SLAM面试笔记(2) - ORB-SLAM2
.jpg)
目录
1 四叉树实现特征点均匀化分布
2 Bow词袋模型
2.1 什么是词袋?
2.2 词袋在ORB-SLAM2中的作用
2.3 离线训练字典树流程
3 ORB-SLAM的跟踪方法
3.1 恒速模型跟踪
3.2 重定位跟踪
3.3 参考关键帧跟踪
持续更新中...
1 四叉树实现特征点均匀化分布
参考文章:VSLAM系列原创04讲 | 四叉树实现ORB特征点均匀化分布:原理+代码_节点
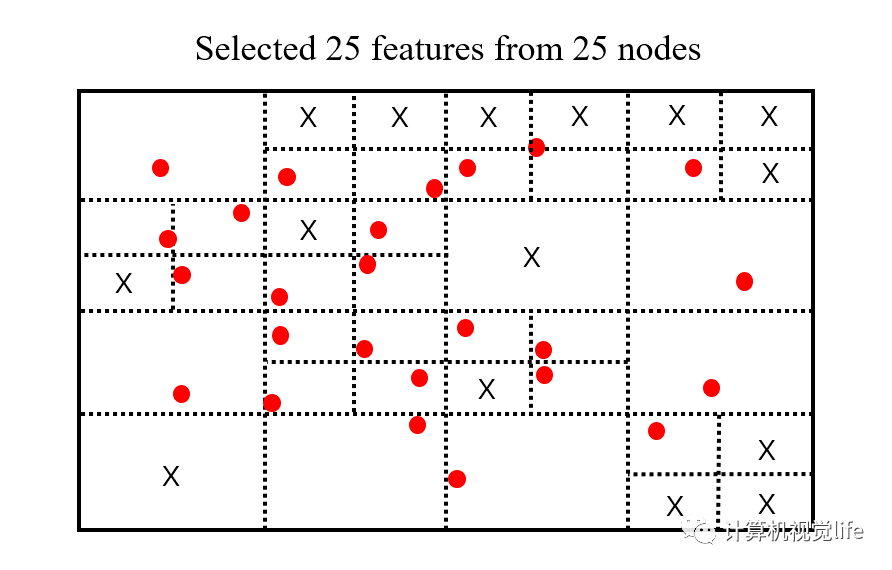
第1步:首先确定初始的节点(node)数目,一般刚开始的时候只有一个节点,也是四叉树的根节点。假如我们目标是均匀的选取 25 个特征点,那么后面我们就需要分裂出25个节点,然后从每个节点中选取一个代表性的特征点。
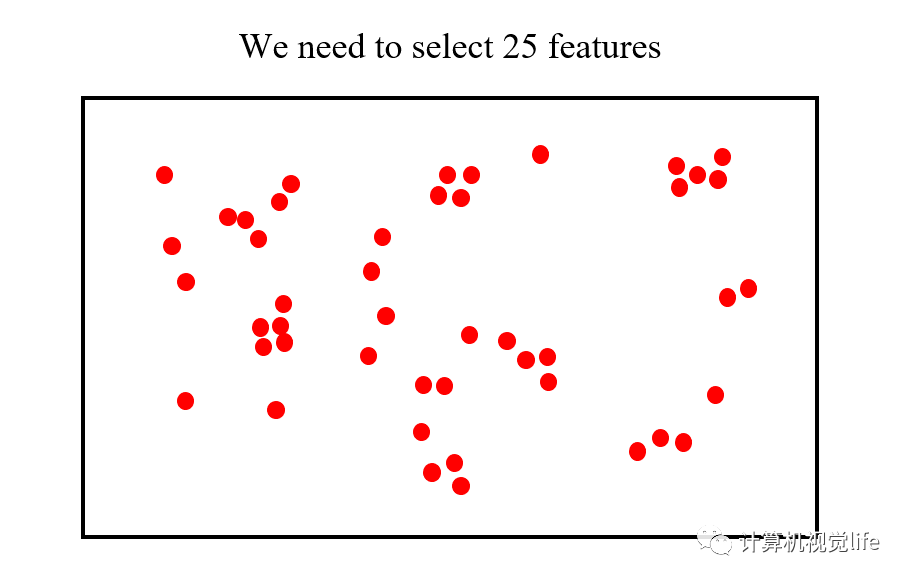
第2步:节点第1次分裂,1个根节点分裂为4个节点。落在多个节点区域范围内的特征点被多个节点共享。然后统计每个节点里包含特征点的数目,如果某个节点里特征点数目为 0,则删掉该节点,如果某个节点里特征点数目为 1,则该节点不再进行分裂。判断此时的节点总数是否超过设定值 25,如果没有超过则继续对每个节点分裂。
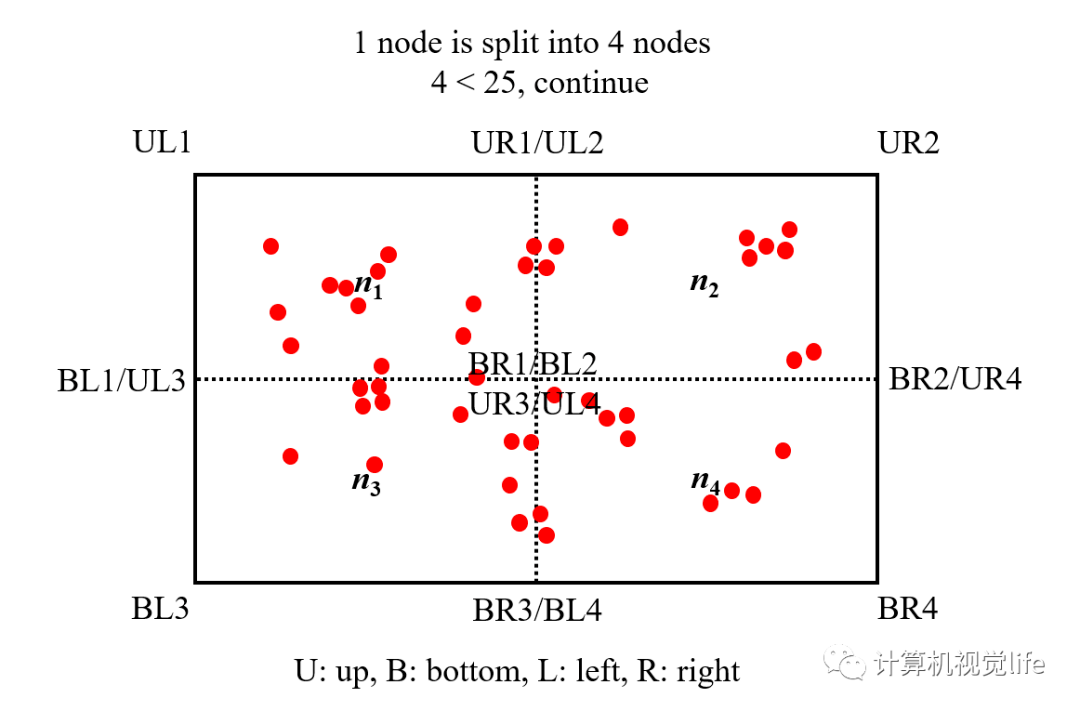
第3步:对上一步得到的 4 个节点分别进行一分为四的操作。
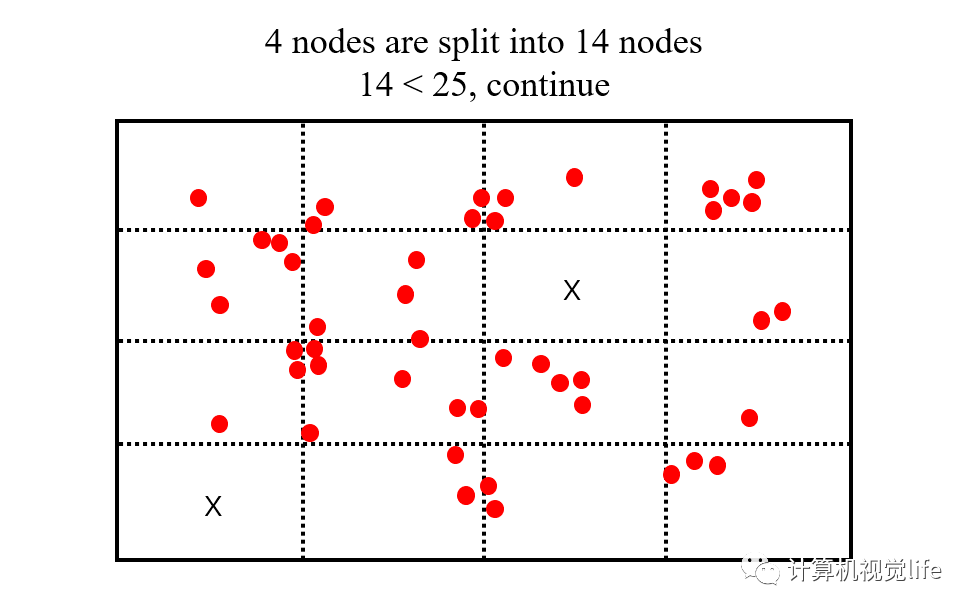
第4步:超过需要提取 25 个特征点数目的需求时停止分裂。对所有节点按照内部包含的特征点数目进行排列,优先分裂特征点数目多的节点,这样做的目的是使得特征密集的区域能够更加细分。对于包含特征点较少的节点,有可能因为提前达到要求而不再分裂。
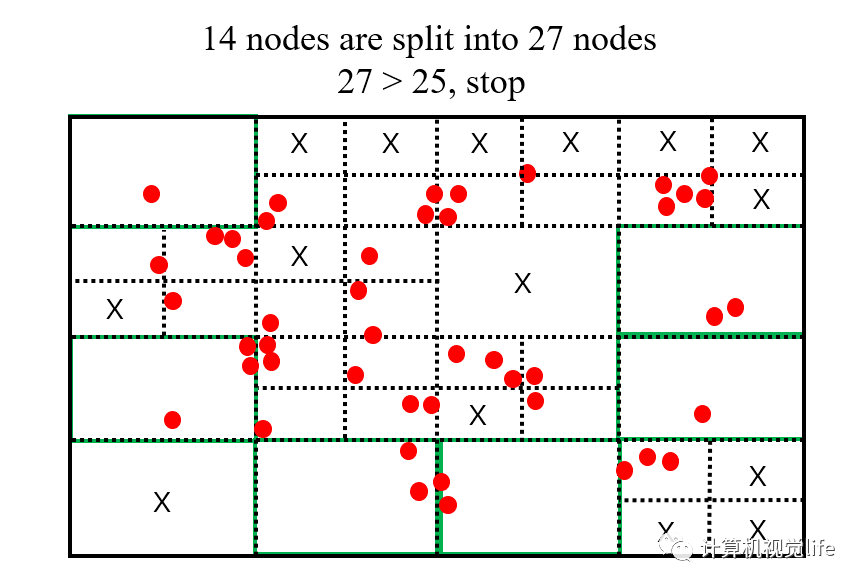
第5步:上一步中我们已经得到了所需要的 25 个节点,只需要从每个节点中选出角点响应值最高的特征点,作为该节点的唯一特征点,该节点内其他低响应值的特征点全部删掉。这样我们就得到了均匀化后的、需要数目的特征点。
2 Bow词袋模型
2.1 什么是词袋?
词袋(Bag-of-Words,BoW),目的是用“图像上有哪几种特征”来描述一幅图像。例
如,我们说某张照片中有一个人、一辆车;而另一张中有两个人、一只狗。根据这样的描述,就
可以度量这两幅图像的相似性。再具体一些,我们要做以下三步:
- 确定“人”“车”“狗”等概念一对应于BoW中的“单词”(Wod),许多单词放在一起,组成了“字典”(Dictionary)。
- 确定一幅图像中出现了哪些在字典中定义的概念一我们用单词出现的情况(或直方图)描述整幅图像。这就把一幅图像转换成了一个向量的描述。
- 设计一定的计算方式,就能确定图像间的相似性。例如可以通过下式计算α,b的相似性:
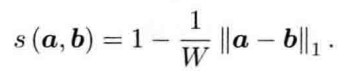
其中:范数取L1范数,即各元素绝对值之和。请注意在两个向量完全一样时,我们将得到1;完全相反时(a为0的地方b为1)得到0。这样就定义了两个描述向量的相似性,也就定义了图像之间的相似程度。
2.2 词袋在ORB-SLAM2中的作用
- 用于加速特征匹配。用暴力匹配对两张图像中提取的特征点进行匹配的方法,不仅非常慢,而且容易出现错误匹配。通过词袋搜索匹配,只需要比较同一个节点下的特征点,因相当于提前对相似的特征点进行了区域划分,缩小了搜索范围,提高了搜索效率也减少很多错误匹配。
- 用于闭环检测。闭环检测的核心就是判断两张图像是不是同一个场景,也就是判断图像的相似性。
2.3 离线训练字典树流程
使用词袋模型的前提的需要离线训练字典树(Vocabulary Tree),我们也可以用别人训练好的字典,离线训练字典的流程如下:
- 准备好足够数量的图像数据集。数据集最好涵盖不同光照、不同场景、不同天气和不同季节等条件下拍摄的图像集合,种类尽量多而不重复
- 遍历以上所有的训练图像,对每张图像提取 ORB 特征点。
- 建立字典树。
- 根据每个单词在训练集中出现的频率给其赋予一定的权重,其在训练集中出现的次数越多,说明辨别力越差,赋予的权重就越低
3 ORB-SLAM的跟踪方法
3.1 恒速模型跟踪
场景:正常情况下,系统使用恒速模型跟踪方法,该函数是用上一帧来跟踪当前帧。
流程:
- 首先,更新上一帧的位姿。对于双目或者RGB-D相机,还会生成新的临时地图点(但是这些地图点只是用来跟踪的,不加入地图中,跟踪完成后会进行删除)。
- 通过上一帧的位姿以及之前估计的速度估计当前帧的位姿的初始值(十分粗糙,不准确,后面会使用优化)。
- 根据相机的模型单目还是双目,设置特征匹配过程中的搜索半径,单目的搜索半径小。
- 投影匹配,上一帧3d点投影到当前坐标系下,在该2d点半径th范围内搜索可以匹配的匹配点遍历可以匹配的点,计算描述子距离,记录最小的匹配距离,小于阈值的,再记录匹配点特征方向差值进行方向验证,剔除方向差直方图统计中,方向差值数量少的点对,保留前三个数量多的点对。
- 如果找到的匹配点对如果少于20,则扩大搜索半径th=2*th再计算一遍,如果匹配点的数量还是太少,则使用恒速模型跟踪当前帧失败。
- 否则,使用PnP进行BA优化,获得较为准确的位姿,统计内点的数量,将外点所对应的地图点进行删除。若内点的数量小于阈值10个匹配点,则跟踪失败,否则,跟踪成功。
3.2 重定位跟踪
场景:如果使用恒速模型跟踪和参考关键帧跟踪也失败了,系统只能进行重定位跟踪。系统为了保证不会跟踪失败,会进行一系列的谨慎的判断操作,实在拯救不了了,才会判定系统重定位失败。使用该函数时,系统已经经历了恒速模型和参考关键帧模型,且已经跳过了上一帧,时间已经花费挺久了,所以这里要加速处理,否则实时性就难以保证。因此系统中主要使用了词袋进行加速处理。
流程:
- 首先,通过词袋查找关键帧数据库中与当前帧相似的候选关键帧。
- 然后遍历每一个候选关键帧与当前帧通过词袋进行特征点跟踪并通过直方图检查选址一致性,剔除掉不一致的匹配点,获得每一个候选关键帧和当前帧的匹配点个数。若匹配的特征点个数少于15个,则放弃该候选关键帧,否则,通过当前帧与匹配的特征点建立EPnP算法。
- 遍历每一个满足阈值要求的EPnP算法,迭代求取当前帧的位姿。
- 如果内点的数量少于10个,则跳过当前的候选关键帧。若内点的数量nGood大于10但是小于50个,说明系统还是有可能重定位成功的,那么就用投影的方式将候选关键帧中未匹配的地图点投影到当前帧中,进行匹配,并通过旋转直方图进行筛选,再增加一些匹配关系nadditional。
- 如果nGood + nadditional 大于50了,那么就再次进行优化,若内点的数量good 大于30 小于 50, 那么就再次重投影,直到成功为止。经过一些列的操作的目的就是为了拯救系统,让系统跟踪成功。
3.3 参考关键帧跟踪
场景:没有速度信息的时候、刚完成重定位、或者恒速模型跟踪失败后使用,大部分时间不用。只利用到了参考帧的信息。
流程:
- 计算当前帧的BoW,通过词袋BoW加速当前帧与参考帧之间的特征点匹配。
- 对属于同一node(同一node才可能是匹配点)的特征点通过描述子距离进行匹配,遍历该node中特征点,特征点最小距离明显小于次小距离才作为成功匹配点,记录特征点对方向差统计到直方图
- 记录特征匹配成功后每个特征点对应的MapPoint(来自参考帧),用于后续3D-2D位姿优化,通过角度投票进行剔除误匹配。
- 将上一帧的位姿作为当前帧位姿的初始值(加速收敛),通过优化3D-2D的重投影误差来获得准确位姿。3D-2D来自第2步匹配成功的参考帧和当前帧,重投影误差 e = (u,v) - project(Tcw*Pw),只优化位姿Tcw,不优化MapPoints的坐标。
- 剔除优化后的outlier地图点。
