一文速学数模-季节性时序预测SARIMA模型详解+Python实现

目录
前言
二、SARIMA模型定义
三.SARIMA模型算法原理
1.季节差分:消除季节单位根
2.ARIMA模型
1.自回归(AR)
2.差分(I)
3.移动平均(MA)
4.ARIMA
四.SARIMA模型Python实现
1.数据预处理
季节性分析
ADF检验
序列平稳化
2.模型检验
白噪声检验
3.模型拟合
时间序列定阶
4.模型预测
1、构建模型
2.模型识别
编辑
3.需求预测
4.结果评估
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
参考:
[Python][pmdarima] 季节性ARIMA模型学习
前言
时序预测模型已经写了有八篇了,传统的时序预测模型基本差不多快讲完了。对于每个时序预测模型都有各自特点最优的使用场景,但是一般来说大部分时间序列数据都呈现出季节变化(Season)和循环波动(Cyclic)。对于在这些数据基础之上进行的建模一般最优是采用季节性时序预测SARIMA模型。当然此篇文章我将尽力让大家了解并熟悉SARIMA模型算法框架,保证能够理解通畅以及推演顺利的条件之下,尽量不使用过多的数学公式和专业理论知识。以一篇文章快速了解并实现该算法,以效率最高的方式熟练使用此方法。
博主专注建模四年,参与过大大小小数十来次数学建模,理解各类模型原理以及每种模型的建模流程和各类题目分析方法。此专栏的目的就是为了让零基础快速使用各类数学模型、机器学习和深度学习以及代码,每一篇文章都包含实战项目以及可运行代码。博主紧跟各类数模比赛,每场数模竞赛博主都会将最新的思路和代码写进此专栏以及详细思路和完全代码。希望有需求的小伙伴不要错过笔者精心打造的专栏。
一、季节时间序列模型概述
季节时间序列模型是一种用于建模具有季节性变化的时间序列数据的方法。它考虑到时间序列数据在一年中的不同季节可能会呈现出不同的趋势和周期性变化,这类序列称为季节性序列。因此需要一种方法来建模并捕捉这种季节性变化。
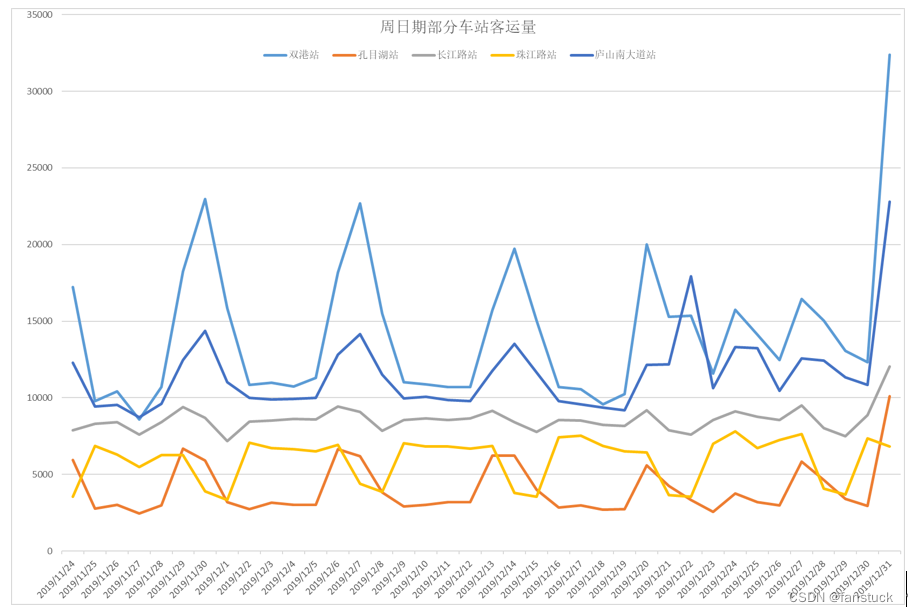
我们见图:周日期部分车站客运量数据,很明显该数据呈现一定的周期性波动,且在年终的时候客流量要比其他时间段多很多。描述这类序列的模型称作季节时间序列模型(seasonal ARIMA model),用SARIMA表示。季节时间序列模型也称作乘积季节模型(Multiplicative seasonal model)。因为模型的最终形式是用因子相乘的形式表示。
二、SARIMA模型定义
SARIMA(Seasonal Autoregressive Integrated Moving Average)是一种基于 ARIMA 模型的季节时间序列预测模型。ARIMA 模型是一种广泛应用于时间序列预测的经典模型,它考虑了时间序列的趋势性和周期性。SARIMA 模型在 ARIMA 模型的基础上增加了季节性,因此可以更好地应对具有季节性变化的时间序列数据。
SARIMA 模型通常包含以下几个参数:
- 季节周期 (Seasonal period):时间序列数据呈现季节性变化的周期,例如一年、一周、一天等。
- 差分次数 (Order of differencing):对时间序列数据进行差分的次数,以消除数据的非平稳性。
- 自回归项 (Autoregressive terms):用于建立时间序列与其过去值的关系,表示时间序列数据的趋势性。
- 移动平均项 (Moving average terms):用于建立时间序列的随机波动性与过去的误差的关系,表示时间序列数据的随机性。
SARIMA 模型可以用来预测具有季节性变化的时间序列数据,例如销售额、气温、股票价格等。它需要基于历史数据来拟合模型,然后使用模型来预测未来一段时间内的数据。在使用 SARIMA 模型时,需要选择合适的参数和模型结构,并进行模型诊断和调优,以获得更准确的预测结果。
三.SARIMA模型算法原理
1.季节差分:消除季节单位根
季节差分是一种常见的消除季节性的方法,其思想是在时间序列数据中进行差分,使得数据变为平稳时间序列,从而便于进行建模和预测。
季节差分的核心是消除季节单位根,即将时间序列中的季节性成分去除。在进行季节差分时,我们需要首先确定季节的周期性,例如如果数据以月为单位,那么季节周期为12,如果数据以周为单位,那么季节周期为52或者53。
然后,我们可以对季节性周期数据进行差分,通常称为季节性差分。季节性差分是指将时间序列数据按照季节性周期进行滞后操作,然后将原始数据减去滞后后的数据。例如,对于季节周期为12的数据,可以进行12阶差分。具体地,将第t个时间点的数据减去第t-12个时间点的数据,即
这样可以得到一个新的时间序列,其中季节性成分被消除,从而得到平稳时间序列。如果还存在趋势和周期性等成分,可以继续对该时间序列进行差分,直到得到平稳时间序列。
季节差分的目的是消除季节性,使得时间序列数据变为平稳时间序列,从而便于进行建模和预测。在建立季节时间序列模型时,通常需要对原始数据进行季节差分,以消除季节性影响。
2.ARIMA模型
ARIMA模型是一个复杂的统计模型,它由自回归模型(AR)和移动平均模型(MA)以及差分(I)组成。ARIMA模型的公式包括三个部分:自回归(AR)、差分(I)和移动平均(MA)。
关于自回归AR算法和移动平均MA的算法大家若是还有疑问的话可以去看我的前几篇文章:
一文速学数模-时序预测模型(二)平稳时间序列预测算法和自回归模型(AR)详解+Python代码实现
一文速学数模-时序预测模型(三)移动平均模型(MA)详解+Python实例代码
1.自回归(AR)
自回归是ARIMA模型的一个重要组成部分,它表示一个时间序列在过去p个时刻的值与当前值之间的关系。其中,p表示自回归阶数,AR(p)模型的数学公式为:
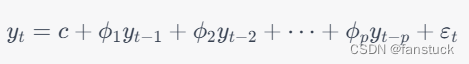
其中,表示时间序列在时间点t的值,
为自回归系数,
为常数项,
为误差项。
2.差分(I)
差分是ARIMA模型的另一个重要组成部分,它可以消除时间序列中的非平稳性。一阶差分时间序列可以表示为:
![]()
3.移动平均(MA)
移动平均是ARIMA模型的第三个组成部分,它表示时间序列中误差项在过去q个时刻的加权平均值与当前值之间的关系。其中,q表示移动平均阶数,MA(q)模型的数学公式为:
![]()
其中,为移动平均系数,
为常数项,
为误差项。
4.ARIMA
综合上述三个部分,ARIMA模型的数学公式为:
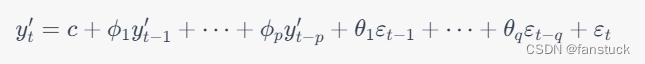
其中,为经过差分后的时间序列,
为自回归系数,
为移动平均系数,
为常数项,
为误差项。
描述当前值
与历史值之间的关系。
关注的是自回归模型的误差项的累加,有效地消除预测中的随机波动。
四.SARIMA模型Python实现
1.数据预处理
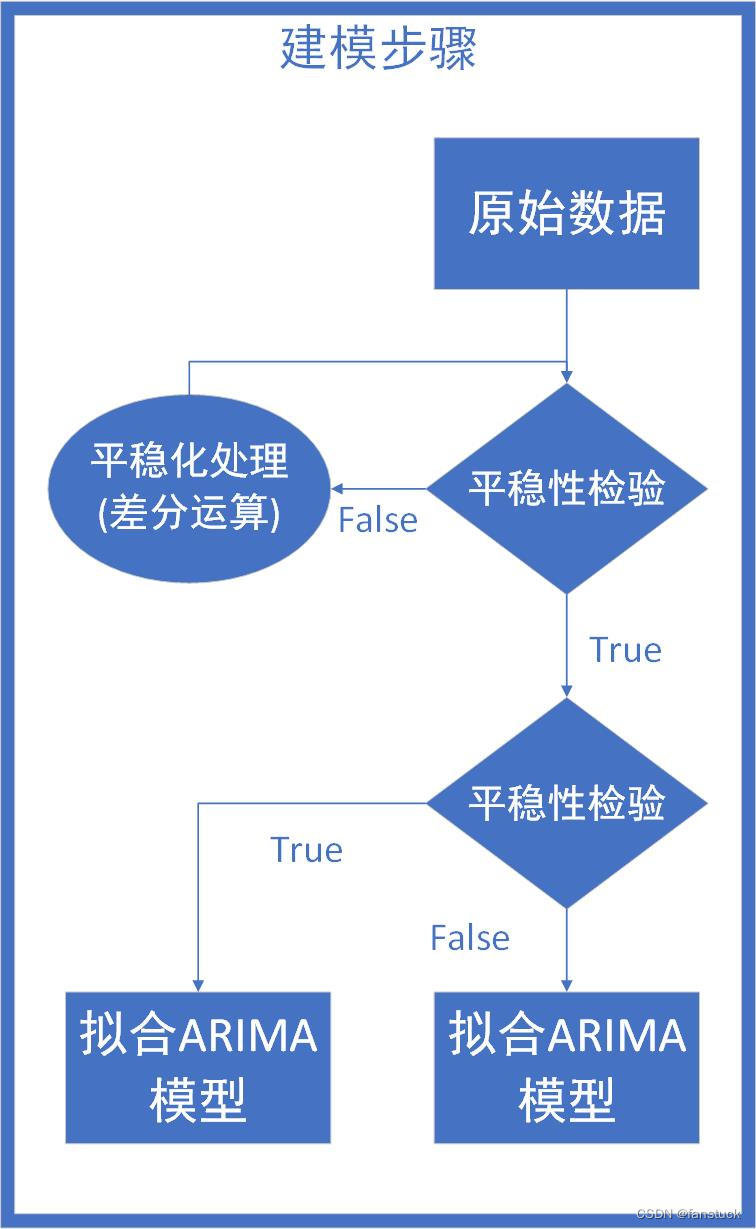
根据建模步骤我们首先对时间序列数据进行平稳性校验和季节性差分等操作。如果数据不平稳,需要进行差分操作使其变为平稳时间序列。同时,如果数据具有季节性,需要对其进行季节性差分,消除季节性影响。
我们先导入相应模块:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
from matplotlib.pylab import rcParams
import pmdarima as pm
import statsmodels.api as sm
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf # 画图定阶
from statsmodels.tsa.stattools import adfuller # ADF检验
from statsmodels.stats.diagnostic import acorr_ljungbox # 白噪声检验
import warnings
import itertools
warnings.filterwarnings("ignore") # 选择过滤警告
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签预测样本为:
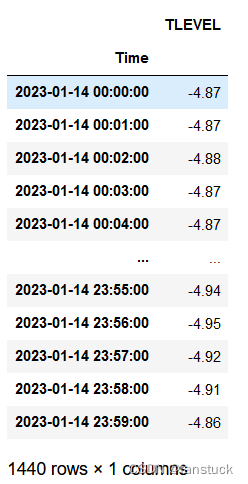
一天的水位数据,时间颗粒度为每分钟。为了更好去展示季节性ARIMA模型我们这里采用15点到24点的数据,更直观的可以看到季节性。
季节性分析
# 时间序列图生成函数
def sequencePlot(data, sequencePlot_name):data.plot(marker='o')# 设置坐标轴标签plt.xlabel("时间", fontsize=15)plt.ylabel("水位", fontsize=15)# 设置图表标题plt.title("{}时间序列图".format(sequencePlot_name), fontsize=15)# 图例位置plt.legend(loc='best')# 生成网格plt.grid(linestyle='--')plt.show()
orign_seqname = "原始"
sequencePlot(df_evel_timese, orign_seqname)
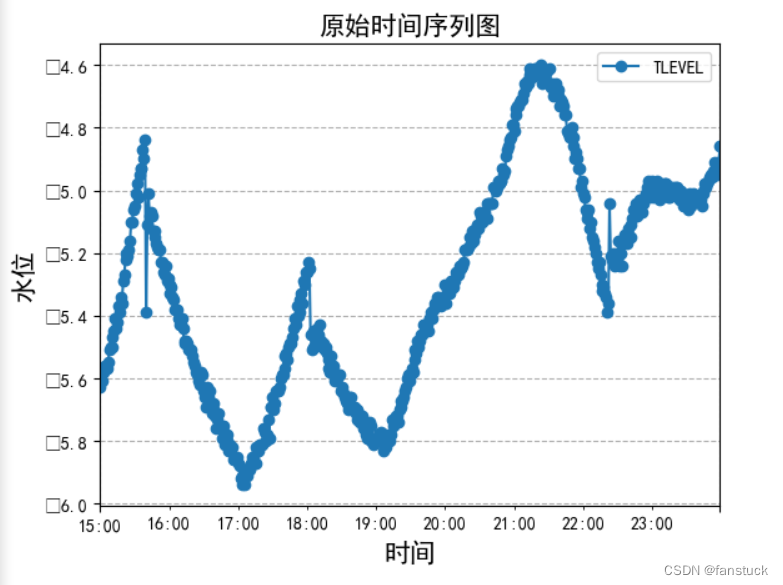
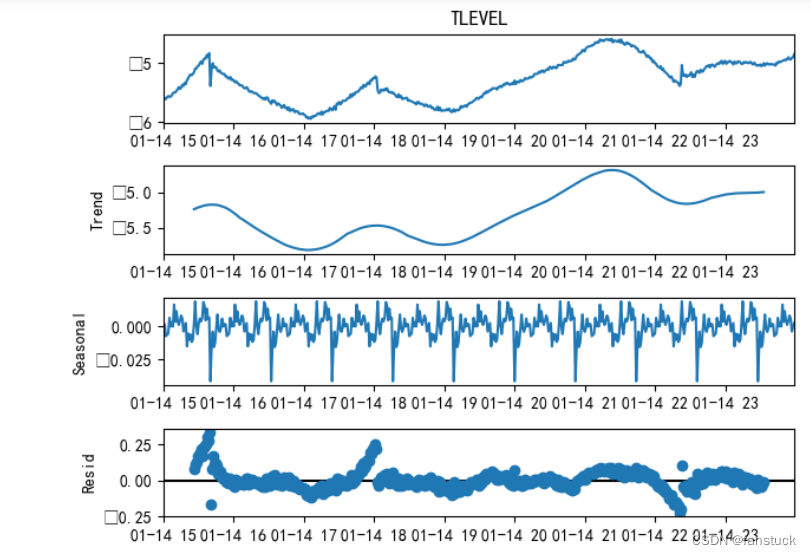
我们可以看到数据有上升的趋势,可以定性地判断该序列非平稳。但是前15个小时都是平稳序列,还需要再检验。同时,可以使用seasonal_decompose()进行分析,将时间序列分解成长期趋势项(Trend)、季节性周期项(Seansonal)和残差项(Resid)这三部分。
from statsmodels.tsa.seasonal import seasonal_decompose
# 分解数据查看季节性 freq为周期
# 推断频率参数
ts_decomposition = seasonal_decompose(df_evel_timese['TLEVEL'], period=52)
ts_decomposition.plot()
plt.show()
ADF检验
ARIMA模型要求时间序列是平稳的。所谓平稳性,其基本思想是:决定过程特性的统计规律不随着时间的变化而变化。由平稳性的定义:对于一切t,s,和
的协方差对于时间的依赖之和时间间隔
有关,而与实际的时刻t和s无关。因此,平稳过程可以简化符号,其中
为自协方差函数,
为自相关函数,记为:
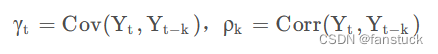
关于严宽平稳我之前写自回归模型(AR)已经写的很清楚了。如果通过时间序列图来用肉眼观看的话可能会存在一些主观性。ADF检验(又称单位根检验)是一种比较常用的严格的统计检验方法。
ADF检验主要是通过判断时间序列中是否含有单位根:如果序列平稳,就不存在单位根;否则,就会存在单位根。
from statsmodels.tsa.stattools import adfuller # ADF检验def stableCheck(timeseries):# 移动60期的均值和方差rol_mean = timeseries.rolling(window=60).mean()rol_std = timeseries.rolling(window=60).std()# 绘图fig = plt.figure(figsize=(12, 8))orig = plt.plot(timeseries, color='blue', label='Original')mean = plt.plot(rol_mean, color='red', label='Rolling Mean')std = plt.plot(rol_std, color='black', label='Rolling Std')plt.legend(loc='best')plt.title('Rolling Mean & Standard Deviation')plt.show()# 进行ADF检验print('Results of Dickey-Fuller Test:')dftest = adfuller(timeseries, autolag='AIC')# 对检验结果进行语义描述dfoutput = pd.Series(dftest[0:4], index=['Test Statistic', 'p-value', '#Lags Used', 'Number of Observations Used'])for key, value in dftest[4].items():dfoutput['Critical Value (%s)' % key] = valueprint('ADF检验结果:')print(dfoutput)
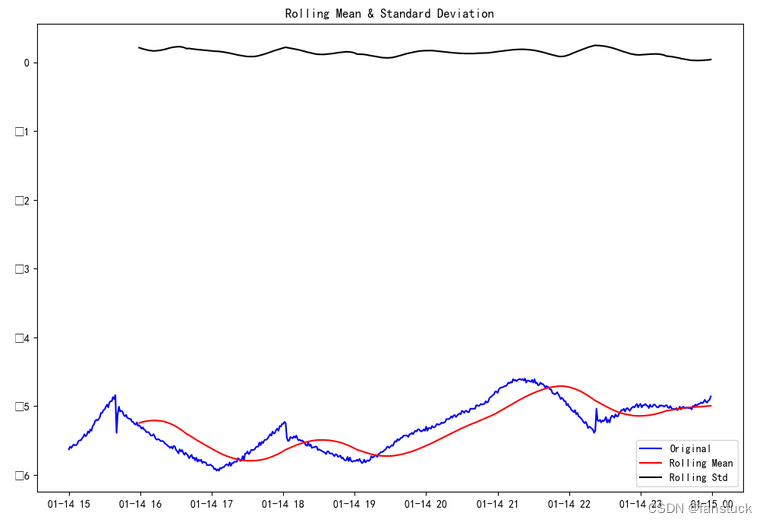
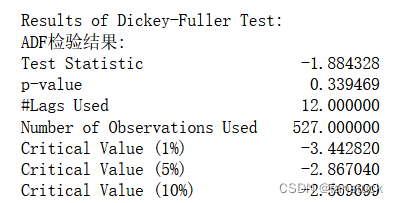
根据给出的ADF检验结果,可以得出以下结论:
- ADF检验的统计量为-1.884328,其对应的p-value为0.339469,p-value大于通常选择的显著性水平(如0.05或0.01),因此我们不能拒绝原假设(即该序列具有单位根,不稳定)。
- 检验中使用了12个滞后项,且观测值数量为527。
- 临界值为-3.442820(1%的显著性水平),-2.867040(5%的显著性水平),-2.569699(10%的显著性水平)。
综上所述,该时间序列不稳定,需要进行差分或其他方法进行处理。
序列平稳化
对于非平稳时间序列,可以通过d阶差分运算使变成平稳序列。从统计学角度来讲,只有平稳性的时间序列才能避免“伪回归”的存在。
先进行了一阶差分,再进行了一次季节性差分:
# 差分处理非平稳序列,先进行一阶差分
df_evel_timese_diff1 = df_evel_timese.diff(1).dropna()
# 在一阶差分基础上进行季节性差分差分
df_evel_timese_diff2 = df_evel_timese_diff1.diff(12).dropna()
stableCheck_result2 = stableCheck(df_evel_timese_diff2)
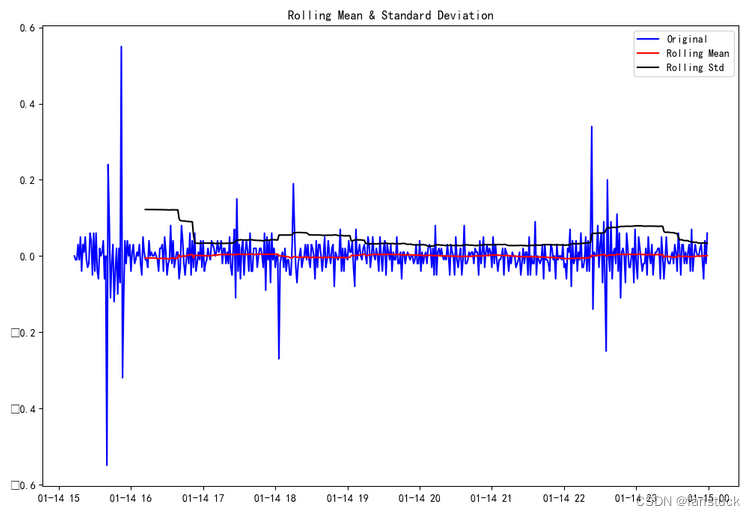
再进行ADF检验:
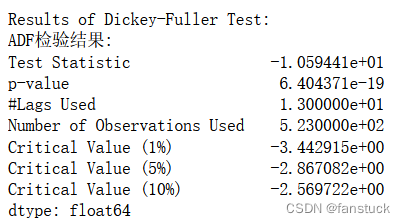
ADF检验的结果显示,检验统计量的值为-5.810709e+00,p值为4.408270e-07,这表明在显著性水平为0.05的情况下,可以拒绝零假设,即该时间序列是平稳的,不存在单位根。同时,可以看到临界值的值为-3.443212(1%水平)、-2.867213(5%水平)和-2.569791(10%水平),检验统计量的值远小于这三个临界值,也说明了序列的平稳性。因此,我们可以认为该时间序列是平稳的。
2.模型检验
在确定SARIMA模型的参数后,需要进行模型检验,以检查模型是否符合预期。检验方法包括残差序列的自相关函数和偏自相关函数的图形分析,Ljung-Box检验、Shapiro-Wilk检验等方法。如果模型不符合预期,则需要调整模型参数,重新拟合模型,直到得到满意的结果。
白噪声检验
接下来,对d阶差分后的的平稳序列进行白噪声检验,如果平稳序列是非白噪声序列,那么说明它不是由随机噪声组成的。这意味着序列中存在一些内在的结构或模式,这些结构或模式可以被进一步分析和建模,以便进行预测或其他目的。白噪音在我写AR模型的时候同样也写了这也不再补充。
我们可以通过Ljung-Box检验,是时间序列分析中检验序列自相关性的方法。LB检验的Q统计量为:
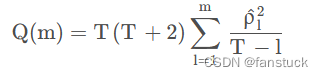
def whiteNoiseCheck(data):result = acorr_ljungbox(data, lags=1)temp = result.iloc[:,1].values[0]#print(result.iloc[:,1].values[0])print('白噪声检验结果:', result)# 如果temp小于0.05,则可以以95%的概率拒绝原假设,认为该序列为非白噪声序列;否则,为白噪声序列,认为没有分析意义print(temp)return result
ifwhiteNoise = whiteNoiseCheck(df_evel_timese_diff2)
![]()
LB统计量用于评估序列中是否存在自相关性,p-value则用于判断序列是否为白噪声。一般来说,如果序列是白噪声,那么LB统计量的值会接近0,p-value会很大,说明序列中不存在自相关性。但是如果p-value小于显著性水平(通常是0.05),那么就可以拒绝原假设,即序列不是白噪声。在这个检验结果中,LB统计量为37.47,p-value为9.29e-10,p-value远小于0.05,因此可以拒绝原假设,即序列不是白噪声。
3.模型拟合
拟合SARIMA模型需要确定其参数。SARIMA模型有三个重要的参数:p、d和q,分别代表自回归阶数、差分阶数和移动平均阶数;另外还有季节性参数P、D和Q,分别代表季节性自回归阶数、季节性差分阶数和季节性移动平均阶数。根据经验和统计方法,可以通过观察样本自相关函数ACF和偏自相关函数PACF,选取最佳的p、d、q和P、D、Q参数,使得残差序列的自相关函数和偏自相关函数均值为0。
时间序列定阶
def draw_acf(data):# 利用ACF判断模型阶数plot_acf(data)plt.title("序列自相关图(ACF)")plt.show()def draw_pacf(data):# 利用PACF判断模型阶数plot_pacf(data)plt.title("序列偏自相关图(PACF)")plt.show()def draw_acf_pacf(data):f = plt.figure(facecolor='white')# 构建第一个图ax1 = f.add_subplot(211)# 把x轴的刻度间隔设置为1,并存在变量里x_major_locator = MultipleLocator(1)plot_acf(data, ax=ax1)# 构建第二个图ax2 = f.add_subplot(212)plot_pacf(data, ax=ax2)plt.subplots_adjust(hspace=0.5)# 把x轴的主刻度设置为1的倍数ax1.xaxis.set_major_locator(x_major_locator)ax2.xaxis.set_major_locator(x_major_locator)plt.show()
(1)确定和
的阶数:当对原序列进行了
阶差分和
为
的
阶差分后序列为平稳序列,则可以确定
,
,
的值。
(2)确定和
的阶数:
- 首先对平稳化后的时间序列绘制ACF和PACF图;
- 通过观察季节性
处的拖尾/截尾情况来确定
的值
- 观察短期非季节性
的值
之前已经在步骤三处确定了。对于剩下的参数,将依据如下的ACF和PACF图确定。下图的横坐标
是以月份为单位。
非季节性部分:
对于,在
后,
图拖尾,
图截尾。同样地,对于
,在
后,
图截尾,
图截尾。同样地,对于
,在
,ACF图截尾,PACF图拖尾。
季节性部分:
,
的确定和非季节性一样,不过需要记得滞后的间隔为60。
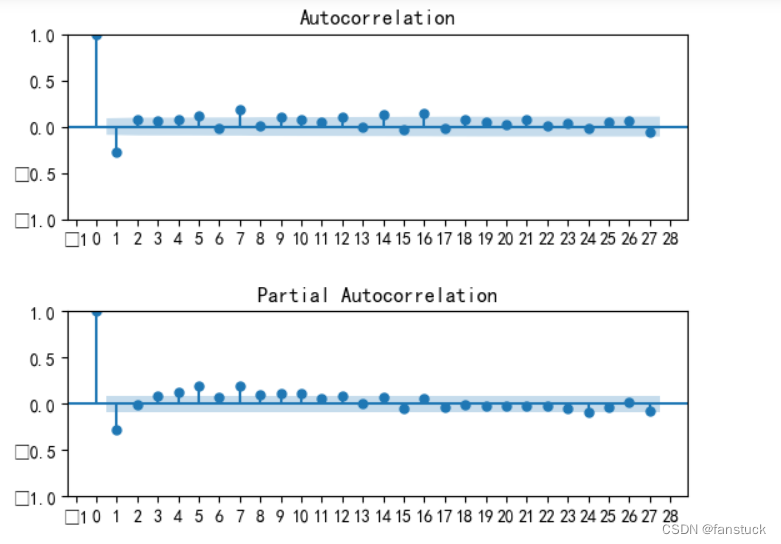
AR模型:自相关系数拖尾,偏自相关系数截尾;
MA模型:自相关系数截尾,偏自相关函数拖尾;
ARMA模型:自相关函数和偏自相关函数均拖尾。
4.模型预测
在完成模型的拟合和检验后,可以使用该模型进行预测。预测方法包括基于历史数据的单步预测和基于当前数据的多步预测。在进行预测时,需要使用已知数据进行模型参数的估计,并将预测结果与真实值进行比较,以评估预测结果的准确性。
这里使用了pmdarima.auto_arima()方法。这个方法可以帮助我们自动确定的参数,直接输入数据,设置auto_arima()中的参数则可。
之前我们是通过观察ACF、PACF图的拖尾截尾现象来定阶,但是这样可能不准确。实际上,往往需要结合图像拟合多个模型,通过模型的AIC、BIC值以及残差分析结果来选择合适的模型。
1、构建模型
import pmdarima as pm
将数据分为训练集data_train和测试集data_test 。
split_point = int(len(time_series) * 0.85)
# 确定训练集/测试集
data_train, data_test = time_series[0:split_point], time_series[split_point:len(time_series)]
# 使用训练集的数据来拟合模型
built_arimamodel = pm.auto_arima(data_train,start_p=0, # p最小值start_q=0, # q最小值test='adf', # ADF检验确认差分阶数dmax_p=5, # p最大值max_q=5, # q最大值m=12, # 季节性周期长度,当m=1时则不考虑季节性d=None, # 通过函数来计算dseasonal=True, start_P=0, D=1, trace=True,error_action='ignore', suppress_warnings=True,stepwise=False # stepwise为False则不进行完全组合遍历)
print(built_arimamodel.summary())
相关结果如下,从Model可以看出确定的参数与之前确定的参数大致相同。
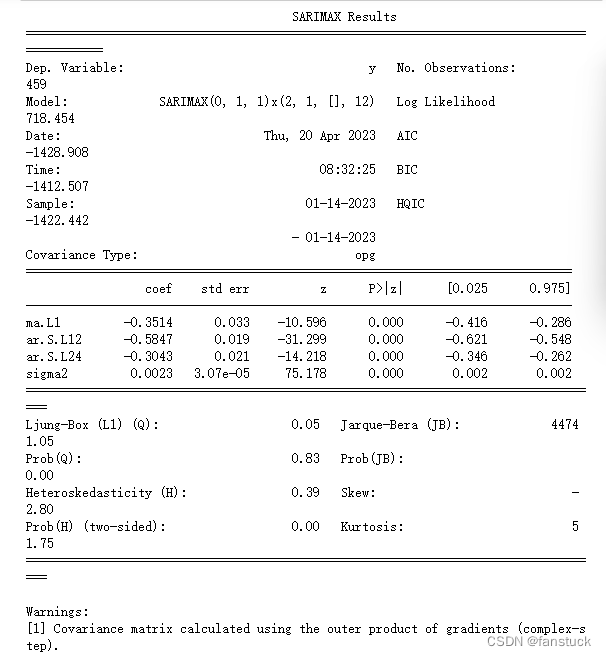
模型为SARIMAX(0, 1, 1)x(2, 1, [], 12)。其中,(0, 1, 1)表示模型的ARIMA部分是一个一阶差分的MA(1)模型,(2, 1, [], 12)表示模型的季节性AR部分是一个P=2的季节性AR模型,季节周期为12个时间点。下面的系数表显示了模型中每个系数的点估计值、标准误、z统计量和对应的p值。此外,还列出了残差方差的点估计值和Ljung-Box检验和Jarque-Bera检验的结果。Ljung-Box检验用于检验残差是否存在自相关,Jarque-Bera检验用于检验残差是否符合正态分布假设。该模型中,残差的Ljung-Box检验p值为0.83,表明残差不存在显著自相关;而Jarque-Bera检验的p值为0.00,表明残差不符合正态分布假设。此外,模型的拟合效果还可以通过AIC、BIC和HQIC来评价,这些信息也包含在结果汇总表中。
2.模型识别

3.需求预测
# 进行多步预测,再与测试集的数据进行比较
pred_list = []
for index, row in data_test.iterrows():# 输出索引,值# print(index, row)pred_list += [built_arimamodel.predict(n_periods=1)]# 更新模型,model.update()函数,不断用新观测到的 value 更新模型built_arimamodel.update(row)# 预测时间序列以外未来的一次predict_f1 = built_arimamodel.predict(n_periods=1)print('未来一期的预测需求为:', predict_f1[0])

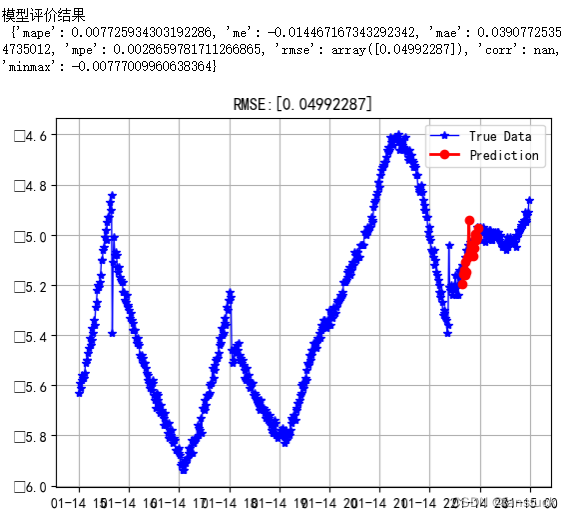
4.结果评估
# ARIMA模型评价
def forecast_accuracy(forecast, actual):mape = np.mean(np.abs(forecast - actual)/np.abs(actual))me = np.mean(forecast - actual)mae = np.mean(np.abs(forecast - actual))mpe = np.mean((forecast - actual)/actual)# rmse = np.mean((forecast - actual)2)0.5 # RMSErmse_1 = np.sqrt(sum((forecast - actual) 2) / actual.size)corr = np.corrcoef(forecast, actual)[0, 1]mins = np.amin(np.hstack([forecast[:, None], actual[:, None]]), axis=1)maxs = np.amax(np.hstack([forecast[:, None], actual[:, None]]), axis=1)minmax = 1 - np.mean(mins/maxs)return ({'mape': mape,'me': me,'mae': mae,'mpe': mpe,'rmse': rmse_1,'corr': corr,'minmax': minmax})
- MAPE (Mean Absolute Percentage Error):平均绝对百分比误差,是预测值与实际值之间的绝对误差与实际值之比的平均值。
- ME (Mean Error):平均误差,是预测值与实际值之间的差的平均值。
- MAE (Mean Absolute Error):平均绝对误差,是预测值与实际值之间的绝对误差的平均值。
- MPE (Mean Percentage Error):平均百分比误差,是预测值与实际值之间的误差与实际值之比的平均值。
- RMSE (Root Mean Square Error):均方根误差,是预测值与实际值之间的差的平方的平均值的平方根。
- Corr (Correlation between the predicted and true values):预测值与实际值之间的相关性。
- MinMax (Minimum and maximum prediction error):最小和最大预测误差。
需要注意的是,这些评价指标的解释和使用可能因具体应用场景而有所不同。
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。