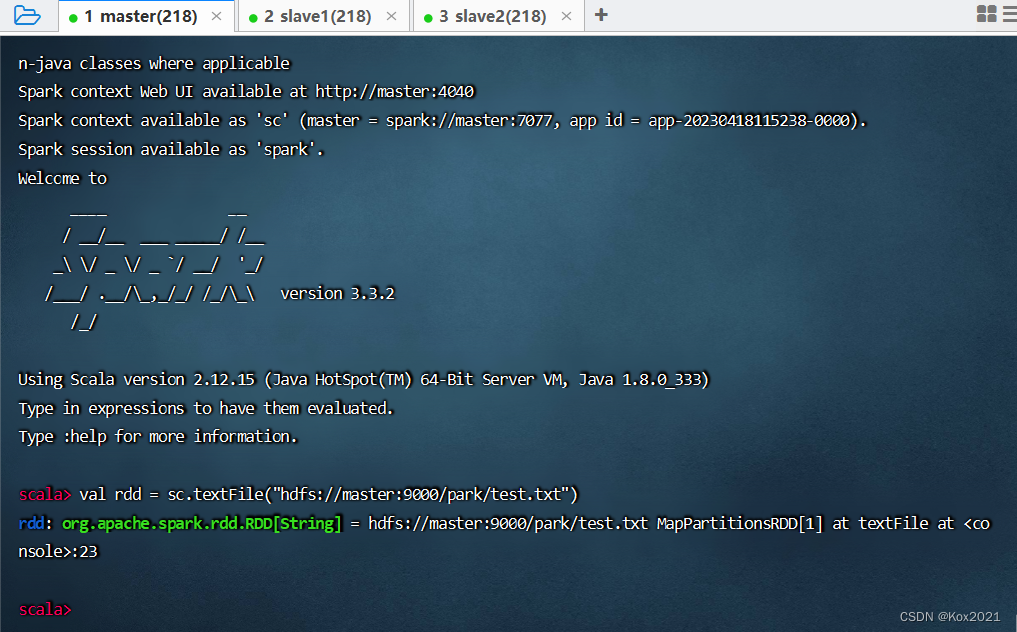
- 读取HDFS上的文件,创建RDD,执行命令:
val rdd = sc.textFile("hdfs://master:9000/park/test.txt")(说明:val rdd = sc.textFile("/park/test.txt")读取的依然是HDFS上的文件,绝对不是本地文件)
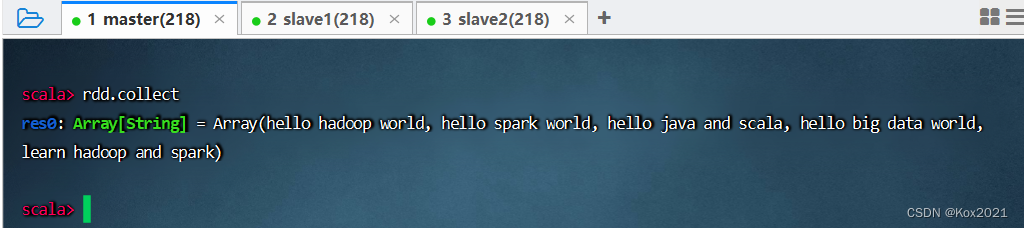
- 收集rdd的数据,执行命令:
rdd.collect
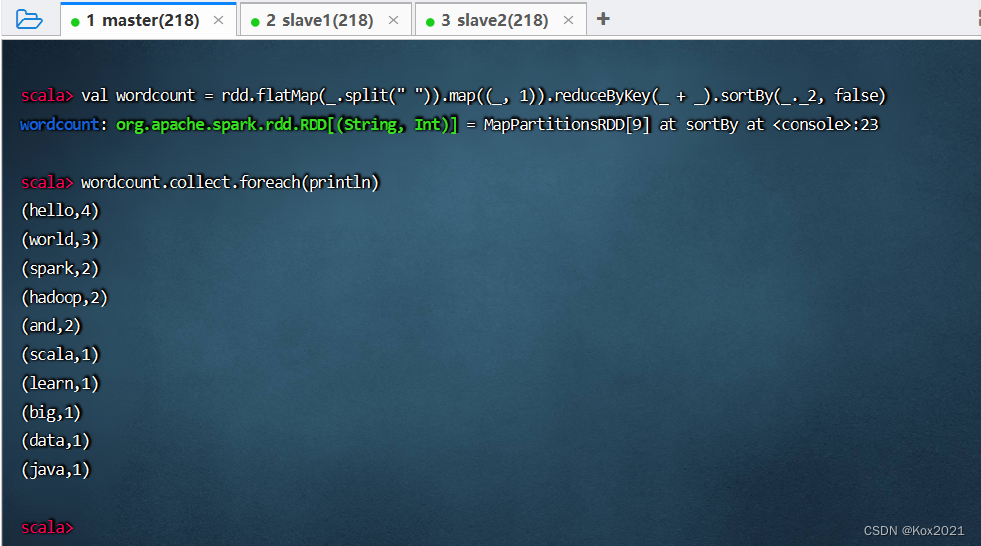
- 进行词频统计,按单词个数降序排列,执行命令:
val wordcount = rdd.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).sortBy(_._2, false)与wordcount.collect.foreach(println)
七、提交Spark应用程序
7.1 提交语法格式
- Spark提供了一个客户端应用程序提交工具spark-submit,使用该工具可以将编写好的Spark应用程序提交到Spark集群。
- spark-submit的使用格式如下:
$ bin/spark-submit [options] <app jar> [app options] - options表示传递给spark-submit的控制参数;
- app jar表示提交的程序JAR包(或Python脚本文件)所在位置;
- app options表示jar程序需要传递的参数,例如main()方法中需要传递的参数。
7.2 spark-submit常用参数
- 除了–master参数外,spark-submit还提供了一些控制资源使用和运行时环境的参数。

7.3 案例演示 - 提交Spark自带的圆周率计算程序
- 进入Spark安装目录
(1)Standalone模式,采用client提交方式
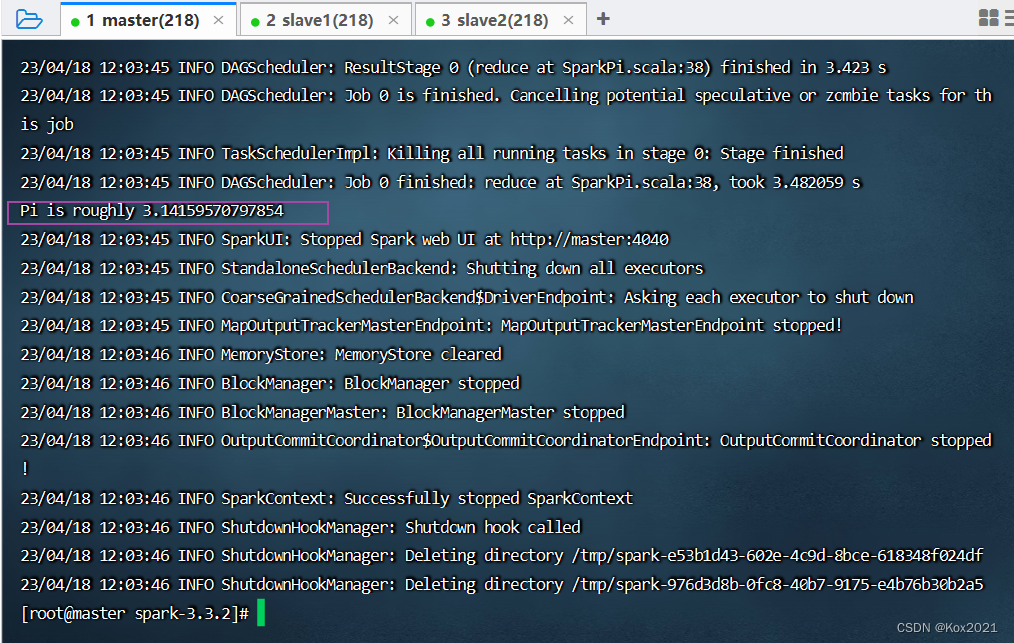
- 执行下述命令,将Spark自带的求圆周率的程序提交到集群
bin/spark-submit \\--class org.apache.spark.examples.SparkPi \\--master spark://master:7077 \\./examples/jars/spark-examples_2.12-3.3.2.jar
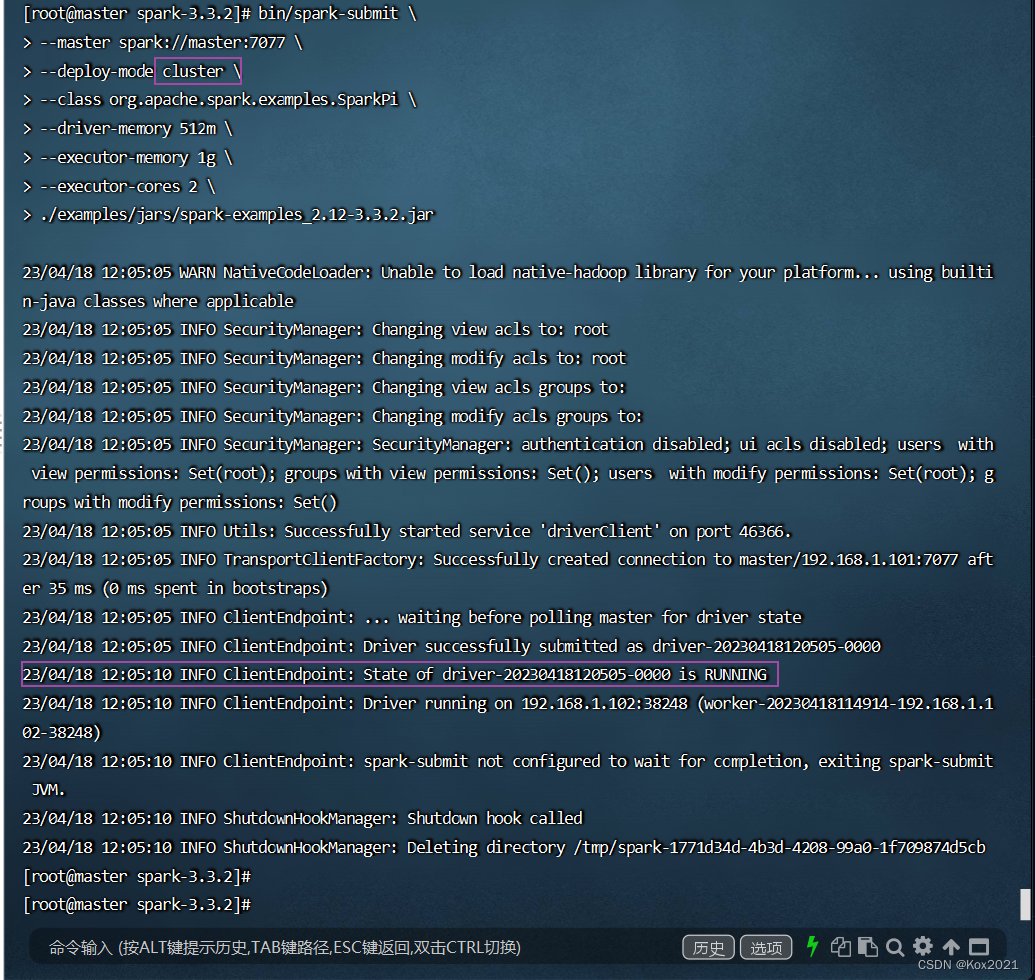
(2)Standalone模式,采用cluster提交方式
bin/spark-submit \\
--master spark://master:7077 \\
--deploy-mode cluster \\
--class org.apache.spark.examples.SparkPi \\
--driver-memory 512m \\
--executor-memory 1g \\
--executor-cores 2 \\
./examples/jars/spark-examples_2.12-3.3.2.jar- 执行命令后,看到
State of driver-20230406114733-0000 is RUNNING,就表明运行成功~,否则会显示State of driver-20230406114733-0000 is FAILED
- 在Spark WebUI界面上查看运行结果,访问
http://master:8080
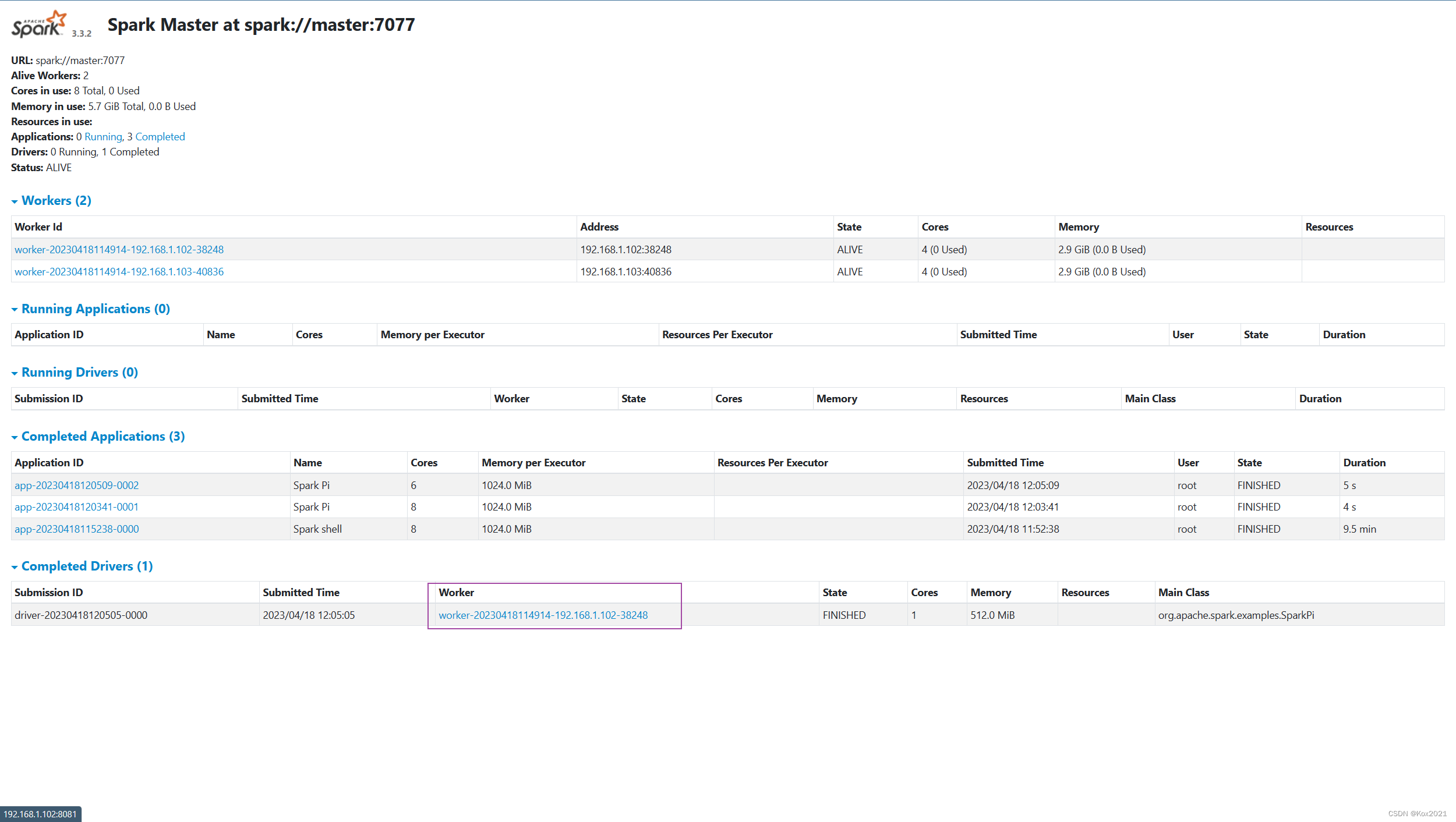
- 单击圈红的Worker超链接
- worker-20230406114652-192.168.1.102-36708
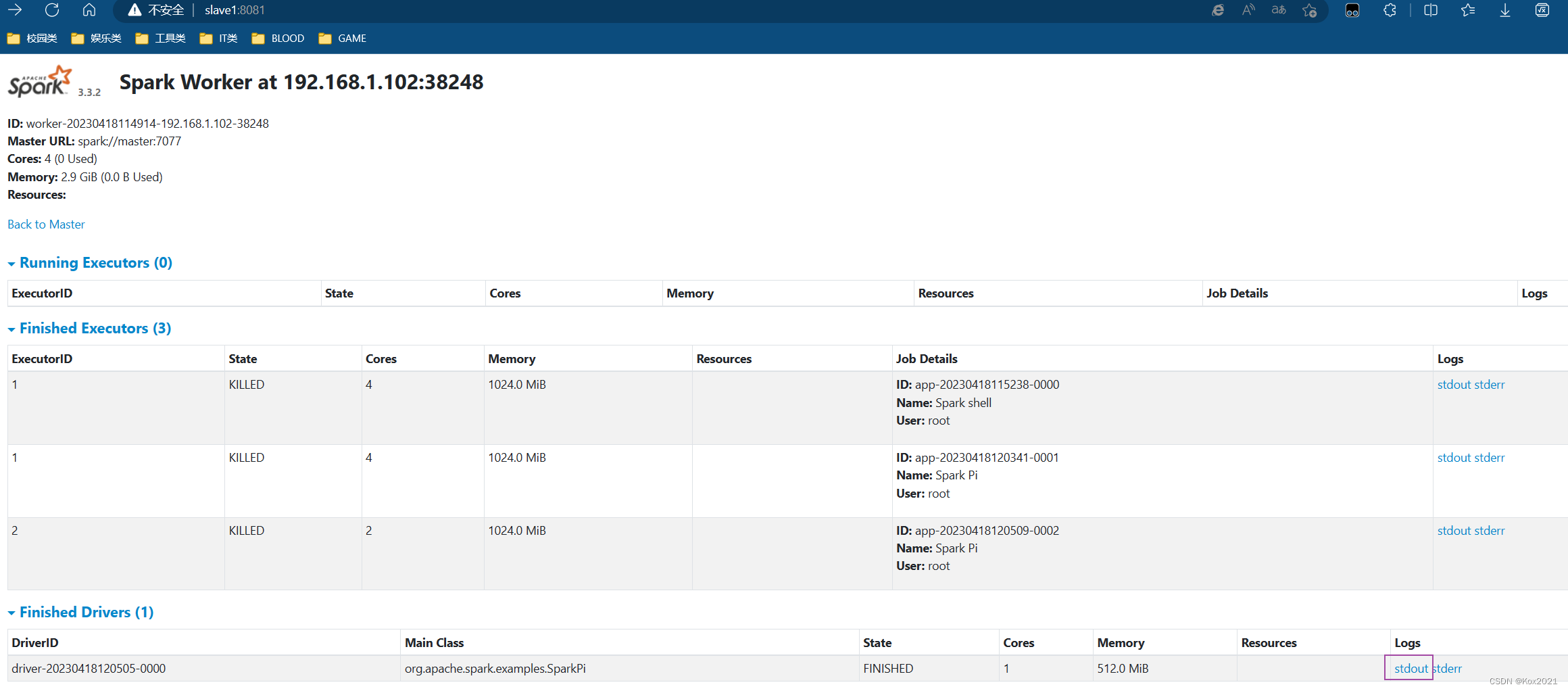
- 单击
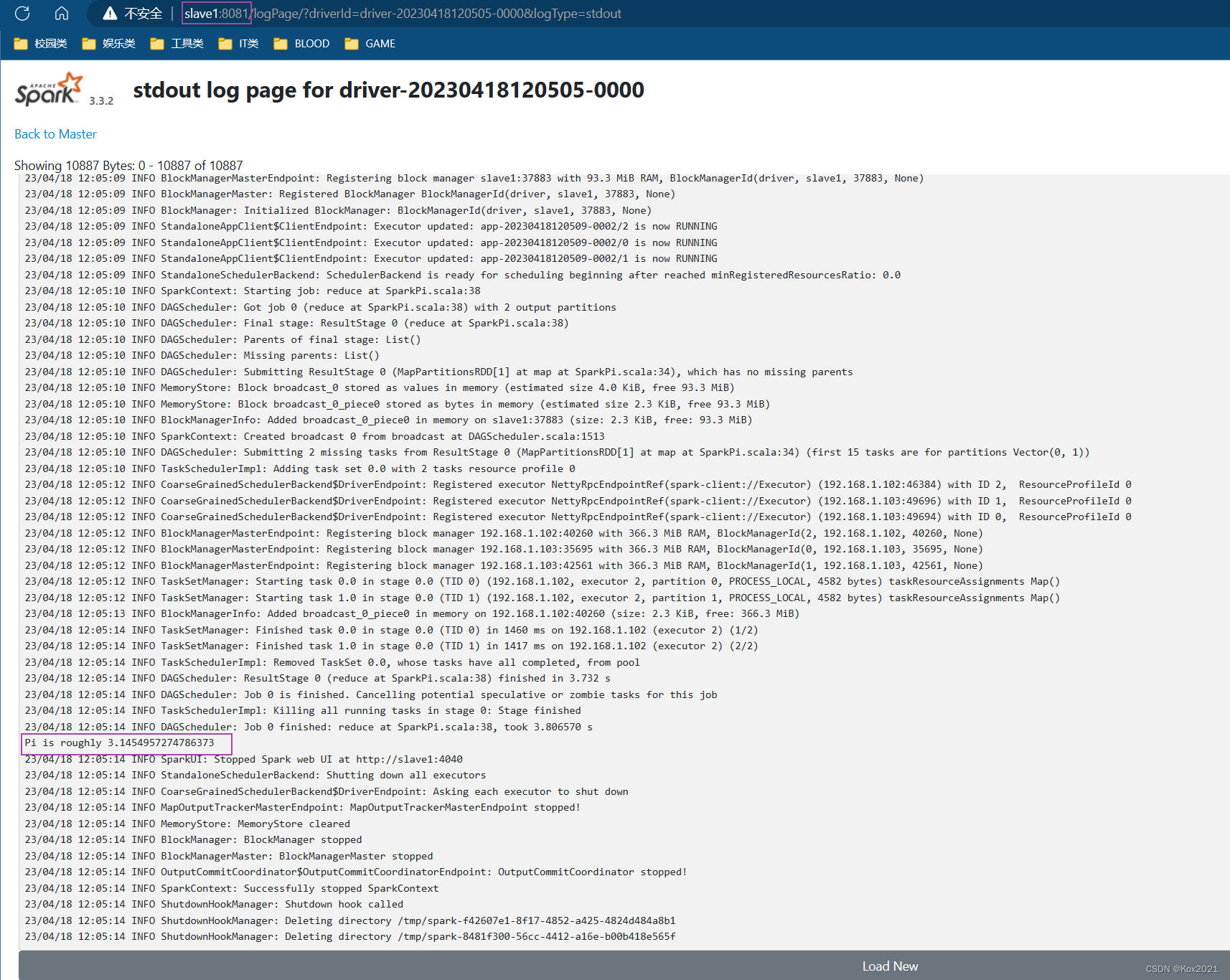
stdout超链接,可以查看到Pi的计算结果
八、停止Spark集群服务
- 在master节点执行命令:
stop-all.sh