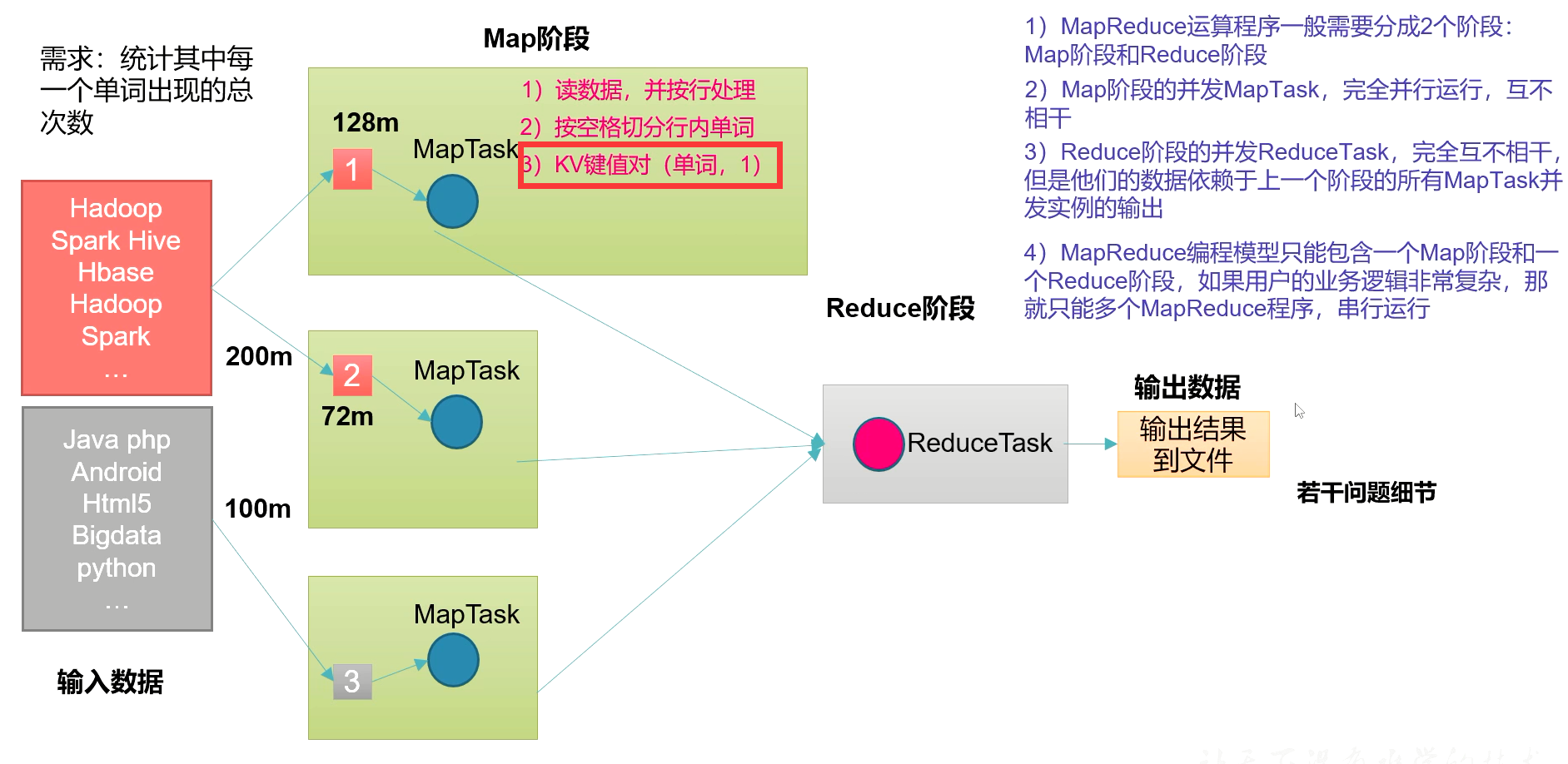
ps.实际生产环境中并不会使用mapReduce,而是spark和flink,但是它可以建立分布式的思想。
ps.基本流程:一般都是在代码层面引入hadoop依赖,然后在windows环境下进行代码编写测试,没有问题的话,把代码打包成jar包,然后拖入xShell,利用liunx执行测试.
(1) 数据序列化的类型:
Boolean
BooleanWritable