HIVE SQL 进行 Join 和 group by的具体原理及分区方式

HIVE SQL 实现Join和group by 具体原理
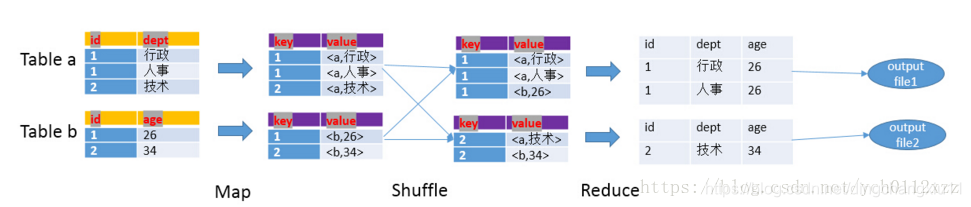
1、JOIN
在map的输出value中为不同表的数据打上tag标记,在reduce阶段根据tag判断数据来源。MapReduce的过程如下:
2、 GROUP BY
HIVE SQL 实现Join和group by 的分区原理
1、JOIN
在join操作中,两个数据集需要根据相同的键进行连接。在默认情况下,这些键是用来对数据进行哈希分区的。因此,具有相同键的记录将被发送到同一个reducer节点上以进行处理。这种方式可以确保所有具有相同键的数据都在同一个地方进行处理,以便进行连接操作。
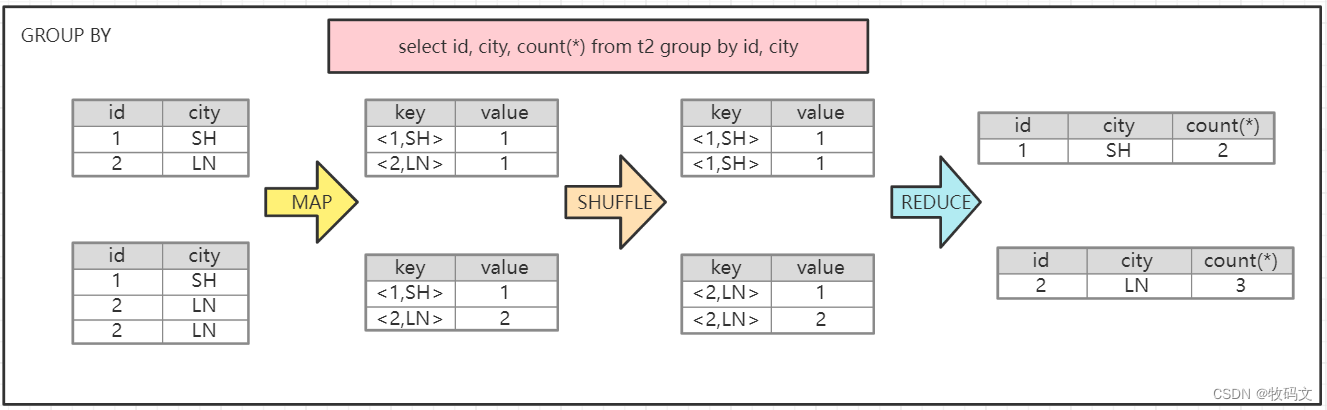
2、GROUP BY
在group by中,要求将相同键的所有记录合并到一起进行汇总计算。在默认情况下,这些键也会用于哈希分区。与join不同的是,在group by操作中,每个reducer节点都负责处理一组键(预聚合),而不是处理所有具有相同键的记录。这种方式可以提高并行度,从而加速处理速度。