fMRIflows:全自动单变量和多变量fMRI处理管道的联合体

导读
如何分析fMRI数据取决于研究人员和所使用的工具箱。为每个新数据集重写处理管道的情况并不少见。因此,代码透明度、质量控制和客观分析管道对于提高神经影像研究的可重复性非常重要。Nipype和fMRIPrep等工具箱的广泛使用已经证明了研究人员对自动化预处理分析管道的需求和兴趣。数据驱动模型与高分辨率神经成像数据集相结合的最新发展不仅加强了对标准化预处理流程的需求,也加强了对可靠且可比较的统计管道的需求。本研究介绍了fMRIflows:一个用于fMRI分析的全自动神经成像管道,该管道执行标准的预处理,以及一级与二级单变量和多变量分析。除了标准化的预处理管道外,fMRIflows还提供灵活的时间和空间滤波,以适应时间分辨率越来越高的数据集,并帮助为高级机器学习分析适当准备数据,从而提高信号解码的准确性和可靠性。本文首先介绍了fMRIflows的结构和功能,然后解释了其基础架构和访问方式,最后通过将其与其他神经成像处理管道(如fMRIPrep、FSL和SPM)进行比较来验证该工具箱。该验证是在三个不同时间采样和采集参数的数据集上进行的,以证明其灵活性和鲁棒性。fMRIflows是一个全自动的fMRI处理管道,独特地提供了单变量和多变量的单被试和组分析以及预处理。
前言
功能性磁共振成像(fMRI)是一种成熟的神经成像方法,用于分析激活模式以了解大脑功能。完整的fMRI分析包括对数据进行预处理,然后对结果进行统计分析和推断,通常分为一级分析(被试内的统计分析)和二级分析(被试间的组分析)。预处理的目标是识别和去除干扰源,测量混淆因素,应用时间和空间滤波器,并在空间上重新对齐和归一化图像以使其在空间上保持一致。良好的预处理管道应该提高数据的信噪比(SNR),确保推断的有效性和结果的可解释性,减少统计分析中的假阳性和假阴性错误,从而提高统计功效。
尽管不适当的预处理和统计推断的后果有据可查,但大多数fMRI分析管道仍然是由研究人员根据每个新数据集主观定制的。这种用法可以解释为:大多数研究人员,由于习惯或缺乏时间,因而坚持使用手头的神经成像软件,或者重用、修改来自同事和以前项目的脚本和代码片段,并没有总是使他们的处理流程适应神经成像处理的最新标准。重散列处理管道与一些问题有关,如代码中持续存在的bug,以及单个分析步骤到最新标准的更新延迟等问题。这可能导致深远的后果。当然,针对最新标准和软件不断更新管道也存在引入新错误的风险,并可能导致盲目地信任新的未经测试程序的陷阱。有关该问题的解决方案需要代码透明度、良好的质量控制和共同开发且经过良好测试的客观分析管道。近年来,神经影像学领域朝着这个方向进行了一些重要的改革。
首先,Nipype的引入使研究人员更容易在不同的神经成像工具箱(如AFNI、ANT、FreeSurfer、FSL和SPM)之间切换。Nipype与Nibabel和Nilearn等其他软件包一起为神经成像社区打开了整个Python生态系统。研究人员之间可以通过GitHub(https://github.com)等在线服务共享代码,通过使用Docker(https://www.docker.com)或Singularity(https://www.sylabs.io)等集成软件,整个神经成像软件生态系统可以在任何机器或服务器上运行。结合持续集成系统,如CircleCI(https://circleci.com)或TravisCI(https://travis-ci.org),这允许创建易懂、透明、可共享和持续测试的开源神经成像处理管道。
其次,神经成像领域的下一个重大进展是引入了通用数据集标准,例如NIfTI标准(https://nifti.nimh.nih.gov/)。这对于神经影像数据的格式化非常重要。神经成像社区定义了用于存储神经影像数据集的标准格式,即所谓的脑成像数据结构(BIDS)。通用的数据结构格式有助于数据集的共享,并可以创建通用的神经成像工具箱,这些工具箱可以在任何符合BIDS的数据集上开箱即用。此外,通过OpenNeuro(一个免费且开源的神经成像数据共享平台)等服务,人们可以在数百个不同的数据集上测试新的神经成像工具箱的鲁棒性和灵活性。
像MRIQC和fMRIPrep等软件工具箱已经展示了这种新的神经成像生态系统的丰富成果,并强调了良好质量控制和高质量预处理工作流程的重要性和必要性,这些工作流程可以从不同的数据集获得一致的结果。随着数据驱动分析领域从fMRI时间序列解码大脑状态的最新进展,对可靠和可重复的fMRI数据统计分析的需求增加,这些数据是更先进的机器学习方法的基础输入,如多体素模式分析(MVPA)和卷积神经网络(CNN)。在这里,本研究从fMRIPrep工作流程进行构建,将其扩展为用于单变量和多变量的个体和组分析的全自动化管道。
fMRIflows提供了灵活的时间和空间过滤,以说明数据驱动模型领域的两项最新发现。首先,灵活的空间滤波对于执行多变量分析是很重要的,因为已有研究证明正确的空间带通滤波可以提高信号解码精度。其次,正确的时间滤波对于预处理过程是很重要的,并且可以提高SNR,特别是对于时间采样率低于1秒的fMRI数据集,但前提是滤波器在预处理期间正交于其他滤波器,以确保先前去除的噪声不会重新引入到数据中。由于通过GRAPPA等加速技术和同时多层/多波段采集记录技术的改进,从而使更快的采样率成为可能,以至于可以在BOLD信号中充分采样呼吸和心脏信号。这给功能图像的预处理带来了新的挑战,特别是当这些生理源的外部记录不易实现时。
fMRIflows提供了一个用于fMRI分析的全自动神经成像管道集合,该管道可以执行标准化的预处理,以及用于单变量和多变量分析的一级和二级统计分析,并额外创建了信息质量控制图。fMRIflows基于MRIQC和fMRIPrep的原理和代码库,并将其功能扩展为:(a)对fMRI数据进行灵活的时间和空间滤波,即低通或带通滤波,以去除通过生理噪声引入的高频振荡;(b)具有可访问和可修改的代码库;(c)自动计算单变量和多变量分析的一级对比;(d)自动计算单变量和多变量分析的二级对比。
在本文中,研究者(1)描述了fMRIflows中包含的不同管道,并说明了所涉及的不同处理步骤;(2)解释了软件结构和设置;以及(3)通过将fMRIflows与其他广泛使用的神经成像工具箱(如fMRIPrep、FSL和SPM)进行比较来验证fMRIflows的性能。
材料和方法
fMRIflows的处理管道
fMRIflows的完整代码库是开放访问的,并方便地存储在 https://github.com/miykael/fmriflows上的六个不同的Jupyter Notebooks中。第一个notebook不包含任何处理管道,而是用作用户输入文档,帮助创建JSON文件,该文件将包含fMRIflows中包含的五个处理管道的执行特定参数:(1)结构预处理;(2)功能预处理;(3)一级分析;(4)二级单变量分析;(5)二级多变量分析。这五个管道中的每一个都将其结果存储在一个子层次文件夹中,该文件夹由用户指定为输出文件夹。接下来将解释这六个Jupyter Notebooks的内容。
①准备细则
每个fMRIflows处理管道都需要特定的输入参数来运行。这些参数范围从被试ID和每个被试的功能运行次数,到图像归一化后要求的体素分辨率等。每个notebook将从一个以前缀“fmriflows_spec”开头的预定义JSON文件中读取相关规范参数。有一个用于结构和功能预处理的规范文件,一个用于一级和二级单变量分析的规范文件,一个用于二级多变量分析的规范文件。有关这三个JSON文件的示例,请参阅补充说明1。fMRIflows中包含的第一个notebook称为01_spec_preparation.ipynb,可根据提供的数据集和一些标准默认参数创建这些JSON文件。它通过使用Nibabel v2.3.0,PyBIDS v0.8和其他标准Python库来实现这一点。如果任何潜在的处理参数与使用的默认值不同,则由用户自行更改。
②结构预处理
结构预处理管道包含在notebook的02_preproc_anat.ipynb中,并使用JSON文件fmriflows_spec_preproc.json作为参数规范(如体素分辨率)。如果未设置特定值,fMRIflows默认归一化为1mm3的等距体素分辨率。然而,用户也可以选择在所有三个维度上都不同的非等距体素分辨率。此外,用户可以决定是否进行快速或精确的归一化。精确归一化的时间可能是快速方法的八倍,但可以提供更精确的对齐。始终需要对执行的归一化进行目视检查,因为这两种归一化算法在有噪声的数据集或未检测到伪影的情况下都可能失败。
结构预处理管道仅依赖于被试特定的T1加权(T1w)图像作为输入文件。各个处理步骤如图1所示,包括:(1)图像重定向;(2)视场剪切(FOV);(3)强度非均匀性(INU)校正;(4)图像分割;(5)大脑提取;(6)图像归一化。
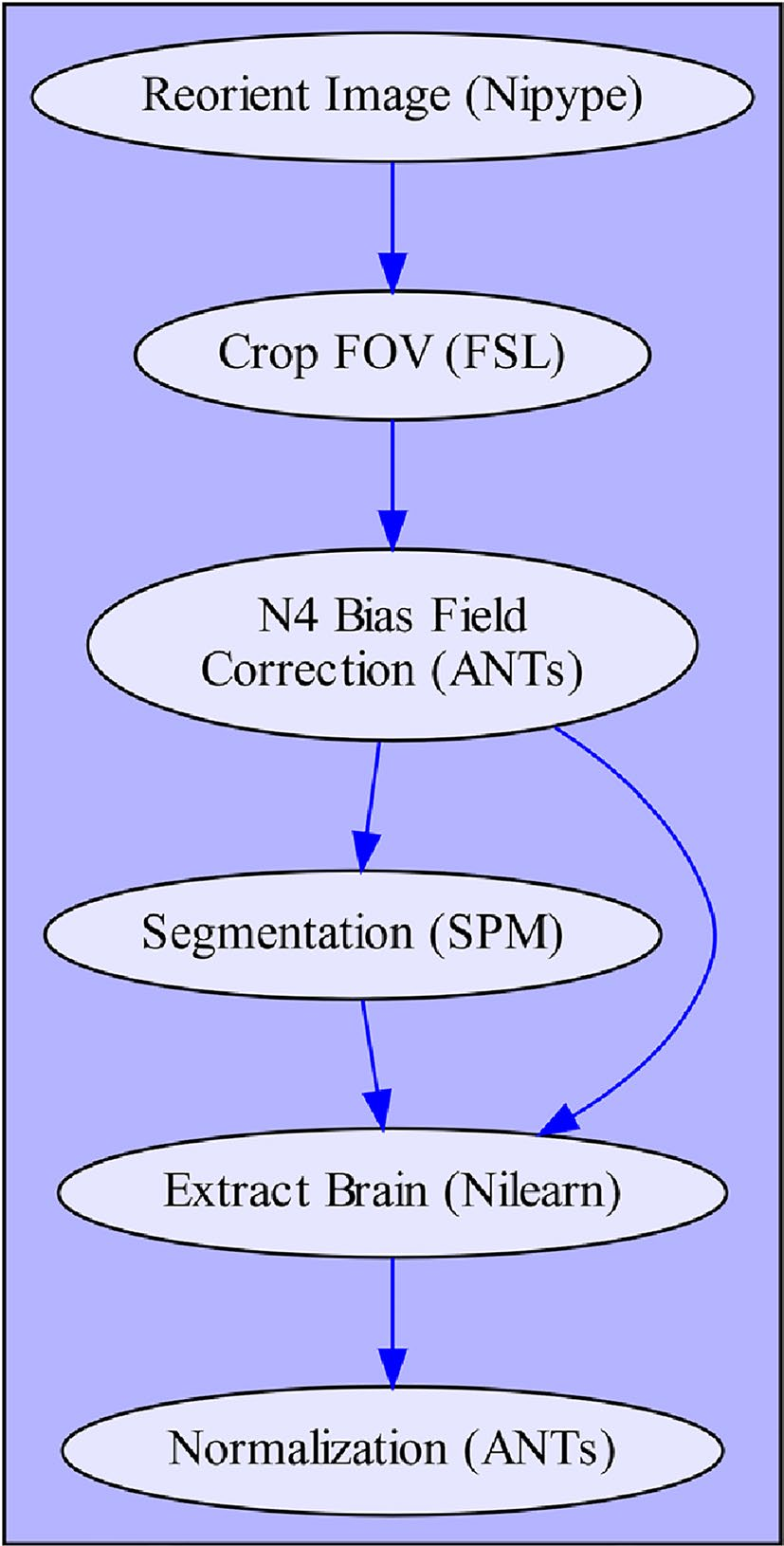
图1.fMRIflows的结构预处理管道。箭头表示不同处理步骤和数据流之间的依赖关系,括号中是相应的软件依赖项。
③功能预处理
功能预处理管道包含在notebook的03_preproc_func.ipynb中,并使用JSON文件fmriflows_spec_preproc.json用作参数规范。作为规范参数,用户可以指示是否应用时间层校正,如果应用,应使用哪个参考时间点。用户还可以指示应对哪个等距或非等距体素分辨率的功能图像进行采样。模板空间采用ICBM 2009c非线性非对称脑模板。此外,用户可以在时域或空域中指定低通、高通或带通滤波器的值。为了调查干扰回归因素,用户可以指定他们想要提取的CompCor或独立成分分析(ICA)成分的数量,以及用于检测异常volume的阈值。这些参数的含义将在以下部分进行更详细地解释说明。
功能预处理管道依赖于结构预处理管道的输出文件,以及特定于被试的功能图像和附带的描述性JSON文件,其中包含有关功能图像记录的时间分辨率(TR)和时间层顺序的信息。该JSON文件是BIDS标准的一部分,因此应该在BIDS规范数据集中可用。各个处理步骤如图2所示,包括:(1)图像重定向;(2)非稳态检测;(3)创建功能性脑掩膜;(4)时间层校正;(5)运动参数估计;(6)估计功能图像与解剖图像之间的共配准参数;(7)运动参数的最终确定;(8)单次空间插值应用运动校正,共配准和(如果指定)将图像归一化为模板图像;(9)脑掩膜的构建和应用;(10)时间滤波;(11)空间滤波。值得一提的是,功能预处理是针对每个功能运行分别进行的,以防止运行间的污染。
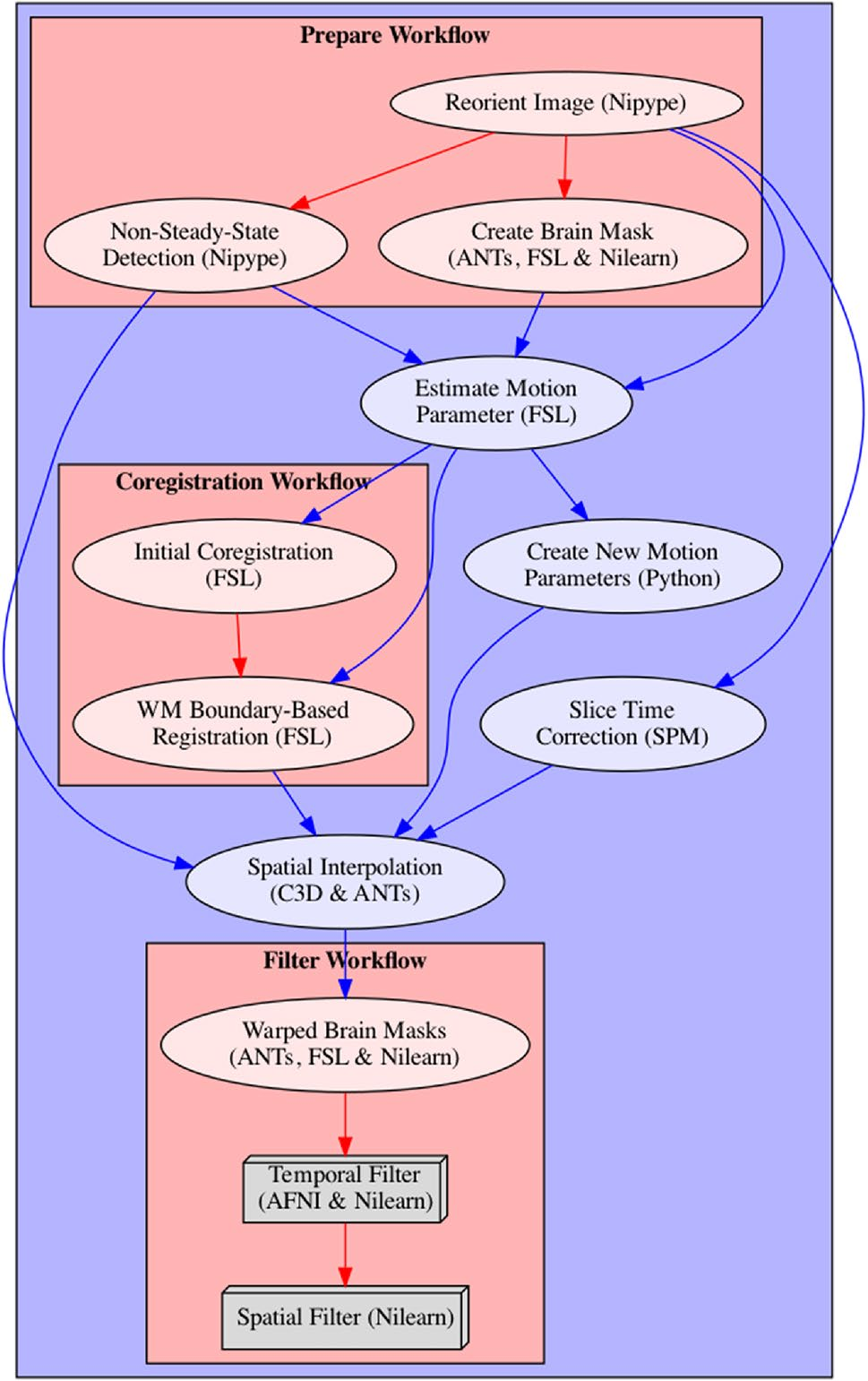
图2.fMRIflows的功能预处理管道。
一级分析
一级分析管道包含在notebook的04_analysis_1st-level.ipynb中,并使用JSON文件fmriflows_spec_analysis.json进行参数规范。作为规范参数,用户可以指示在GLM中包含哪些干扰回归量,是否应该考虑异常值,以及数据是否已经在模板空间中,或者是否应该在对比估计后进行归一化。用户还可以指定其他GLM模型参数,例如高通滤波器值和用于模拟血流动力学响应函数(HRF)的基函数类型。此外,用户还将指定一个他们想要估计的对比列表,或者他们是否想要为设计矩阵中的每个刺激列或单独为每个会话创建特定的对比,然后也可以用于多变量分析。
一级分析管道依赖于先前结构和功能预处理管道的大量输出,即包含运动参数和混淆回归量的TSV(制表符分隔值)文件、指示从功能图像中删除的非稳态volume数量的文本文件,以及包含识别异常volume索引列表的文本文件。此外,一级分析管道还要求包含应用实验设计信息的BIDS符合事件文件,包括条件类型及其各自的开始和持续时间。一级分析包含的各个处理步骤包括:(1)收集预处理文件并建模相关信息;(2)模型规范和估计;(3)单变量对比度估计;(4)多变量分析的可选准备;(5)对比度空间归一化(图3)。所有相关步骤,即模型创建、估计和对比度计算,均在SPM12中执行。
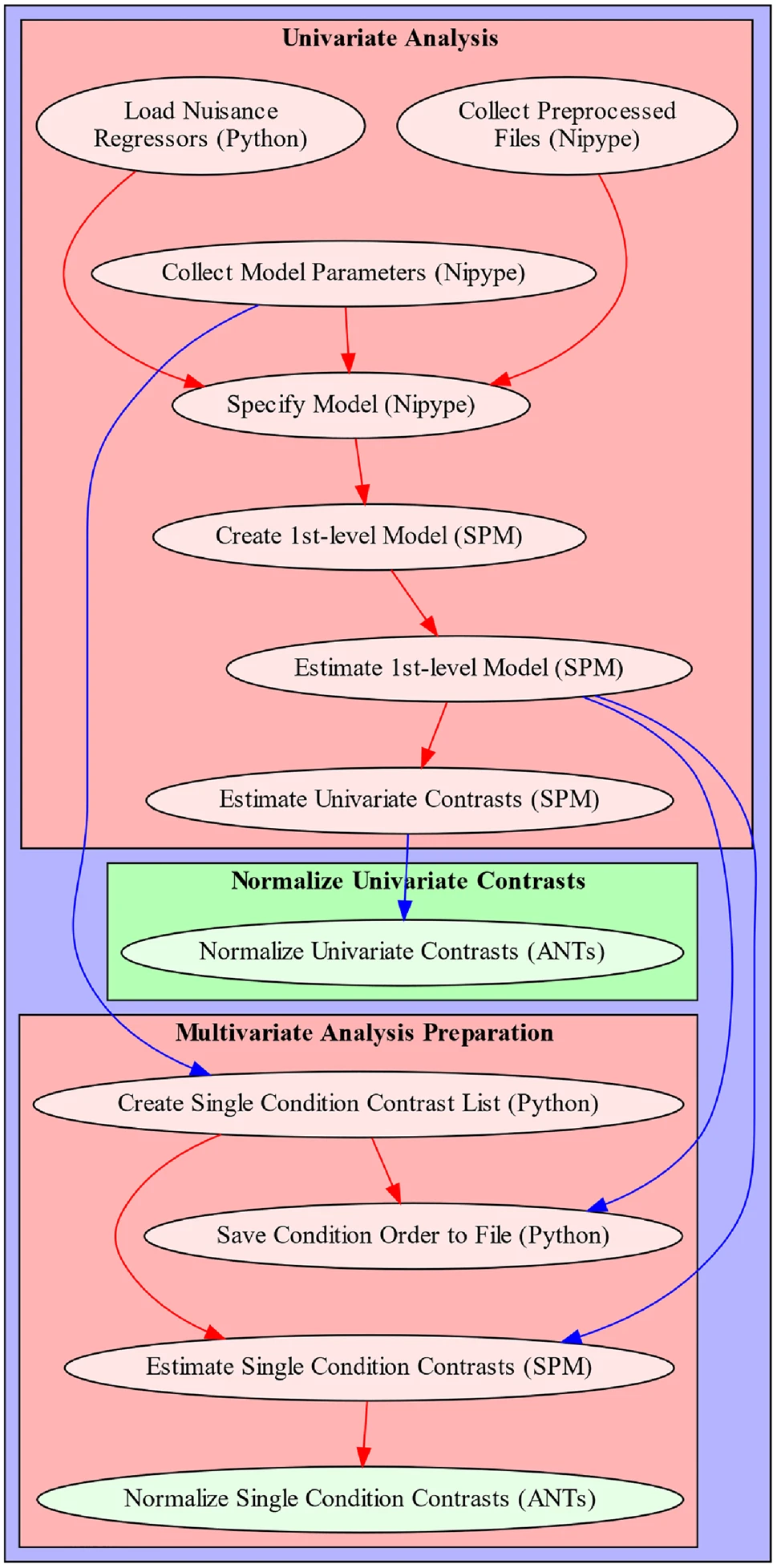
图3.fMRIflows的一级分析管道。
二级单变量分析
二级单变量分析管道包含在notebook的05_analysis_2nd-level.ipynb中,并使用JSON文件fmriflows_spec_analysis.json进行参数规范。用户可以指定一个概率值,作为模板空间中GM概率组织图的阈值,该阈值稍后用于模型估计。此外,用户可以指定统计对比的体素阈值和聚类阈值,以及用于创建输出表格和图形的相关AtlasReader参数。
二级单变量分析管道仅依赖于与一级单变量分析的估计对比。由于fMRIflows目前只实现了简单的单样本t检验,因此不需要进一步的对比规范。二级单变量分析中的各个处理步骤包括:(1)收集一级对比;(2)创建和估计二级模型;(3)对比度估计;(4)对比度的拓扑阈值;(5)使用AtlasReader创建结果。在一级分析中,所有相关的模型创建、估计和对比度计算均使用SPM12执行。所有结果均进行假阳性率(FPR)校正。
二级多变量分析
二级多变量分析管道包含在notebook的06_analysis_multivariate.ipynb中,并使用JSON文件fmriflows_spec_multivariate.json进行参数规范。用户可以定义一个分类器列表,用于多变量分析、计算探照灯的球体半径和步长。为了对探照灯结果进行二级分析,用户可以在经典的GLM方法(针对机会水平进行测试)和Stelzer等人(2013)推荐的基于排列的方法(可选择确定排列的数量)之间做出选择。此外,用户可以指定统计对比的体素阈值和聚类阈值,以及用于创建输出表格和图形的相关AtlasReader参数。
二级多变量分析管道依赖于一级多变量分析的估计对比度、包含相应对比度标签列表和二元分类标识符列表的关联CSV文件。与其他notebook相比,该notebook使用Python 2.7来适应PyMVPA v2.6.5的要求。二级多变量分析中包含的各个处理步骤包括:(1)PyMVPA分析所需的数据准备;(2)探照灯分类;(3)使用t检验计算组分析;(4)根据Stelzer等人(2013)的研究计算组分析;以及(5)使用AtlasReader创建结果。所有结果均进行了FPR校正。
fMRIflows基础结构和访问
fMRIflows的源代码可在GitHub(https://github.com/miykael/fmriflows)上获取,并根据BSD 3条款“新”或“修订”许可证进行授权。代码使用Python v3.7.2(https://www.python.org)编写,存储在Jupyter Notebooks v4.4.0中,并通过Docker v18.09.2(https://docker.com)容器分发,该容器可通过Docker Hub(https://hub.docker.com)公开获得。Docker的使用允许用户在任何主要的操作系统上运行fMRIflows,使用以下命令:docker run-it-p 9999:8888-v /home/user/ds001:/data miykael/fmriflows。
fMRIflows在各个处理步骤中可使用许多不同的软件包。使用的神经成像软件有:Nipype v1.1.9、FSL v5.0.9、ANTs v2.2.0、SPM12 v7219、AFNI v18.0.5、Nilearn v0.5、Nibabel v2.3.0、PyMVPA v2.6.5、Convert3D v1.1(https://sourceforge.net/p/c3d)、AtlasReader v0.1和PyBIDS v0.8。除了一些标准的Python库外,fMRIflows还使用Numpy,Scipy,Matplotlib,Pandas和Seaborn(http://seaborn.pydata.org)。
fMRIflows的验证
fMRIflows分两个阶段进行了验证。在第1阶段,通过将该工具箱应用于OpenNeuro.org上符合BIDS标准的不同类型的fMRI数据集,从而验证该工具箱的能力。对这一阶段的了解使我们能够改进代码库,并使fMRIflows对各种数据集具有鲁棒性。在第2阶段,将工具箱的性能与类似的神经成像预处理管道(如fMRIPrep,FSL和SPM)进行了比较。为了更好地了解fMRIflows与这些可比较的处理管道重叠或相异的地方,本研究考察了在三个不同数据集上运行的所有四个工具箱的预处理、被试水平和组水平的结果。
第1阶段:能力验证
为了调查工具箱初始实施的功能和缺陷,在不同的数据集上运行fMRIflows,这些数据集可通过OpenNeuro.org公开获得,也可以由研究者自行提供。这种方法允许探索具有不同时间和空间分辨率、信噪比、视场、时间层数量、扫描仪特征和其他序列参数(如加速因子和翻转角度)的数据集。
第2阶段:性能验证
为了验证fMRIflows的性能,本研究使用了三种不同的基于任务的fMRI数据集,并将其预处理过程与三种神经成像处理管道fMRIPrep,FSL和SPM进行了比较。对预处理、被试水平和组水平的输出进行了比较。由于FSL和SPM进行被试水平和组水平分析的方式存在差异,以及fMRIPrep中缺乏此类例程,所有用于性能验证的被试和组水平分析均使用相同的Nistats例程进行。
这三个数据集(见表1)都是在磁场强度为3T的扫描仪上采集的,并且在许多序列参数上有所不同,最显著的差异是记录时的时间分辨率。这一点尤其重要,因为本研究旨在强调正确处理时域滤波对于时间分辨率低于1000ms的数据集是至关重要的。
表1.用于验证fMRIflows的数据集概述。

数据集TR2000具有相对较低的时间采样和空间分辨率。它作为一个标准数据集,是用标准的EPI扫描序列记录的。数据集TR1000具有相当高的时间采样和空间分辨率,可作为一个高级数据集,使用了多波段加速技术的扫描序列进行记录。数据集TR600具有非常高的时间采样和中等的空间分辨率,可作为一个极端数据集,使用同步多层(SMS)加速技术的扫描序列记录。
使用基于默认参数的fMRIflows,fMRIPrep,FSL和SPM预处理管道,并且与它们的标准实现只有以下几点不同:(1)根据数据集中的主分辨率维度,将功能图像重采样为等距体素分辨率;(2)fMRIPrep的工作流程中不包括空间平滑,因此使用Nilearn方法和半高全宽(FWHM)为6mm的平滑核对预处理后的图像进行空间平滑,以保持图像的可比较性;(3)FSL管道中的解剖图像首先被裁剪为标准FOV,然后在启动FSL的FEAT之前使用FSL的BET进行脑提取;(4)对于FSL,采用12自由度的非线性扭曲方法和样条插值模型进行从结构空间到标准空间的归一化;(5)对于SPM,标准化的脑模板是其标准组织概率的脑TPM,而对于fMRIflows、fMRIPrep和FSL,标准化的脑模板是ICBM 2009c非线性非对称脑模板。
没有对这些工具箱进行统计推断,以防止引入软件特定偏差。使用Nistats、Nilearn和其他Python工具箱进行一级和二级分析,各工具箱之间仅在以下方面有所不同:(1)在一级分析期间添加到设计矩阵中的估计运动参数对于每个工具箱来说都是不同的,因为它们是基于特定于软件的预处理例程;(2)在fMRIflows的一级分析过程中,每次运行使用的volume数可能与其他方法略有不同,因为fMRIflows例程在预处理过程中会去除非稳态volume;(3)SPM在组分析过程中使用自身的组织概率图来创建局限于灰质体素的二元掩膜,而其他三个工具箱则使用ICBM 2009c灰质概率图代替。
为了比较工具箱之间的无阈值组统计图,研究者为每个成对预处理方法组合创建了一个 Bland-Altman 2D直方图。完整的参数列表、执行预处理的脚本、一级和二级分析以及创建单个图形的脚本可以在fMRIflows GitHub网址(https://github.com/miykael/fmriflows/tree/master/paper)上找到。在第2阶段验证生成的衍生图可以通过以下链接在NeuroVault上检查和下载:(1)预处理后的时间平均标准差图(https://identifiers.org/neurovault.collection:5645),(2)预处理后的时间信噪比(SNR)图(https://identifiers.org/neurovault.collection:5713),(3)二值化的一级激活计数图(https://identifiers.org/neurovault.collection:5647)(4)二级激活图(https://identifiers.org/neurovault.collection:5646)。
结果
fMRIflows处理管道获得的输出汇总
执行结构预处理管道后生成的输出
执行结构预处理管道后,为每个被试生成以下文件:(1)非均匀校正后的全脑图像,(2)提取的脑组织图像,(3)用于脑提取的二元掩膜,(4)灰质(GM)、白质(WM)、脑脊液(CSF)、颅骨和头部的组织概率图,(5)模板空间的归一化解剖图像,(6)被试空间的反归一化模板图像,(7)以及用于输出5和6的相应变换矩阵。每个结构预处理输出文件夹还包含(8)用于归一化的ICBM 2009c大脑模板,按要求的体素分辨率进行采样。除了这些文件之外,还生成了以下三个信息图:(1)组织分割,(2)脑提取和(3)解剖图像的空间归一化。这三个图的缩略版如图4所示。

图4.fMRIflows在执行结构预处理管道后生成的输出图汇总。
执行功能预处理管道后生成的输出
执行功能预处理管道后,分别为每个被试、每个功能运行和每个时域滤波生成以下文件:(1)指示哪些volume被检测为异常值的文本文件,(2)包含所有提取的混淆回归量的制表符分隔值(TSV)文件,(3)根据FSL的输出方案,包含六个运动参数回归量的文本文件,(4)用于大脑的二元掩膜,(5)用于结构和功能成分的噪声校正掩膜,(6)功能平均图像,以及(7)通过空间平滑法分离的完全预处理的功能图像。每个被试文件夹在(8)每次功能运行时都包含一个文本文件,表示运行开始时非稳态volume的数量。
以下是对功能预处理过程中fMRIflows估计的多个混淆点的详细描述:
基于运动参数的混淆:除了在预处理期间创建的头部运动参数外,fMRIflows还使用自定义脚本计算①运动参数的24参数Volterra扩展和②使用Nipype的逐帧位移(FD)。
基于全局信号的混淆:使用空间平滑前的功能图像计算混淆回归量,例如①DVARS,表示信号在时间差分后的空间标准差,使用Nipype来识别受运动影响的帧;②采用Nilearn软件绘制4条全局信号曲线,分别代表总脑容量(TV)、GM、WM和CSF的平均信号。
检测异常体积:用户可以指定FD、DVARS和TV、GM、WM和CSF中平均信号的六条信号曲线中的哪一条来识别异常体积(见图5A)。与整个时间过程中的z值标准差相比,这些体积在给定体积中的信号值波动较大。用户可以调整每条曲线的确切阈值,但对于FD、DVARS和TV信号,默认值设置为z=3.27。每个异常体积的识别号存储在一个文本文件中,在GLM模型估计过程中,一级管道可能会使用该文本文件来消除这些异常值对整体分析的影响,也称为删失。
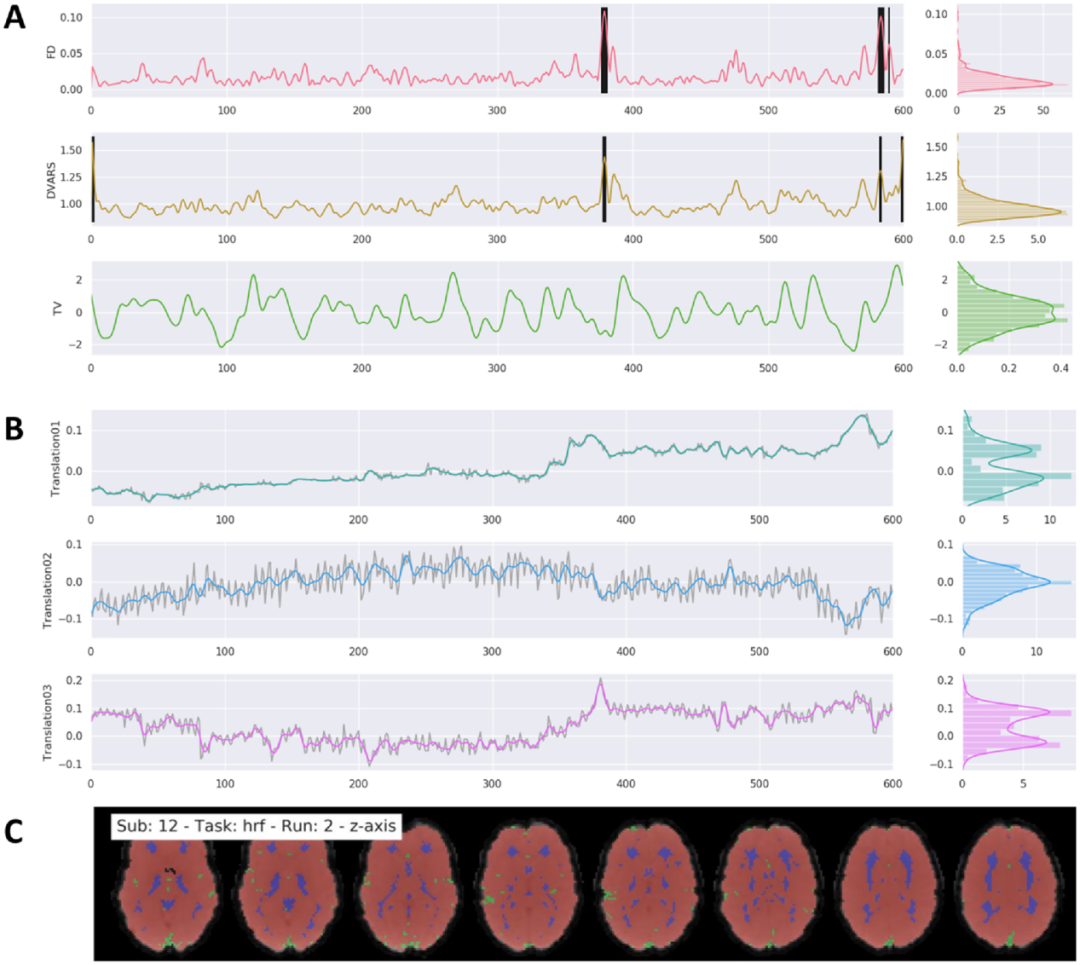
图5.fMRIflows在执行功能预处理管道后生成的常规输出图示例。
基于信号成分的混淆:使用时间滤波函数图像,执行两种不同的方法来提取可用于数据去噪或降维的成分。第一种方法称为CompCor,它使用主成分分析(PCA)来估计特定混淆区域内的主要噪声源。区域由其时间或解剖特征来定义。时间CompCor方法(tCompCor)将混杂的脑掩膜中变化最大的2%体素视为混淆源。解剖CompCor方法(aCompCor)将两次侵蚀的WM和CSF脑掩膜内的体素视为混淆源。用户可以指定应计算多少个aCompCor和tCompCor成分,但默认值分别设置为5个。第二种方法使用独立成分分析(ICA)在信号中执行源分离(图6)。使用Nilearn的CanICA例程,fMRIflows默认计算整个混淆掩膜中的前十个独立成分(该数量可由用户自定义)。用户需要恰当地评估是否存在残留伪影以及是否需要删除这些伪影。
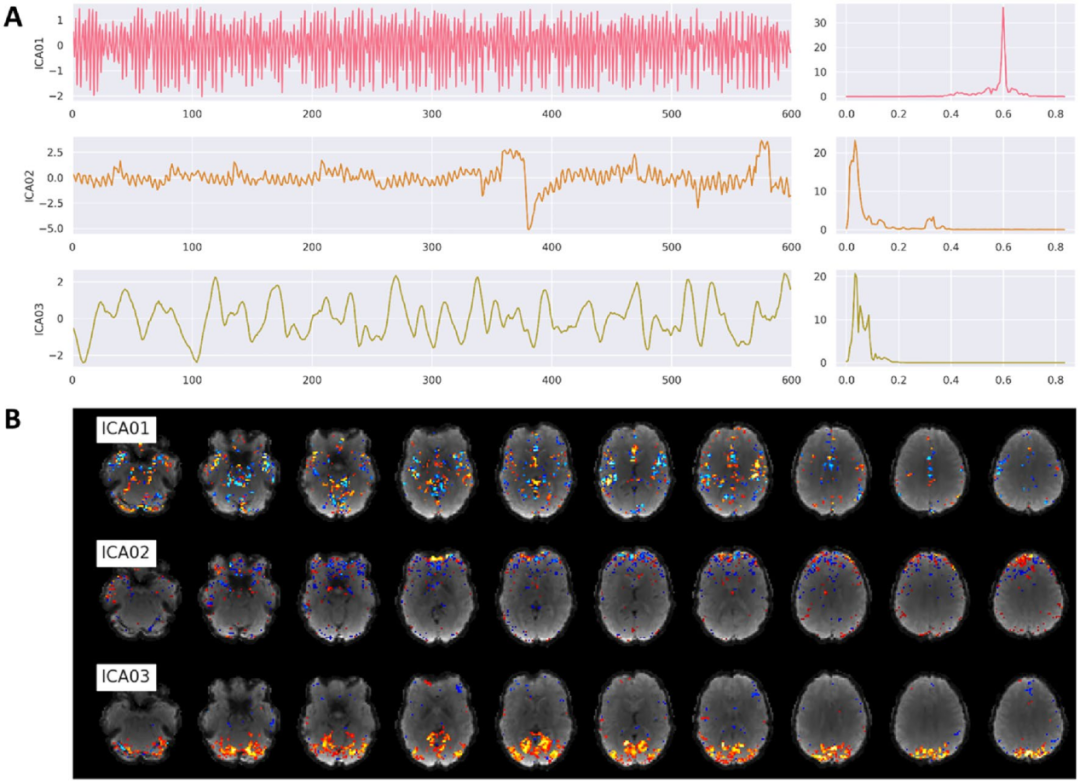
图6.fMRIflows在执行功能预处理管道后生成的ICA输出图示例。用于生成这些图形的数据集以600ms的TR记录,每次运行总共有600个volume。A.前三个ICA成分与功能图像随时间变化的相关性(左)以及x轴上频率对应的功率密度谱(右)。B.给定的ICA成分与前三个ICA成分之间的相关强度。
混淆信息的存储:功能预处理后计算的所有混淆曲线都存储在一个TSV文件中,以便于访问。
多样化的概览图集:为了能够目视检查执行功能预处理管道后生成的大量输出,fMRIflows创建了许多信息丰富的概览图。这些概述涵盖了用于头部运动矫正的运动参数、解剖和时间CompCor成分、FD、DVARS、TV、GM、WM和CSF中的平均信号,以及ICA成分。fMRIflows还创建了一个大脑概览图,显示了在功能预处理过程中应用不同掩膜的程度、ICA成分和单个体素信号之间的空间相关图,以及根据Power(2017)和Esteban等人(2019)绘制的地毯图。为了更好地可视化地毯图中的底层结构,时间序列轨迹按其与给定区域内平均信号的相关系数进行排序,允许2个volumes的正或负时滞。所有这些图的缩略版如图5、6和7所示。
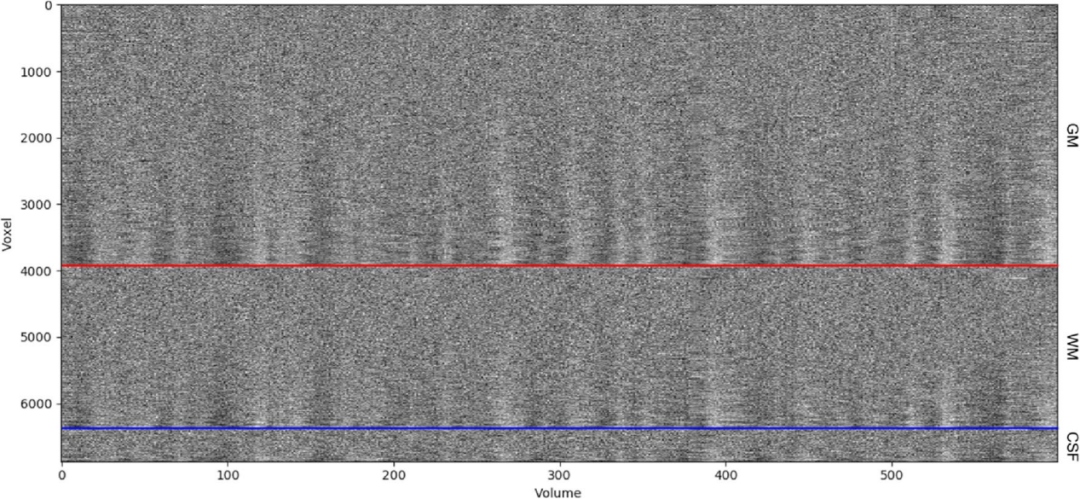
图7.fMRIflows在执行功能预处理管道后生成的地毯图示例。
执行一级分析管道后生成的输出
执行一级分析后,将生成以下文件用于单变量分析:(1)对比度和指定对比度的统计图,(2)包含与模型相关信息的SPM.mat文件,(3)一级模型中使用的设计矩阵的可视化,描绘刺激、运动和混淆回归量,以及(4)使用AtlasReader创建的在正负值最高2%处的每个对比度阈值估计的玻璃脑图,以提供对比度质量的总体概况。该notebook的多变量分析部分创建了:(1)每个条件和session都有一张对比图,之后可用作多变量分析的样本,以及(2)标识每个对比度条件的标签文件。
执行二级分析管道后生成的输出
执行二级单变量分析后,将针对应用的每个对比度以及空间和时间滤波器分别生成以下文件:(1)对比度和单样本t检验对比度的统计图,(2)包含与模型相关信息的SPM.mat文件,(3)具有相应AtlasReader输出的阈值统计图。执行二级多变量分析后,为每个指定的比较分别生成以下文件:(1)根据Stelzer等人(2013)研究中校正所需的特定于被试的排列文件,(2)通过自举法获得的组平均预测精度图以及对应的代表机会水平的特征图,(3)多重比较校正后的组平均预测精度图和(4)相应AtlasReader输出的阈值统计结果图。
第1阶段的结果:能力验证
由于扫描仪硬件、扫描协议、研究要求和记录图像人员的专业知识差异,fMRI数据集可以有许多不同的形状和形式。本研究在几个数据集上运行了fMRIflows,以确保它能够处理每个数据集固有的差异。接下来,研究者总结了在此过程中遇到的主要问题,并描述了如何解决每个问题。
图像定向
fMRIflow在预处理管道开始时将所有解剖和功能图像重新定向到RAS(右、前、上),以防止解剖和功能图像之间由于被试内的方向不匹配而无法进行共配准。
图像范围
一些数据集沿上下轴具有异常大的图像覆盖范围,这意味着它们的解剖图像通常也包含了参与者颈部的一部分。这可能导致某些神经成像常规的意外结果,因为它们没有测试过这种额外的组织覆盖。这在FSL的BET例程(难以找到大脑的中心和范围)或SPM的分割例程(依赖于整个体积内体素强度的分布)中最为明显。为了防止这些和其他不可预见的行为发生,fMRIflows使用FSL的robustfov例程将所有解剖图像限制在相同的空间范围内。
图像非均匀性
根据扫描序列协议或扫描仪硬件本身的不同,一些数据集可能包含强烈的图像强度非均匀性,这是由数据采集过程中的非均匀偏置场引起的。这可能会对许多不同的神经成像常规产生负面影响,在脑提取和图像分割中最为明显。为了解决这个问题,fMRIflows使用ANTs的N4BiasFieldCorrection例程,该例程允许分析具有低图像质量和强图像不均匀性的数据集。在结构预处理管道中,应用非均匀性校正来改善最终输出图像。在功能预处理管道中,非均匀性校正仅用于提高不同组织类型的估计和提取,并不直接改变最终输出图像中的值。
脑提取
本研究探索了不同的脑提取程序,以确保:(1)提取过程具有足够的鲁棒性来处理不同类型的数据集,(2)在去除非脑组织方面既不过于保守也不过于自由,以及(3)具有合理的总体计算时间。使用SPM的图像分割程序获得了最佳和最一致的结果,然后对GM,WM和CSF概率图进行特定的阈值分割和合并。FSL的BET不够稳健,无法在所有测试数据集上产生稳定的结果。虽然ANTs的Atropos获得了相当好的结果,但研究者选择了SPM,因为SPM的计算时间要快得多。
图像插值
对于归一化过程中的单次空间插值,研究者使用ANTs,并探索了NearestNeighbor、BSpline和LanczosWindowedSinc插值的效果。NearestNeighbor(最近邻插值)导致体素到体素值的转换看起来不自然。BSpline(B样条插值)总体上取得了良好的结果,但也存在一定的问题,特别是在数据集没有完全覆盖大脑的情况下,并且在非零体素的边界引入了一些涟漪低值波动效应。LanczosWindowedSinc插值通过最小化平滑效应并防止引入额外的混淆因素获得了最佳的结果,再次证实了fMRIPrep的观察结果。
第2阶段的结果:性能验证
fMRIflows的性能验证是在三个不同的任务态fMRI数据集上进行的,如表1所示。将fMRIflows的预处理与其他神经成像处理管道(如fMRIPrep,FSL和SPM)进行比较。为了更好地了解不同工具箱之间的性能差异,并强调在处理具有高时间分辨率fMRI数据集时进行充分的时间滤波的重要性,研究者还测试了使用和不使用0.2Hz低通时间滤波器的fMRIflows预处理管道。
功能预处理后的估计空间平滑度
对功能图像进行重采样的每个预处理步骤,例如时间层校正、运动校正、空间或时间插值都有可能增加数据的空间平滑性。在预处理过程中引入的平滑度越低,数据就越接近其初始版本。研究者使用AFNI的3dFWHMx来估计预处理后每个功能图像的平均空间平滑度(FWHM),以比较应用于原始数据的数据操作量(见图8)。由于此FWHM值取决于给定数据集的体素分辨率,因此按体素体积对其进行归一化,以实现每1mm3的共同FWHM值。
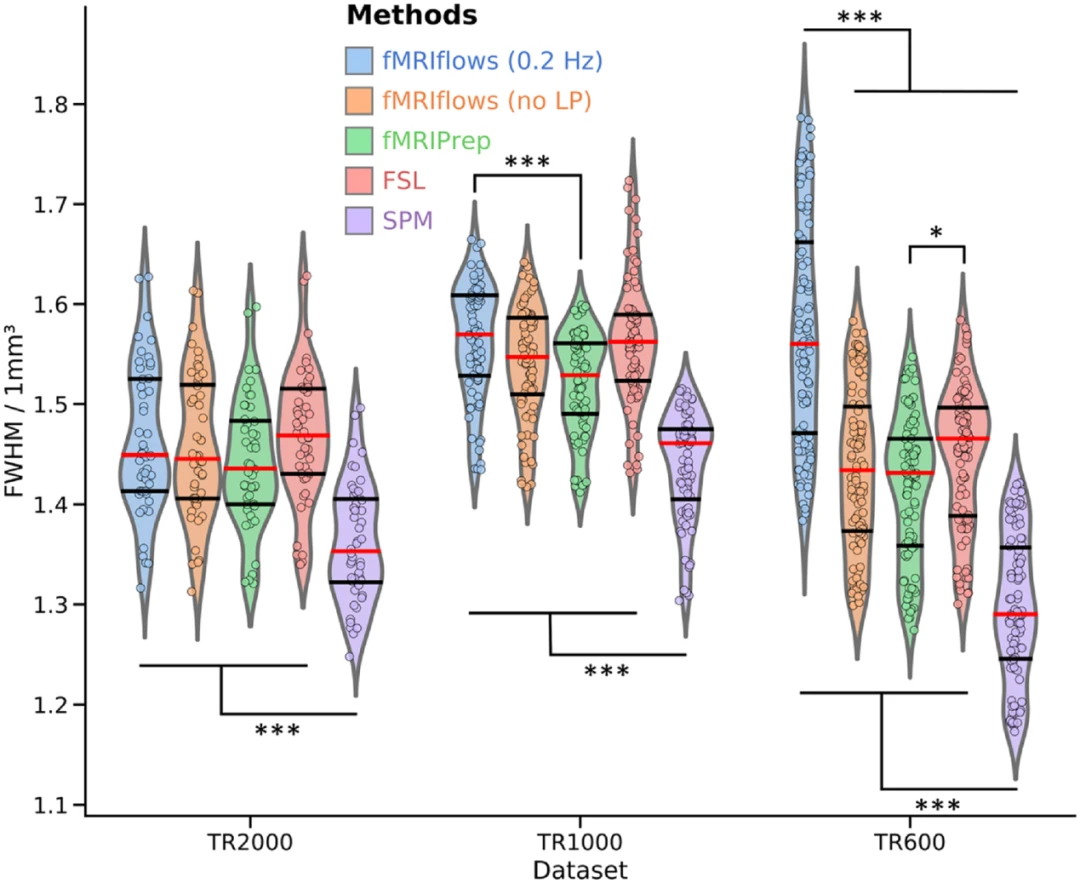
图8.用不同方法对三个不同数据集进行功能预处理后估计空间平滑度。
总体而言,使用fMRIflows(没有进行低通滤波时)预处理后估计的空间平滑度与使用fMRIPrep时相当,而SPM总体上显著降低,FSL略高。图8中的所有结果都使用Tukey多重比较检验进行校正。与SPM的差异可能是由于SPM的预处理管道中涉及的重采样步骤较少。与FSL的差异可能是由于图像重采样期间使用的插值方法有关。FSL预处理管道使用样条插值,而fMRIflows和fMRIPrep使用LanczosWindowedSinc插值,众所周知,它可以最小化插值期间的平滑度。与其他方法相比,在fMRIflows预处理过程中应用0.2Hz的低通时间滤波器使TR600数据集的空间平滑度显著提高。在TR1000数据集上也可能存在这种效果。然而,经过低通滤波和未经过低通滤波预处理的fMRIflows之间的差异并不显著。这种使用低通滤波器的方法增加的空间平滑度是有意义的,因为低通时间滤波器本身的目标是平滑时间序列值。这种时间上的平滑也强制增加了每个时间点上的空间平滑。
空间归一化的性能检查
根据各预处理功能图像的时间平均图计算出各总体的标准差图,以比较不同预处理方法在三个不同数据集上的空间归一化性能(如图9所示)。
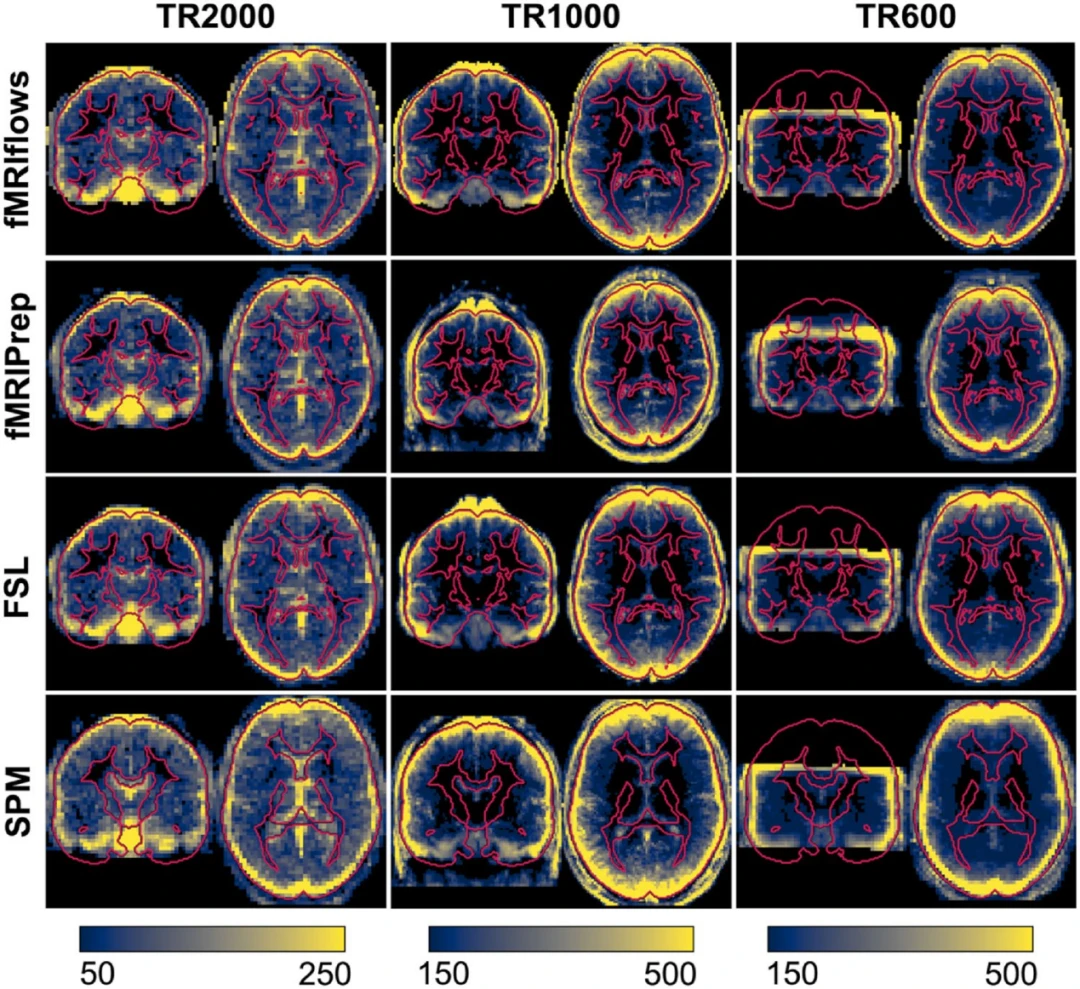
图9.使用不同的功能预处理方法在三个不同数据集上的标准差图。对TR2000(左)、TR1000(中)和TR600(右)数据集分别使用fMRIflows(使用0.2Hz的低通时间滤波器和不使用低通滤波器看起来相同)、fMRIPrep、FSL和SPM进行预处理。被试间变异性高的区域用黄色显示,而被试间变异性低的区域用蓝色显示。大脑和皮层下白质区域的轮廓用红色标出,基于ICBM 2009c大脑模板,除了SPM的分析是基于其组织概率图模板。
fMRIflows和fMRIPrep预处理后的平均标准差图非常相似,这并不奇怪,因为fMRIflows使用相同的ANTs归一化例程和非常相似的参数。主要的区别在于fMRIflows对功能图像进行了脑提取,而fMRIPrep没有执行此步骤。
预处理后的时间信噪比(tSNR)
根据Smith等人(2013)计算了基于体素的时间SNR,以评估预处理后数据中包含的信息量。该测量值可作为比较不同预处理方法的粗略估计,但不允许在数据集之间进行直接比较,因为tSNR值是一种相对测量值,高度依赖于所呈现的范式、功能图像的初始空间和时间分辨率,以及MRI扫描序列的特定参数(如加速因子)。使用Nipype的TSNR例程,首先去除每个功能图像中的二次多项式漂移,并通过计算每个体素的时间均值除以其时间标准差,并乘以给定运行中记录的时间点数量的平方根来估计tSNR映射。通过平均所有被试的tSNR图,得到每个数据集的每种预处理方法的一般tSNR图(图10)。
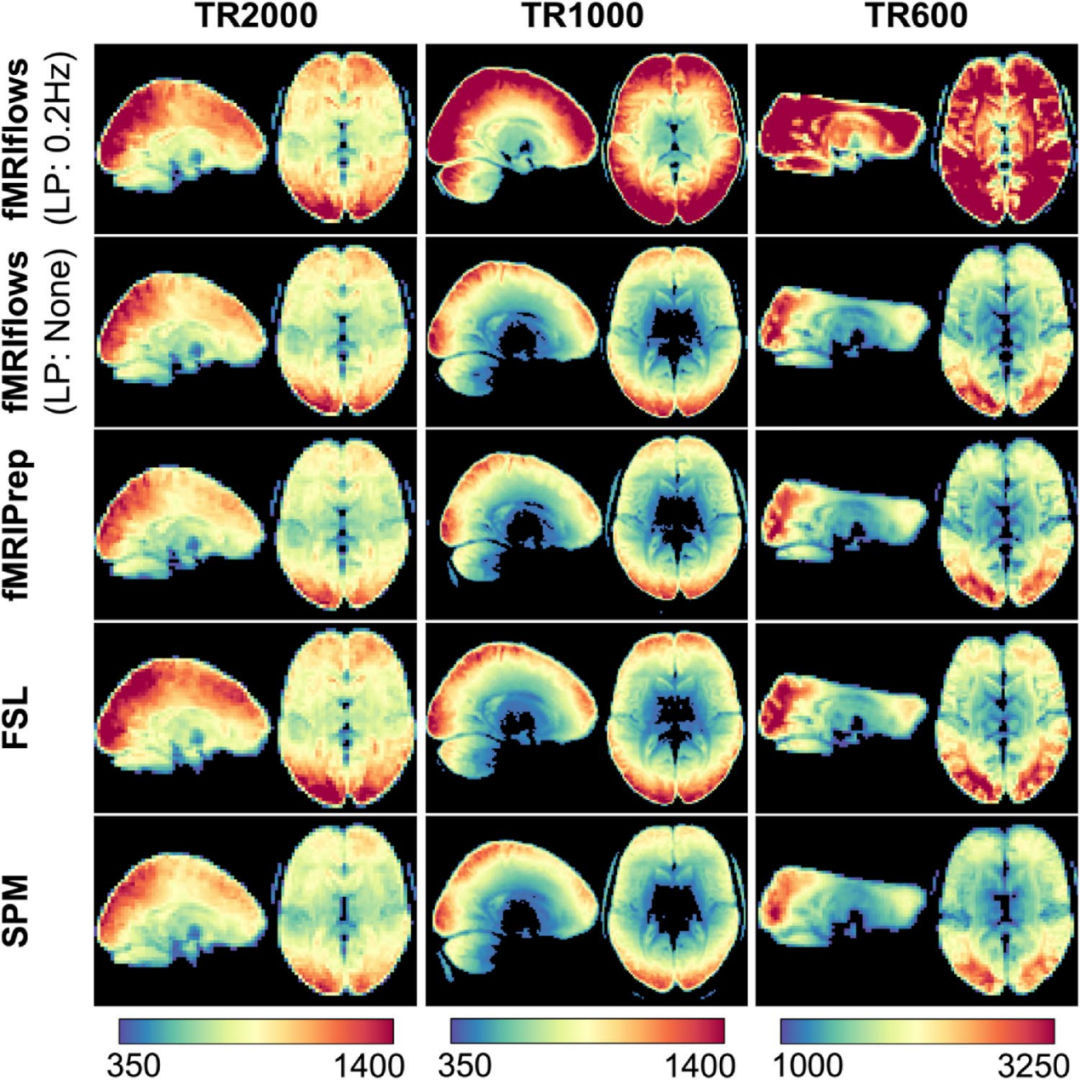
图10.使用不同的功能预处理方法在三个不同数据集上的时间信噪比图。
一般来说,不使用时间低通滤波器的fMRIflows预处理与使用fMRIPrep预处理获得了相似的平均tSNR图。总体而言,使用FSL进行预处理导致平均tSNR值略有增加,而使用SPM进行预处理导致平均tSNR图略有下降。在所有三个数据集上额外应用0.2Hz的低通滤波器使得fMRIflows进行预处理后的tSNR值增加。时间分辨率越高(如数据集TR1000和TR600),这种效果越明显。
一级分析后的性能检查
为了研究不同预处理方法对一级分析的影响,研究者使用Nistats进行了被试内统计分析。使用一般线性模型(GLM)估计激活图。使用Nilearn,且FWHM为6mm的内核对输入数据进行平滑处理。预处理方法和数据集之间的分析管道尽可能保持一致,仅在数据集包含的时间点数量和估计的运动参数上有所不同。每个参与者的统计图在z=3.09处二值化,对应于p<0.001的单侧检验值。这些地图的总体均值如图11所示。
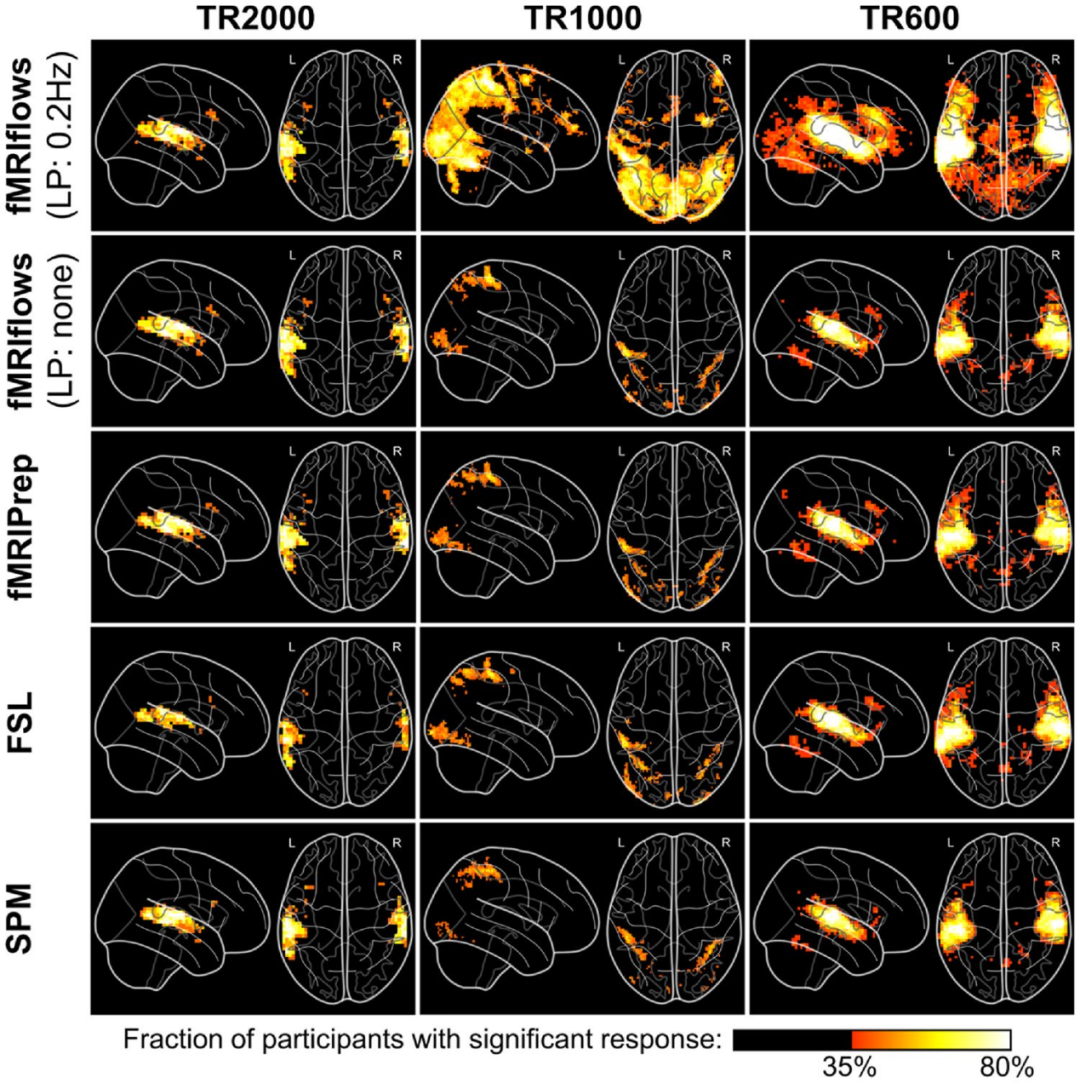
图11.使用不同的功能预处理方法进行二值化的激活图,p<0.001。
结果表明,对于所有三个数据集,不使用低通滤波器的fMRIflows方法、fMRIPrep方法、FSL方法和SPM方法之间的阈值激活计数映射之间没有太大差异。然而,与其他预处理方法相比,使用具有0.2Hz低通滤波器的fMRIflows进行预处理,大幅增加了数据集TR1000和TR600的阈值激活计数图的大小和分数值。因此,适当的时间滤波显著提高了更高时间分辨率数据集的统计量。
二级分析后的性能检查
为了研究不同预处理方法对二级分析的影响,研究者使用Nistats进行了被试间统计分析,并对每种预处理方法和数据集进行了单样本t检验。然后,使用Bland-Altman 2D直方图在体素水平上对每种分析的非阈值组水平T统计图进行相互比较,见图12。
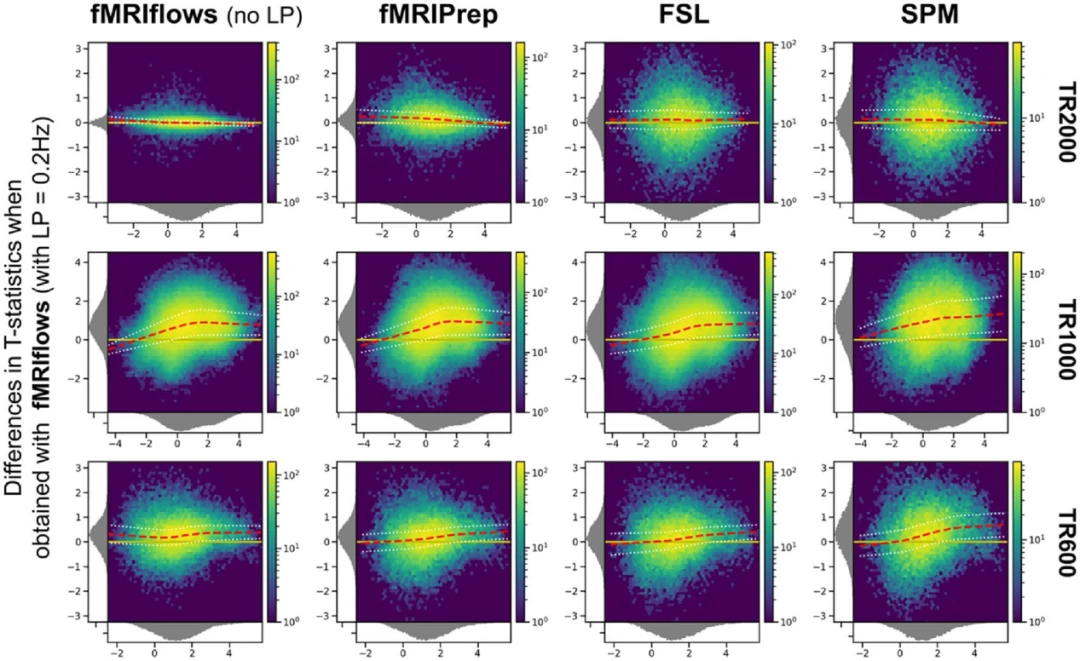
图12.多种处理方法在三个不同数据集上的Bland-Altman 2D直方图。
图12所示的结果表明,对于TR2000数据集的分析,使用0.2Hz低通滤波器的fMRIflows进行预处理与其他四种方法之间没有明显的差异。y方向上变异性的增加表明体素与体素的对应关系降低,这或许可以由不同的空间归一化实现来解释。平均水平密度值(虚线)接近于零线(水平实线)的事实表明,不同的预处理方法导致了与TR2000数据集具有可比性的组水平结果。TR1000和TR600数据集的Bland-Altman图显示,与任何其他方法相比,当使用带有0.2Hz低通滤波器的fMRIflows进行预处理时,t统计量明显增加。t值越高,这种效应越强。
结论
fMRIflows是一个全自动的fMRI分析管道,可以执行最先进的预处理,包括一级和二级单变量分析以及多变量分析。这种自主方法的目标是提高分析的客观性,最大限度地提高透明度,促进易用性,并为每位研究人员(包括神经影像领域以外的用户)提供可访问和更新的分析方法。与其他神经成像软件/管道(如fMRIPrep、FSL和SPM)相比,fMRIflows在预处理后的SNR、被试内t统计和被试间t统计方面取得了相当或更好的结果。该软件的进一步开发将包括:①在一级和二级建模中摆脱对SPM的依赖;②使用更灵活的FitLins工具箱(https://github.com/poldracklab/fitlins),使其结果符合BIDS统计模型提案(BEP002);以及③实现fMRIflows BIDS-App以进一步提高工具箱的可访问性。
原文:Notter, M.P., Herholz, P., Da Costa, S. et al. fMRIflows: A Consortium of Fully Automatic Univariate and Multivariate fMRI Processing Pipelines. Brain Topogr (2022). https://doi.org/10.1007/s10548-022-00935-8