【IDEA】数据湖 Hudi 0.12.0 基础使用

前言
集群系统:CentOS 7.5
服务器信息:
| 服务器 | 角色 | IP |
|---|---|---|
| hadoop104服务器 | Master | 192.168.0.104 |
| hadoop105服务器 | Slave1 | 192.168.0.105 |
| hadoop106服务器 | Slave2 | 192.168.0.106 |
使用的组件版本如下:
| 组件名称 | 版本号 |
|---|---|
| JDK | 1.8 |
| Hadoop | 3.1.3 |
| Spark | 3.1.1 |
| Hive | 3.1.2 |
| MySQL | 5.7 |
| Hudi | 0.12.0 |
创建 Maven 项目
在 IDEA 中创建一个 Maven 项目,这里不再赘述。
项目创建完成后,将 Hadoop 的配置文件 core-site.xml、hdfs-site.xml 文件与 Spark 的日志管理文件放入到项目中的 resources 目录下。
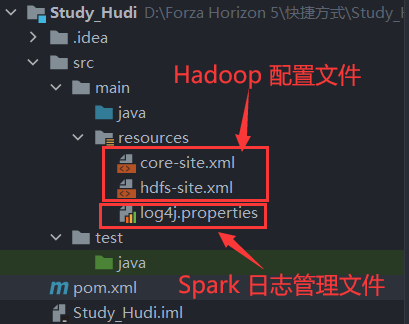
添加依赖,可以根据我的进行修改。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.study</groupId><artifactId>Study_Hudi</artifactId><version>1.0-SNAPSHOT</version><repositories><repository><id>aliyun</id><url>http://maven.aliyun.com/nexus/content/groups/public/</url></repository></repositories><properties><scala.version>2.12.10</scala.version><spark.version>3.1.1</spark.version><hadoop.version>3.1.3</hadoop.version><hudi.version>0.12.0</hudi.version><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target></properties><dependencies><!-- 依赖Scala语言 --><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>${scala.version}</version></dependency><!-- Spark Core 依赖 --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>${spark.version}</version></dependency><!-- Spark SQL 依赖 --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.12</artifactId><version>${spark.version}</version></dependency><!-- Hadoop Client 依赖 --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version></dependency><!-- hudi-spark3 --><dependency><groupId>org.apache.hudi</groupId><artifactId>hudi-spark3.1-bundle_2.12</artifactId><version>${hudi.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-avro_2.12</artifactId><version>${spark.version}</version></dependency><dependency><groupId>joda-time</groupId><artifactId>joda-time</artifactId><version>2.10</version></dependency></dependencies><build><outputDirectory>target/classes</outputDirectory><testOutputDirectory>target/test-classes</testOutputDirectory><resources><resource><directory>${project.basedir}/src/main/resources</directory></resource></resources><!-- Maven 编译的插件 --><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.0</version><configuration><source>1.8</source><target>1.8</target><encoding>UTF-8</encoding></configuration></plugin><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.2.0</version><executions><execution><goals><goal>compile</goal><goal>testCompile</goal></goals></execution></executions></plugin></plugins></build></project>
插入数据
import org.apache.hudi.QuickstartUtils.{DataGenerator, convertToStringList}
import org.apache.spark.sql.{DataFrame, Dataset, SaveMode, SparkSession}import java.utilobject HudiDemo {def insertData(spark: SparkSession, tableName: String, tablePath: String): Unit = {// 导入隐式转换import spark.implicits._// 利用官方提供的模拟数据对象生成 100 条数据(JSON 格式)val generator = new DataGenerator()val list_datas: util.List[String] = convertToStringList(generator.generateInserts(100))// 序列化数据import scala.collection.JavaConverters._val json_datas: Dataset[String] = spark.sparkContext.parallelize(list_datas.asScala).toDS()// 加载数据val dataFrame: DataFrame = spark.read.json(json_datas)// 将数据插入数据到 Hudi 表import org.apache.hudi.DataSourceWriteOptions._import org.apache.hudi.config.HoodieWriteConfig._dataFrame.write.mode(SaveMode.Append).format("hudi").option("hoodie.insert.shuffle.parallelism", "2").option("hoodie.upsert.shuffle.parallelism", "2").option(PRECOMBINE_FIELD.key(), "ts").option(RECORDKEY_FIELD.key(), "uuid").option(PARTITIONPATH_FIELD.key(), "partitionpath").option(TBL_NAME.key(), tableName).save(tablePath)}def main(args: Array[String]): Unit = {// 创建 Spark 对象val spark: SparkSession = SparkSession.builder().appName("hudi_demo").master("local[*]")// 设置 hudi 序列化方式,固定写法.config("spark.serializer","org.apache.spark.serializer.KryoSerializer").getOrCreate()// 定义表名称和 HDFS 存储路径val tableName = "trips"val tablePath = "/hudi_warehouse/demo"insertData(spark,tableName,tablePath)// 释放资源spark.stop()}}
要点解析:
使用 DataGenerator 生成随机数据,并将数据转换为一个字符串列表,这个是官方提供的,生成的是出租车相关数据,因为 Hudi 是由 Uber(美国的打车 APP) 开发的。
将生成的数据使用 spark.sparkContext.parallelize() 方法将数据转换为一个 Spark Dataset,每个元素都是一个字符串,代表一条数据。JavaConverters 提供了将 Java List 转换为 Scala List 的方法。
在写入数据那块,使用 DataFrame 中的 write 方法将数据插入到 Hudi 表中,详细参数解释如下:
-
mode(SaveMode.Append)表示追加模式; -
format("hudi")表示将数据源指定为 Hudi; -
option()方法用于设置 Hudi 表的属性:-
PRECOMBINE_FIELD(预合并字段)
-
RECORDKEY_FIELD(记录键字段)
-
PARTITIONPATH_FIELD(分区路径字段)
-
TBL_NAME(指定表名称)
-
-
save()方法将数据保存到 Hudi 表中。
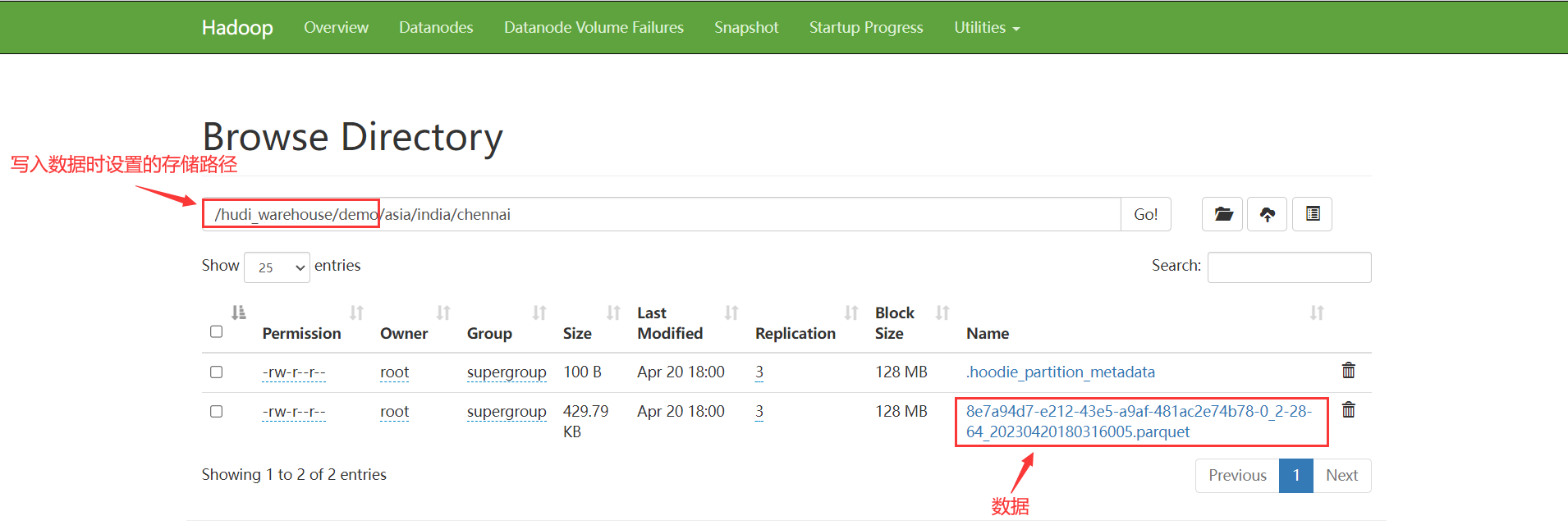
数据表写入后,我们可以在 HDFS 中查看到:
查询数据
import org.apache.hudi.QuickstartUtils.{DataGenerator, convertToStringList}
import org.apache.spark.sql.{DataFrame, Dataset, SaveMode, SparkSession}import java.utilobject HudiDemo {def queryData(spark: SparkSession, path: String): Unit = {import spark.implicits._val dataFrame: DataFrame = spark.read.format("hudi").load(path)// 获取表结构dataFrame.printSchema()// 查询支付费用小于 30 的数据dataFrame.createOrReplaceTempView("uber")spark.sql("""|select| driver,| rider,| fare,| _hoodie_commit_time|from| uber|where| fare < 30|order by| fare|limit 10|""".stripMargin).show(truncate = false)}def main(args: Array[String]): Unit = {// 创建 Spark 对象val spark: SparkSession = SparkSession.builder().appName("hudi_demo").master("local[*]")// 设置序列化方式.config("spark.serializer","org.apache.spark.serializer.KryoSerializer").getOrCreate()// 定义表名称和 HDFS 存储路径val tableName = "trips"val tablePath = "/hudi_warehouse/demo"queryData(spark,tablePath)// 释放资源spark.stop()}}要点解析:
读取 Hudi 表的数据十分简单,直接指定数据存储路径,然后就可以加载为 DataFrame 格式进行操作了。
这里说一下 dataFrame.printSchema() 查询到的 Hudi 表结构:
root|-- _hoodie_commit_time: string (nullable = true)|-- _hoodie_commit_seqno: string (nullable = true)|-- _hoodie_record_key: string (nullable = true)|-- _hoodie_partition_path: string (nullable = true)|-- _hoodie_file_name: string (nullable = true)|-- begin_lat: double (nullable = true)|-- begin_lon: double (nullable = true)|-- driver: string (nullable = true)|-- end_lat: double (nullable = true)|-- end_lon: double (nullable = true)|-- fare: double (nullable = true)|-- rider: string (nullable = true)|-- ts: long (nullable = true)|-- uuid: string (nullable = true)|-- partitionpath: string (nullable = true)
-
_hoodie_commit_time:记录该数据被写入 Hudi 表的提交时间,Hudi 自添加字段。 -
_hoodie_commit_seqno:记录该数据被写入 Hudi 表的提交序号,Hudi 自添加字段。 -
_hoodie_record_key:记录该数据在 Hudi 表中的唯一标识,用于进行数据的查找和更新,Hudi 自添加字段。 -
_hoodie_partition_path:记录该数据在 Hudi 表中所属的分区路径,Hudi 自添加字段。 -
_hoodie_file_name:记录该数据所在的数据文件名,Hudi 自添加字段。 -
begin_lat:表示起点的纬度。 -
begin_lon:表示起点的经度。 -
driver:表示司机的姓名。 -
end_lat:表示终点的纬度。 -
end_lon:表示终点的经度。 -
fare:表示该行程的费用。 -
rider:表示乘客的姓名。 -
ts:表示该行程的时间戳。 -
uuid:表示该行程的唯一标识。 -
partitionpath:表示该数据在 Hudi 表中所属的分区路径。
最终输出结果如下所示:
+----------+---------+------------------+-------------------+
|driver |rider |fare |_hoodie_commit_time|
+----------+---------+------------------+-------------------+
|driver-213|rider-213|2.3197037715185997|20230420180316005 |
|driver-213|rider-213|2.3929870003208786|20230420180316005 |
|driver-213|rider-213|4.477960629065403 |20230420180316005 |
|driver-213|rider-213|4.816835556452426 |20230420180316005 |
|driver-213|rider-213|5.585015784895486 |20230420180316005 |
|driver-213|rider-213|6.105928762642976 |20230420180316005 |
|driver-213|rider-213|6.330332057511468 |20230420180316005 |
|driver-213|rider-213|8.123010514625829 |20230420180316005 |
|driver-213|rider-213|8.61052303992933 |20230420180316005 |
|driver-213|rider-213|9.40943595299718 |20230420180316005 |
+----------+---------+------------------+-------------------+
拓展:
查询 Hudi 表数据时,可以依据时间进行过滤查询,设置属性:"as.of.instant",时间的格式为:"20210728141108" 或 "2021-07-28 14: 11: 08",如下所示:
val dataFrame: DataFrame = spark.read.format("hudi").option("as.of.instant", "20210728141108").load(path)
更新数据
import org.apache.hudi.QuickstartUtils.{DataGenerator, convertToStringList}
import org.apache.spark.sql.{DataFrame, Dataset, SaveMode, SparkSession}import java.utilobject HudiDemo {def insertData(spark: SparkSession, tableName: String, tablePath: String): DataGenerator = {// 导入隐式转换import spark.implicits._// 利用官方提供的模拟数据对象生成 100 条数据(JSON 格式)val generator = new DataGenerator()val list_datas: util.List[String] = convertToStringList(generator.generateInserts(100))// 序列化数据import scala.collection.JavaConverters._val json_datas: Dataset[String] = spark.sparkContext.parallelize(list_datas.asScala).toDS()// 加载 JSON 数据val dataFrame: DataFrame = spark.read.json(json_datas)// 将数据插入数据到 Hudi 表import org.apache.hudi.DataSourceWriteOptions._import org.apache.hudi.config.HoodieWriteConfig._dataFrame.write.mode(SaveMode.Append).format("hudi").option("hoodie.insert.shuffle.parallelism", "2").option("hoodie.upsert.shuffle.parallelism", "2").option(PRECOMBINE_FIELD.key(), "ts").option(RECORDKEY_FIELD.key(), "uuid").option(PARTITIONPATH_FIELD.key(), "partitionpath").option(TBL_NAME.key(), tableName).save(tablePath)return generator}def updateData(spark: SparkSession, table: String, path: String, dataGen: DataGenerator): Unit = {import spark.implicits._// 模拟产生更新数据import org.apache.hudi.QuickstartUtils._import scala.collection.JavaConverters._val updates: util.List[String] = convertToStringList(dataGen.generateUpdates(100))val updateDF: DataFrame = spark.read.json(spark.sparkContext.parallelize(updates.asScala, 2).toDS())// 更新数据至 Hudi 表import org.apache.hudi.DataSourceWriteOptions._import org.apache.hudi.config.HoodieWriteConfig._updateDF.write.mode(SaveMode.Append).format("hudi").option("hoodie.insert.shuffle.parallelism", "2").option("hoodie.upsert.shuffle.parallelism", "2").option(PRECOMBINE_FIELD.key(), "ts").option(RECORDKEY_FIELD.key(), "uuid").option(PARTITIONPATH_FIELD.key(), "partitionpath").option(TBL_NAME.key(), table).save(path)}def main(args: Array[String]): Unit = {// 创建 Spark 对象val spark: SparkSession = SparkSession.builder().appName("hudi_demo").master("local[*]")// 设置序列化方式.config("spark.serializer","org.apache.spark.serializer.KryoSerializer").getOrCreate()// 定义表名称和 HDFS 存储路径val tableName = "trips"val tablePath = "/hudi_warehouse/demo"val generator: DataGenerator = insertData(spark, tableName, tablePath)updateData(spark,tableName,tablePath,generator)// 释放资源spark.stop()}}
由于官方提供的工具类 DataGenerator 模拟生成更新 update 数据时,必须要与插入 insert 数据使用同一个 DataGenerator 对象,所以在插入数据完成后,返回 DataGenerator 对象,然后再次生成模拟数据,最后更新写入 Hudi 中。
增量查询
当 Hudi 中表的类型为:COW 时,支持两种方式查询:快照查询和增量查询,默认为快照查询。
如果是增量查询,需要指定时间戳,当 Hudi 表中数据满足:instant_time > beginTime 时,数据将会被加载读取。
此外,也可以设置某个时间范围:endTime > instant_time > begionTime,获取相应的数据。
import org.apache.hudi.QuickstartUtils.{DataGenerator, convertToStringList}
import org.apache.spark.sql.{DataFrame, Dataset, SaveMode, SparkSession}import java.utilobject HudiDemo {def incrementalQueryData(spark: SparkSession, path: String): Unit = {import spark.implicits._// 加载 Hudi 表数据,获取 commitTime 时间,作为增量查询时间阈值import org.apache.hudi.DataSourceReadOptions._spark.read.format("hudi").load(path).createOrReplaceTempView("uber")val commits: Array[String] = spark.sql("""|select| distinct(_hoodie_commit_time) as commitTime|from| uber|order by| commitTime desc|""".stripMargin).map(row => row.getString(0)).take(100)val beginTime: String = commits(commits.length - 1)println(s"beginTime = ${beginTime}")// 设置 Hudi 数据 CommitTime 时间阈值,进行增量查询数据val tripsIncrementalDF: DataFrame = spark.read.format("hudi")// 设置查询数据模式为:incremental,增量读取.option(QUERY_TYPE.key(), QUERY_TYPE_INCREMENTAL_OPT_VAL)// 设置增量读取数据时开始时间.option(BEGIN_INSTANTTIME.key(), beginTime).load(path)// 将增量查询数据注册为临时视图,查询费用 fare 大于 20 的数据tripsIncrementalDF.createOrReplaceTempView("result")spark.sql("""|select| `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts|from| result|where| fare > 20.0|""".stripMargin).show(10, truncate = false)}def main(args: Array[String]): Unit = {// 创建 Spark 对象val spark: SparkSession = SparkSession.builder().appName("hudi_demo").master("local[*]")// 设置序列化方式.config("spark.serializer","org.apache.spark.serializer.KryoSerializer").getOrCreate()// 定义表名称和 HDFS 存储路径val tableName = "trips"val tablePath = "/hudi_warehouse/demo"incrementalQueryData(spark,tablePath)// 释放资源spark.stop()}}
最终输出结果如下:
beginTime = 20230420180316005
+-------------------+------------------+-------------------+-------------------+-------------+
|_hoodie_commit_time|fare |begin_lon |begin_lat |ts |
+-------------------+------------------+-------------------+-------------------+-------------+
|20230420191528978 |38.66148557641057 |0.1688421548397122 |0.7327922821557408 |1681766807190|
|20230420191522934 |66.64889106258252 |0.09632451474505643|0.47805950282725407|1681403127621|
|20230420191528978 |68.55454228464582 |0.23574926083757652|0.9978872086544781 |1681824914068|
|20230420191528978 |63.727536726737064|0.9162255698100301 |0.13790358857355933|1681614366597|
|20230420191528978 |87.67786901640419 |0.5117763107378623 |0.5256297280989708 |1681932619296|
|20230420191522934 |52.69712318306616 |0.37272120488128546|0.3748535764638379 |1681447723048|
|20230420191528978 |95.62675391327986 |0.723282980554737 |0.5241875096707868 |1681923702941|
|20230420191528978 |87.29826695295154 |0.4020819430848185 |0.6616708725249253 |1681484734371|
|20230420191528978 |66.76801186951676 |0.17564160456980282|0.876587418131608 |1681770062715|
|20230420191528978 |39.9997692098926 |0.30356883150425995|0.08732209622598563|1681852678149|
+-------------------+------------------+-------------------+-------------------+-------------+
删除数据
使用官方的数据生成类 DataGenerator,基于已有数据构建要删除的数据,最终保存到 Hudi 表中。
import org.apache.hudi.QuickstartUtils.{DataGenerator, convertToStringList}
import org.apache.spark.sql.{DataFrame, Dataset, SaveMode, SparkSession}import java.utilobject HudiDemo {def deleteData(spark: SparkSession, table: String, path: String): Unit = {import spark.implicits._// 加载 Hudi 表数据,获取条目数val tripsDF: DataFrame = spark.read.format("hudi").load(path)println(s"Count = ${tripsDF.count()}")// 模拟要删除的数据val dataframe: DataFrame = tripsDF.select($"uuid", $"partitionpath").limit(2)import org.apache.hudi.QuickstartUtils._val dataGen: DataGenerator = new DataGenerator()val deletes: util.List[String] = dataGen.generateDeletes(dataframe.collectAsList())import scala.collection.JavaConverters._val deleteDF: DataFrame = spark.read.json(spark.sparkContext.parallelize(deletes.asScala, 2))// 保存数据至 Hudi 表,设置操作类型为:DELETEimport org.apache.hudi.DataSourceWriteOptions._import org.apache.hudi.config.HoodieWriteConfig._deleteDF.write.mode(SaveMode.Append).format("hudi").option("hoodie.insert.shuffle.parallelism", "2").option("hoodie.upsert.shuffle.parallelism", "2")// 设置数据操作类型为delete,默认值为upsert.option(OPERATION.key(), "delete").option(PRECOMBINE_FIELD.key(), "ts").option(RECORDKEY_FIELD.key(), "uuid").option(PARTITIONPATH_FIELD.key(), "partitionpath").option(TBL_NAME.key(), table).save(path)// 再次加载 Hudi 表数据,统计条目数,查看是否减少 2 条val hudiDF: DataFrame = spark.read.format("hudi").load(path)println(s"Delete After Count = ${hudiDF.count()}")}def main(args: Array[String]): Unit = {// 创建 Spark 对象val spark: SparkSession = SparkSession.builder().appName("hudi_demo").master("local[*]")// 设置序列化方式.config("spark.serializer","org.apache.spark.serializer.KryoSerializer").getOrCreate()// 定义表名称和 HDFS 存储路径val tableName = "trips"val tablePath = "/hudi_warehouse/demo"deleteData(spark,tableName,tablePath)// 释放资源spark.stop()}}
最终输出结果如下:
Count = 200
Delete After Count = 198