Kubernetes 笔记(15)— 应用保障、容器资源配额、容器状态探针概念及使用

作为 Kubernetes 里的核心概念和原子调度单位,Pod 的主要职责是管理容器,以逻辑主机、容器集合、进程组的形式来代表应用,它的重要性是不言而喻的。
在上层 API 对象的基础上,一起来看看在 Kubernetes 里配置 Pod 的两种方法:资源配额 Resources、检查探针 Probe,它们能够给 Pod 添加各种运行保障,让应用运行得更健康。
1. 容器资源配额
前面我们提到创建容器有三大隔离技术:namespace、cgroup、chroot。其中的 namespace 实现了独立的进程空间,chroot 实现了独立的文件系统,但唯独没有看到 cgroup 的具体应用。
cgroup 的作用是管控 CPU、内存,保证容器不会无节制地占用基础资源,进而影响到系统里的其他应用。
不过,容器总是要使用 CPU 和内存的,该怎么处理好需求与限制这两者之间的关系呢?
Kubernetes 的做法与 PersistentVolumeClaim 用法有些类似,就是容器需要先提出一个“书面申请”,Kubernetes 再依据这个“申请”决定资源是否分配和如何分配。
但是 CPU、内存与存储卷有明显的不同,因为它是直接“内置”在系统里的,不像硬盘那样需要“外挂”,所以申请和管理的过程也就会简单很多。
具体的申请方法很简单,只要在 Pod 容器的描述部分添加一个新字段 resources 就可以了,它就相当于申请资源的 Claim。
apiVersion: v1
kind: Pod
metadata:name: ngx-pod-resourcesspec:containers:- image: nginx:alpinename: ngxresources:requests:cpu: 10mmemory: 100Milimits:cpu: 20mmemory: 200Mi
这个 YAML 文件定义了一个 Nginx Pod,我们需要重点学习的是 containers.resources,它下面有两个字段:
requests意思是容器要申请的资源,也就是说要求Kubernetes在创建Pod的时候必须分配这里列出的资源,否则容器就无法运行。limits意思是容器使用资源的上限,不能超过设定值,否则就有可能被强制停止运行。
在请求 cpu 和 memory 这两种资源的时候,你需要特别注意它们的表示方式。
内存的写法和磁盘容量一样,使用 Ki、Mi、Gi 来表示 KB、MB、GB,比如 512Ki、100Mi、0.5Gi 等。
而 CPU 因为在计算机中数量有限,非常宝贵,所以 Kubernetes 允许容器精细分割 CPU,即可以 1 个、2 个地完整使用 CPU,也可以用小数 0.1、0.2 的方式来部分使用 CPU。这其实是效仿了 UNIX“时间片”的用法,意思是进程最多可以占用多少 CPU 时间。
不过 CPU 时间也不能无限分割,Kubernetes 里 CPU 的最小使用单位是 0.001,为了方便表示用了一个特别的单位 m,也就是 milli“毫”的意思,比如说 500m 就相当于 0.5。
现在我们再来看这个 YAML,你就应该明白了,它向系统申请的是 1% 的 CPU 时间和 100MB 的内存,运行时的资源上限是 2%CPU 时间和 200MB 内存。有了这个申请,Kubernetes 就会在集群中查找最符合这个资源要求的节点去运行 Pod。
下面是我在网上找的一张动图,Kubernetes 会根据每个 Pod 声明的需求,像搭积木或者玩俄罗斯方块一样,把节点尽量“塞满”,充分利用每个节点的资源,让集群的效益最大化。

你可能会有疑问:如果 Pod 不写 resources 字段,Kubernetes 会如何处理呢?
这就意味着 Pod 对运行的资源要求“既没有下限,也没有上限”,Kubernetes 不用管 CPU 和内存是否足够,可以把 Pod 调度到任意的节点上,而且后续 Pod 运行时也可以无限制地使用 CPU 和内存。
我们课程里是实验环境,这样做是当然是没有问题的,但如果是生产环境就很危险了,Pod 可能会因为资源不足而运行缓慢,或者是占用太多资源而影响其他应用,所以我们应当合理评估 Pod 的资源使用情况,尽量为 Pod 加上限制。
看到这里估计你会继续追问:如果预估错误,Pod 申请的资源太多,系统无法满足会怎么样呢?
让我们来试一下吧,先删除 Pod 的资源限制 resources.limits,把 resources.request.cpu 改成比较极端的“10”,也就是要求 10 个 CPU:
...resources:requests:cpu: 10
然后使用 kubectl apply 创建这个 Pod,你可能会惊奇地发现,虽然我们的 Kubernetes 集群里只有 3 个 CPU,但 Pod 也能创建成功。
不过我们再用 kubectl get pod 去查看的话,就会发现它处于 Pending状态,实际上并没有真正被调度运行:

使用命令 kubectl describe 来查看具体原因,会发现有这么一句提示:

这就很明确地告诉我们 Kubernetes 调度失败,当前集群里的所有节点都无法运行这个 Pod,因为它要求的 CPU 实在是太多了。
2. 什么是容器状态探针
现在,我们使用 resources 字段加上资源配额之后,Pod 在 Kubernetes 里的运行就有了初步保障,Kubernetes 会监控 Pod 的资源使用情况,让它既不会“饿死”也不会“撑死”。
但这只是最初级的运行保障,如果你开发或者运维过实际的后台服务就会知道,一个程序即使正常启动了,它也有可能因为某些原因无法对外提供服务。其中最常见的情况就是运行时发生“死锁”或者“死循环”的故障,这个时候从外部来看进程一切都是正常的,但内部已经是一团糟了。
所以,我们还希望 Kubernetes 这个“保姆”能够更细致地监控 Pod 的状态,除了保证崩溃重启,还必须要能够探查到 Pod 的内部运行状态,定时给应用做“体检”,让应用时刻保持“健康”,能够满负荷稳定工作。
那应该用什么手段来检查应用的健康状态呢?
因为应用程序各式各样,对于外界来说就是一个黑盒子,只能看到启动、运行、停止这三个基本状态,此外就没有什么好的办法来知道它内部是否正常了。
所以,我们必须把应用变成灰盒子,让部分内部信息对外可见,这样 Kubernetes 才能够探查到内部的状态。
这么说起来,检查的过程倒是有点像现在我们很熟悉的核酸检测,Kubernetes 用一根小棉签在应用的“检查口”里提取点数据,就可以从这些信息来判断应用是否“健康”了,这项功能也就被形象地命名为“探针”(Probe),也可以叫“探测器”。
Kubernetes 为检查应用状态定义了三种探针,它们分别对应容器不同的状态:
Startup,启动探针,用来检查应用是否已经启动成功,适合那些有大量初始化工作要做,启动很慢的应用。Liveness,存活探针,用来检查应用是否正常运行,是否存在死锁、死循环。Readiness,就绪探针,用来检查应用是否可以接收流量,是否能够对外提供服务。
你需要注意这三种探针是递进的关系:应用程序先启动,加载完配置文件等基本的初始化数据就进入了 Startup 状态,之后如果没有什么异常就是 Liveness 存活状态,但可能有一些准备工作没有完成,还不一定能对外提供服务,只有到最后的 Readiness 状态才是一个容器最健康可用的状态。
初次接触这三种状态可能有点难理解,我画了一张图,你可以看一下状态与探针的对应关系:

那 Kubernetes 具体是如何使用状态和探针来管理容器的呢?
如果一个 Pod 里的容器配置了探针,Kubernetes 在启动容器后就会不断地调用探针来检查容器的状态:
- 如果
Startup探针失败,Kubernetes会认为容器没有正常启动,就会尝试反复重启,当然其后面的Liveness探针和Readiness探针也不会启动。 - 如果
Liveness探针失败,Kubernetes就会认为容器发生了异常,也会重启容器。 - 如果
Readiness探针失败,Kubernetes会认为容器虽然在运行,但内部有错误,不能正常提供服务,就会把容器从Service对象的负载均衡集合中排除,不会给它分配流量。
知道了 Kubernetes 对这三种状态的处理方式,我们就可以在开发应用的时候编写适当的检查机制,让 Kubernetes 用“探针”定时为应用做“体检”了。
在刚才图的基础上,我又补充了 Kubernetes 的处理动作,看这张图你就能很好地理解容器探针的工作流程了:

3. 如何使用容器状态探针
如何在 Pod 的 YAML 描述文件里定义探针。
startupProbe、livenessProbe、readinessProbe 这三种探针的配置方式都是一样的,关键字段有这么几个:
periodSeconds,执行探测动作的时间间隔,默认是 10 秒探测一次。timeoutSeconds,探测动作的超时时间,如果超时就认为探测失败,默认是 1 秒。successThreshold,连续几次探测成功才认为是正常,对于startupProbe和livenessProbe来说它只能是 1。failureThreshold,连续探测失败几次才认为是真正发生了异常,默认是 3 次。
至于探测方式,Kubernetes 支持 3 种:Shell、TCP Socket、HTTP GET,它们也需要在探针里配置:
exec,执行一个Linux命令,比如ps、cat等等,和container的command字段很类似。tcpSocket,使用TCP协议尝试连接容器的指定端口。httpGet,连接端口并发送HTTP GET请求。
要使用这些探针,我们必须要在开发应用时预留出“检查口”,这样 Kubernetes 才能调用探针获取信息。这里我还是以 Nginx作为示例,用 ConfigMap 编写一个配置文件:
# ngx-conf.yml
apiVersion: v1
kind: ConfigMap
metadata:name: ngx-confdata:default.conf: |server {listen 80;location = /ready {return 200 'I am ready';}}
在这个配置文件里,我们启用了 80 端口,然后用 location 指令定义了 HTTP 路径 /ready,它作为对外暴露的“检查口”,用来检测就绪状态,返回简单的 200 状态码和一个字符串表示工作正常。
现在我们来看一下 Pod 里三种探针的具体定义:
# ngx-pod-probe.ymlapiVersion: v1
kind: Pod
metadata:name: ngx-pod-probespec:volumes:- name: ngx-conf-volconfigMap:name: ngx-confcontainers:- image: nginx:alpinename: ngxports:- containerPort: 80volumeMounts:- mountPath: /etc/nginx/conf.dname: ngx-conf-volstartupProbe:periodSeconds: 1exec:command: ["cat", "/var/run/nginx.pid"]livenessProbe:periodSeconds: 10tcpSocket:port: 80readinessProbe:periodSeconds: 5httpGet:path: /readyport: 80
StartupProbe使用了Shell方式,使用cat命令检查Nginx存在磁盘上的进程号文件(/var/run/nginx.pid),如果存在就认为是启动成功,它的执行频率是每秒探测一次。LivenessProbe使用了TCP Socket方式,尝试连接Nginx的 80 端口,每 10 秒探测一次。ReadinessProbe使用的是HTTP GET方式,访问容器的/ready路径,每 5 秒发一次请求。
现在我们用 kubectl apply 创建这个 Pod,然后查看它的状态:
kubectl apply -f ngx-conf.yml
kubectl apply -f ngx-pod-probe.yml

当然,因为这个 Nginx 应用非常简单,它启动后探针的检查都会是正常的,你可以用 kubectl logs 来查看 Nginx 的访问日志,里面会记录 HTTP GET 探针的执行情况:
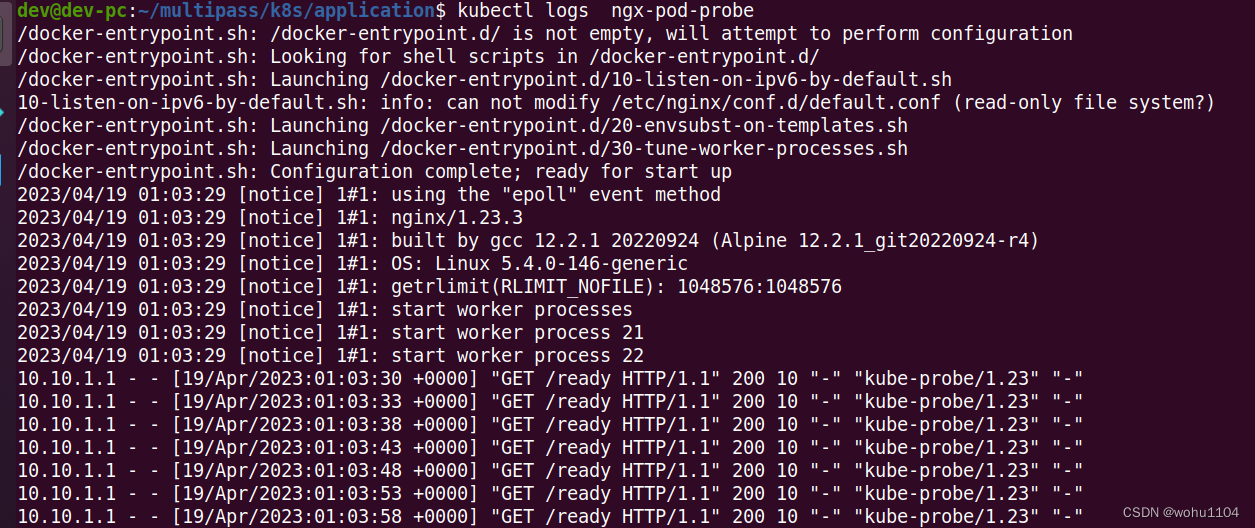
从截图中你可以看到,Kubernetes 正是以大约 5 秒一次的频率,向 URI /ready 发送 HTTP 请求,不断地检查容器是否处于就绪状态。
为了验证另两个探针的工作情况,我们可以修改探针,比如把命令改成检查错误的文件、错误的端口号:
startupProbe:exec:command: ["cat", "nginx.pid"] #错误的文件livenessProbe:tcpSocket:port: 8080 #错误的端口号
然后我们重新创建 Pod 对象,观察它的状态。
当 StartupProbe 探测失败的时候,Kubernetes 就会不停地重启容器,现象就是 RESTARTS 次数不停地增加,而 livenessProbe 和 readinessProbePod 没有执行,Pod 虽然是 Running 状态,也永远不会 READY:

在 startupProbe 或 livenessProbe 探测失败之后,pod 的 status 初始都是 running 。不过,在容器重启几次之后,pod 的status 会变为 CrashLoopBackOff , 如果 startupProbe 和 livenessProbe 探测成功,readinessProbe 探测失败,pod 的 ready 一直是0/1,status 一直是 running ,当然,也不会重启 。
因为 failureThreshold 的次数默认是三次,所以 Kubernetes 会连续执行三次 livenessProbe TCP Socket 探测,每次间隔 10 秒,30 秒之后都失败才重启容器:
将 readinessProbe 修改为错误的路径,看看它失败时 Pod 会是什么样的状态。
readinessProbe:periodSeconds: 5httpGet:path: /ready11 # 错误的路径port: 80

使用 kubectl describe pod ngx-pod-probe 查看如下,虽然探针失败,但是不会重启,ready 状态一直为 0/1。

4. 总结
今天我们学习了两种为 Pod 配置运行保障的方式:Resources 和 Probe。Resources 就是为容器加上资源限制,而 Probe 就是主动健康检查,让 Kubernetes 实时地监控应用的运行状态。
- 资源配额使用的是
cgroup技术,可以限制容器使用的CPU和内存数量,让Pod合理利用系统资源,也能够让Kubernetes更容易调度Pod。 Kubernetes定义了Startup、Liveness、Readiness三种健康探针,它们分别探测应用的启动、存活和就绪状态。- 探测状态可以使用
Shell、TCP Socket、HTTP Get三种方式,还可以调整探测的频率和超时时间等参数。
-
现在的服务器都是多核
CPU,在kubernetes中的CPU指的是逻辑核CPU,也就是操作系统里能够看到的CPU,除了CPU和内存,Pod的resources字段还可以为容器配置临时存储空间和自定义扩展资源。 -
StartProbe和livenessProbe探测失败后的动作其实是由字段restartPolicy决定的,它的默认值OnFailure就是重启容器 -
探针可以配置
initialDelaySeconds字段,表示容器启动后多久才执行探针动作,适用于某些启动比较慢的应用,它的默认值为 0。 -
在容器里还可以配置
lifecycle字段,在启动后和终止前安装两个钩子postStart,preStop执行shell命令或者发送http请求做一些初始化和收尾工作。 -
postStart,preStop感觉可以做 CI/CD,或者各种 webhock 钩子,或者简单的通知。
5. 问答
1、你能够解释一下 Liveness 和 Readiness 这两种探针的区别吗?
Liveness 和 Readiness 都是循环探测,Liveness 探测失败会重启,而 Readiness 探测失败不会重启,可以从 Pod 状态 看出重启次数。 两者都可以单独使用,这时差异不大。 如果同时使用两者,Liveness 主要是确认应用运行着或者说活着,而 Readiness 是确认应用提供着服务或者说服务就绪着(可以接收流量)。
Startup、Liveness、Readiness三种探针是按顺序执行还是并行呢?
Startup成功之后才能执行后两个探针,后面两个是并行的。
2、你认为 Shell、TCP Socket、HTTP GET 这三种探测方式各有什么优缺点?
Shell 是从容器内部探测,TCP Socket 和 HTTP GET 都是在容器外部探测。 TCP Socket 基于端口的探测,端口打开即成功;HTTP GET 更丰富些,可以是端口 + 路径。
Liveness指的是进程是否存在,Readiness则是指是否能够正常提供服务,所以可以使用 tcp协议检测Liveness,进程存在端口即存在,使用 http检测服务,只有服务启动了参能够相应请求。
Shell是系统内进程级别交互,所以只能够本地访问,Tcp可以跨机器访问,但是访问的级别比较低,不能够获得顶层数据,Http是协议层数据,可以拿到应用层的服务信息,但是关注顶层信息,底层故障,顶层无法提供有价值信息了。