从前端角度快速理解Transformer

从前端角度快速理解Transformer
- Transformer的三步曲
- 从前端角度(SEO和TDK)理解Transformer
-
- SEO与TDK
- 一个例子来理解
- 总结
声明:本文为原创,未经同意请勿转载或爬取,感谢配合😄
chatGPT今年年初的时候是非常火爆的,现在也有很多相关的应用和插件。当然现在也有很多新的技术出现,比如autoGPT,它实际上就是嵌套chatGPT。但它们也都涉及到19年20年很火的Transfomer模型,所以这里笔者我希望通过通俗易懂的语言描述一下Transformer的原理。并从前端的角度谈谈Transformer这里模型怎么理解,希望入门读者也可以快速抓住要点。相信Transformer的原理很多博客都有介绍,这里笔者我希望以笔者我的新角度来讲讲Transformer的注意力机制。也欢迎各位小伙伴或者大佬来指正交流,互相学习与讨论🤗。
在前面我会先介绍一下Transformer的核心点,然后在从前端的角度,说说我是怎么从前端的角度来理解Transformer这个模型的。
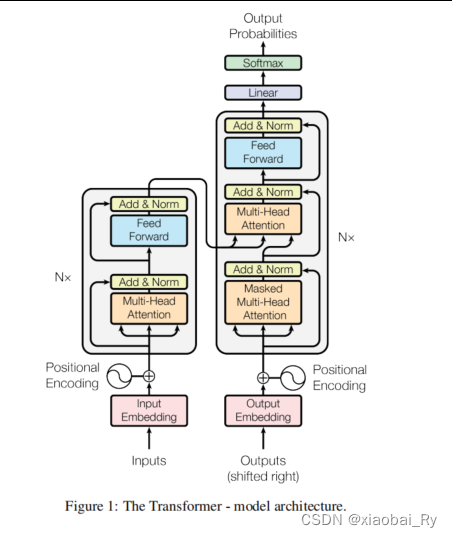
Transformer的三步曲
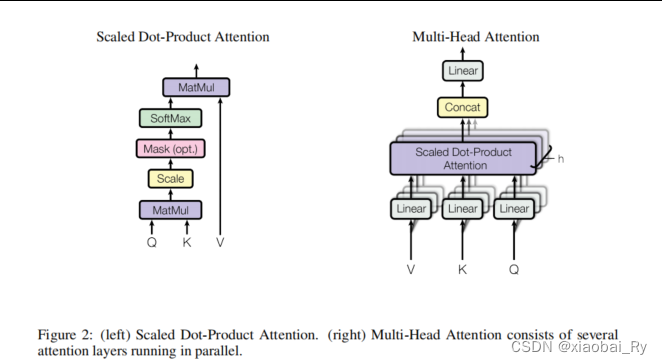
首先,Transformer是在自然语言处理NLP领域提出的一个基于自注意力机制self-attention的模型,主要由编码器和解码器两个部分构成。其中,编码器和解码器也是采用多头的注意力机制来进行构建的。所以,Transformer这个模型的核心其实就是自注意力机制。而这种自注意力机制它的核心其实就是通过Q(query 查询),K(key,健/关键词),V(value,键值)三个特征张量来进行构建的。具体来说可以分为三步:
- 第1步:先对原始的特征张量分别进行三次变换得到Q,K,V三个特征张量
- 第2步:利用查询张量Q和健张量K进行点积得到注意力分数张量A,这个A代表的就是重要性,也就是对键值张量V的贡献程度
- 第3步:利用注意力分数张量A与键值张量V进行加权求和得到新的特征张量,以此更新原始的特征张量。
从前端角度(SEO和TDK)理解Transformer
如果看到这里,你觉得上面的描述仍然不够通俗的话,我们其实可以从SEO(搜索引擎优化)和meta标签的角度来理解Transformer。如果你对上面这两个概念不是很理解的话建议看我的另外一篇博客笔记《【图-注意力笔记,篇章1】Graph Transformer:包括Graph Transformer 的了解与回顾且其与GNN、Transformer的关联》。这里有关Transformer公式的理解。
SEO与TDK
言归正传,先介绍一下SEO与<meta>之前的关系吧。
如果对这一部分了解的可以跳到下一部分
前端网页中<meta>标签的内容设计对SEO来说是非常重要的,它主要通过TDK来影响。简单来说,就是搜索引擎会根据HTML中title标签和meta标签的Keywords、Description属性来进行结果进行一个排序。其中,网页的title标签可以被浏览器显示在顶端菜单栏上,而meta标签的话对用户是不可见的,拿CSDN首页做一个例子吧。打开网页开发工具,我们可以看到:
 head标签下面有title标签和meta标签两个子标签。其中的话,meta标签下有keywords和description两个属性,content表示对应的内容。所以搜索引擎可以通过抓取TDK来进行优化排序。所以TDK三个的设置对网页开发是重要的,这决定你的网站能否对优先展示在用户面前,这一般是由专门做SEO相关岗位的人来做的。
head标签下面有title标签和meta标签两个子标签。其中的话,meta标签下有keywords和description两个属性,content表示对应的内容。所以搜索引擎可以通过抓取TDK来进行优化排序。所以TDK三个的设置对网页开发是重要的,这决定你的网站能否对优先展示在用户面前,这一般是由专门做SEO相关岗位的人来做的。
一个例子来理解
了解完前面的SEO和TDK,那我们就拿《Attention is all you need》(Transformer原论文)这篇文章做一个例子进行理解与解释吧。下面是我从arXiv网站《Attention is all you need》这篇文章打开的网页源码:
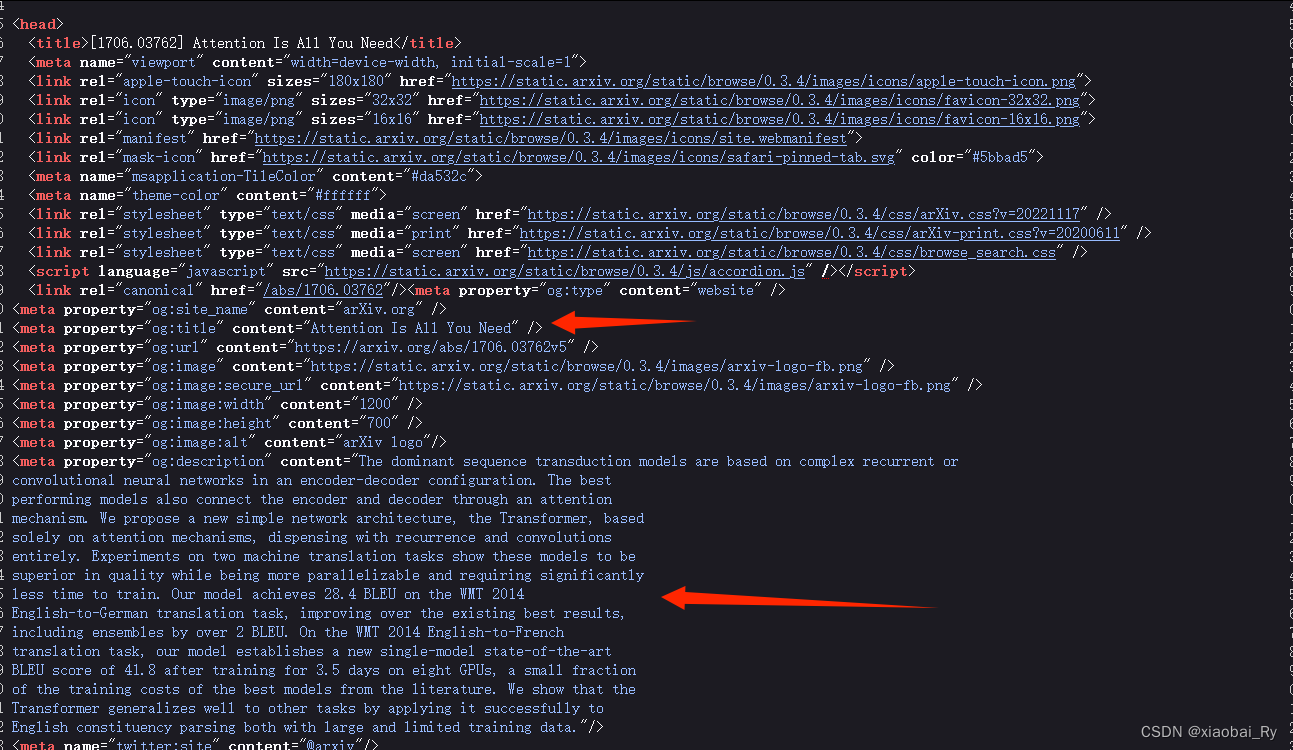 这里og是一个协议,不用过分去细究。自己打开网页源码看看,你会发现它竟然没有keywords属性!!!不过笔者我回去看了一眼文章,文章里面的确也没有keywords:
这里og是一个协议,不用过分去细究。自己打开网页源码看看,你会发现它竟然没有keywords属性!!!不过笔者我回去看了一眼文章,文章里面的确也没有keywords:
 不过,没有关系,上面我们仅仅是做一个展示而言😂。这里我们可以先做一个假设,
不过,没有关系,上面我们仅仅是做一个展示而言😂。这里我们可以先做一个假设,
假设Transformer这篇文章的特征张量K是【Attention, Transformer, NLP】三个词构成的,原始的特征张量是这篇文章本身的内容。
-
那我们先讲一下🤔为什么Transformer首先在第一步会继续一个线性变换?
这是因为我们搜索时,可能在搜索框输入的查询张量是【transformer,原论文,链接】。那它跟文章的原始特征向量其实就是不一样的。而且每个人搜索都不会不一样,所以也有了线性变换和多头的想法。K和V也是同样的道理,所以第一步一般是先对原始的特征向量分别进行一个变换,得到Q,K,V三个特征张量。

-
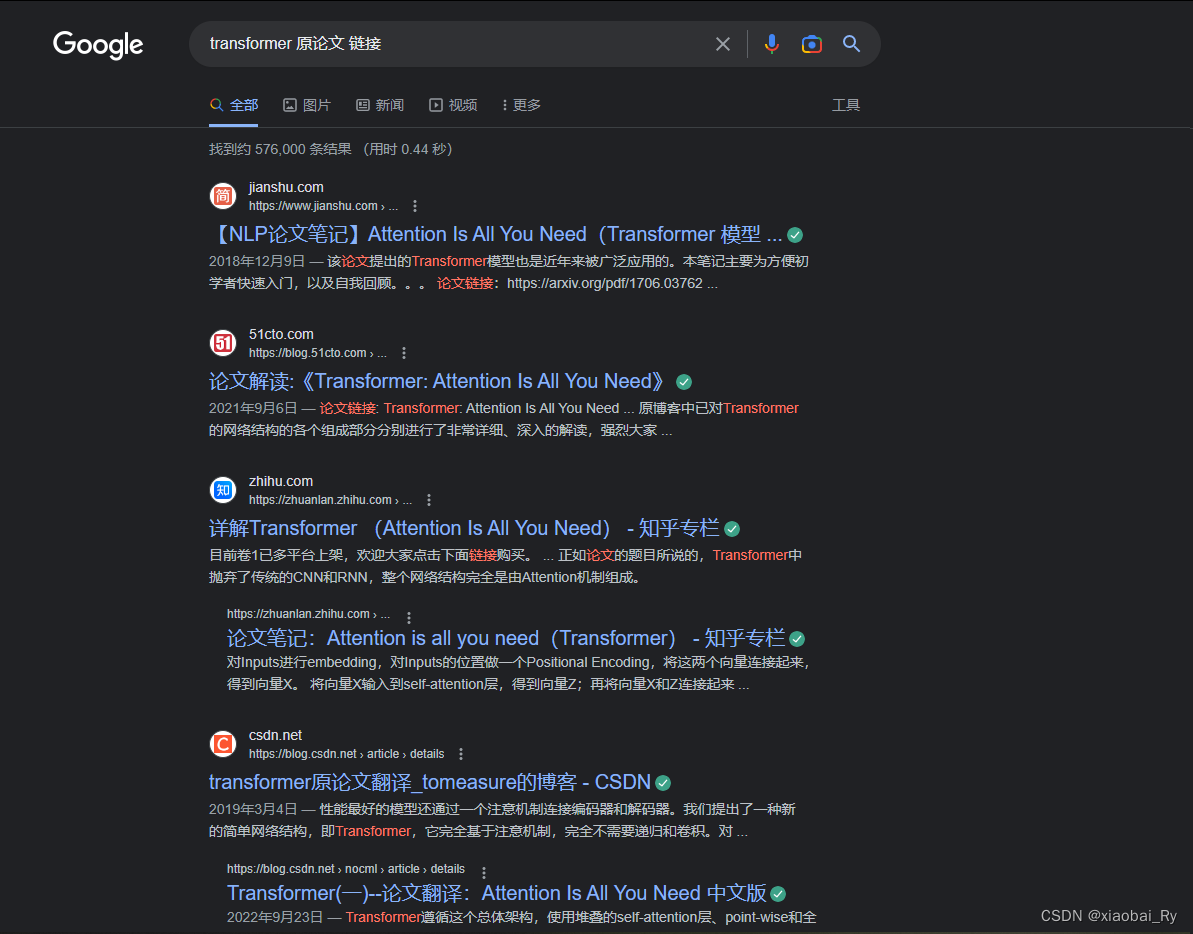
第二步,当我们点击搜索按钮后,那搜索引擎就会利用这些查询值Q,和数据库文章里面的关键词K进行匹配,并返回搜索结果,这个搜索结果会按照贡献度也就是重要性进行一个排序。这里相当于上面说的Q和K点积之后得到的注意力分数A的排序。可以看到对应标红的部分与查询值是匹配的。
-
第三步,当得到注意力分数之后,就需要对键值V也就是相当于文章的特征(这里可以看作title标签和meta标签的Description属性里面地内容,相当于文章的主题和标题特征合并为文章的特征)来进行一个加权求和,才能得到跟当前查询值最匹配的特征,最其实就是搜索引擎优化做的事情。通过不断地优化来满足用户地搜索需求。所以你也会发现不同搜索引起搜索出来地结果会不一样。
总结
上面讲的主要是Transformer的注意力机制是怎么做的以及怎么理解地。在Transformer结构中,它其实就在它的编码器和解码器都使用了多头的注意力机制来实现对不同特征子空间的关注,而且它还采用了位置编码、残差连接、层归一化和前向全连接网络等。简单来说就是Transformer就是基于位置编码和输入,来利用多头注意力机制进行编码和解码,从而得到模型的输出。