HTTP和TCP协议的队头阻塞

队头阻塞(Head-of-line blocking)其实有两种,一种是 TCP 队头阻塞,另一种是 HTTP 队头阻塞,而这两者之前其实还存在一定的联系,毕竟 HTTP1/2 是建立在 TCP 协议之上的应用层协议,另外还有HTTP3对队头阻塞的解决。
1、HTTP/1.x 的队头阻塞
HTTP/1.x 有个问题叫队头阻塞,即一个连接同时只能有效地承载一个请求。
问题:HTTP/1.1 是一个纯文本协议,它只在有效荷载(payload)的前面附加头(headers),在资源块(resource chunks)之间不使用分隔符。它不会进一步区分单个资源与其他资源。HTTP 规定报文必须是“一发一收”,这就形成了一个先进先出的串行队列。
“请求 - 应答”模式则加剧了 HTTP 的性能问题,这就是著名的“队头阻塞”(Head-of-line blocking),当顺序发送的请求序列中的一个请求因为某种原因被阻塞时,在后面排队的所有请求也一并被阻塞,会导致客户端迟迟收不到数据。
比如:当浏览器发送给服务器的资源包括:js(大资源块)、css(小资源块)等内容,但是服务器不能对他们进行分块解析,就会导致需要等到js块解析完毕后,才去解析css块。
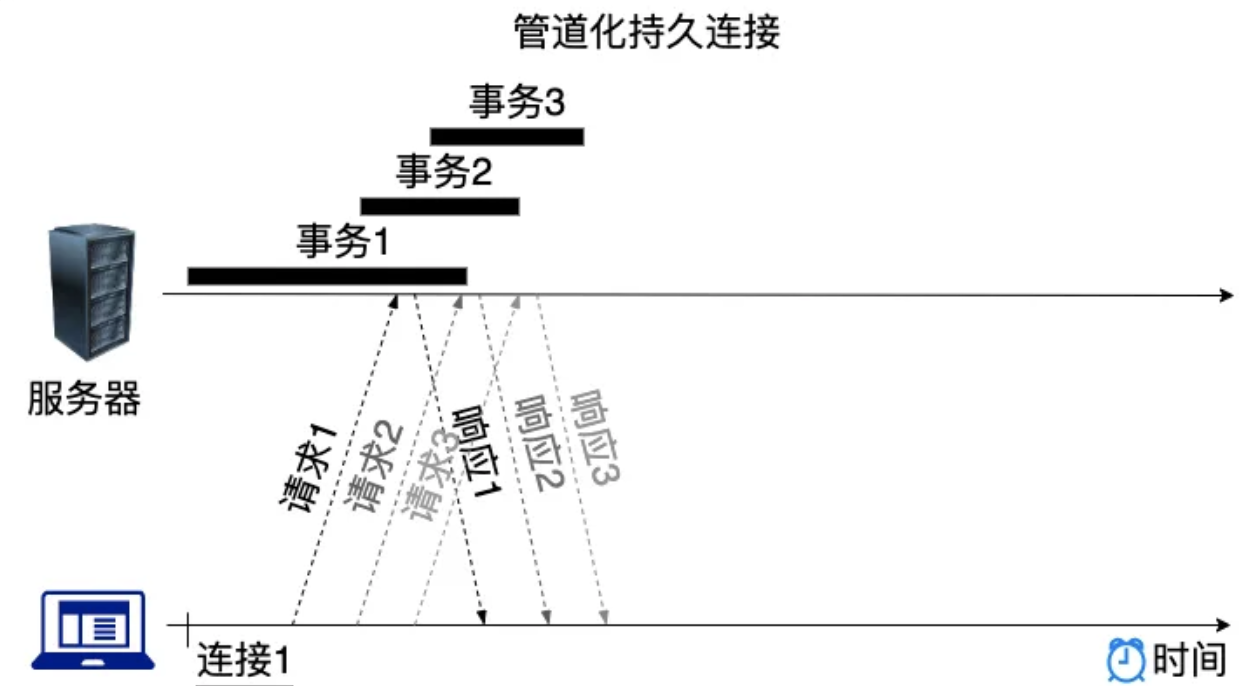
一种解决办法,浏览器打开许多并行TCP连接,但这既不高效,也不可扩展。
2、TCP传输层队头阻塞
TCP 是面向连接的、可靠的流协议,其为上层应用提供了可靠的传输,保证将数据有序并且准确地发送至接收端。为了做到这一点,TCP采用了“顺序控制”和“重发控制”机制,另外还使用“流量控制”和“拥塞控制”来提高网络利用率。
应用层(如HTTP)发送的数据会先传递给传输层(TCP),TCP 收到数据后并不会直接发送,而是先把数据切割成 MSS 大小的包,再按窗口大小将多个包丢给网络层(IP 协议)处理。

IP 层的作用是“实现终端节点之间的通信”,并不保证数据的可靠性和有序性,所以接收端可能会先收到窗口末端的数据,这个时候 TCP 是不会向上层应用交付数据的,它得等到前面的数据都接收到了才向上交付,所以这就出现了队头阻塞,即队头的包如果发生延迟或者丢失,队尾必须等待发送端重新发送并接收到数据后才会一起向上交付。
即:如果一个 TCP 包丢失,所有后续的包都需要等待它的重传,即使它们包含来自不同流的无关联数据。
当然 TCP 有快重传和快恢复机制,一旦收到失序的报文段就立即发出重复确认,并且接收端在连续收到三个重复确认时,就会把慢开始门限减半,然后执行拥塞避免算法,以快速重发丢失的报文。
3、HTTP/2(基于 TCP)的队头阻塞
使用 SPDY协议 作为 HTTP/2 的起点,并使用多路复用(单个连接上可以进行并行交错的请求和响应,之间互不干扰),解决了队头阻塞的问题,不过 TCP 本身的队头阻塞是无法避免的,而且对其影响更大,因为多个同域名的请求都只会使用同一个 TCP 连接,不会有多个并行连接。
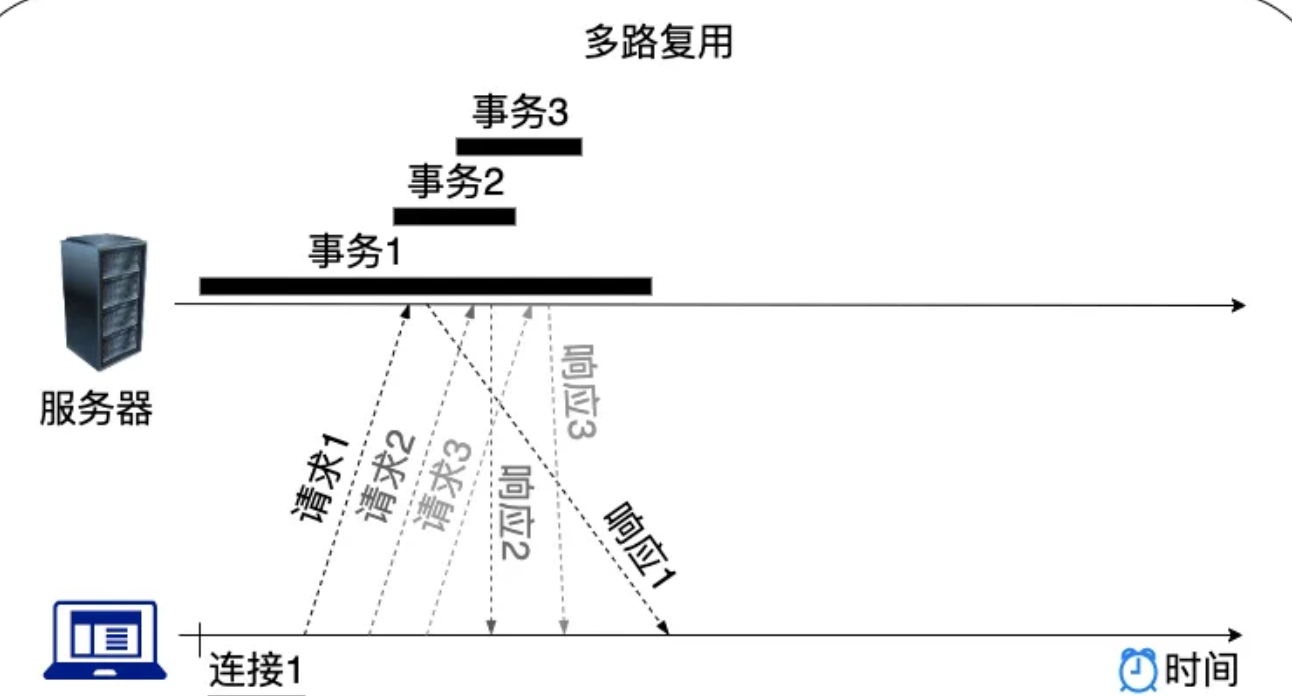
目标:回到单个 TCP 连接,正确地复用资源块,解决http队头阻塞问题。
解决方案:在资源块之前添加了数据帧(DATA frame),标识每个资源块属于哪个“流”(stream)。这些数据帧主要包含两个关键的元数据。
首先:下面的块属于哪个资源。每个资源的“字节流(bytestream)”都被分配了一个唯一的数字,即流id(stream id)。
第二:块的大小是多少。
这样报文到达服务端之后,服务端应用可以区分哪些属于同一个资源快,进而可以进行复用。即:解决了“应用层”队头阻塞。
4、HTTP/3(基于 QUIC)的队头阻塞
由于tcp本身的限制,难以对其进行改变,使其具有”流“的意识。
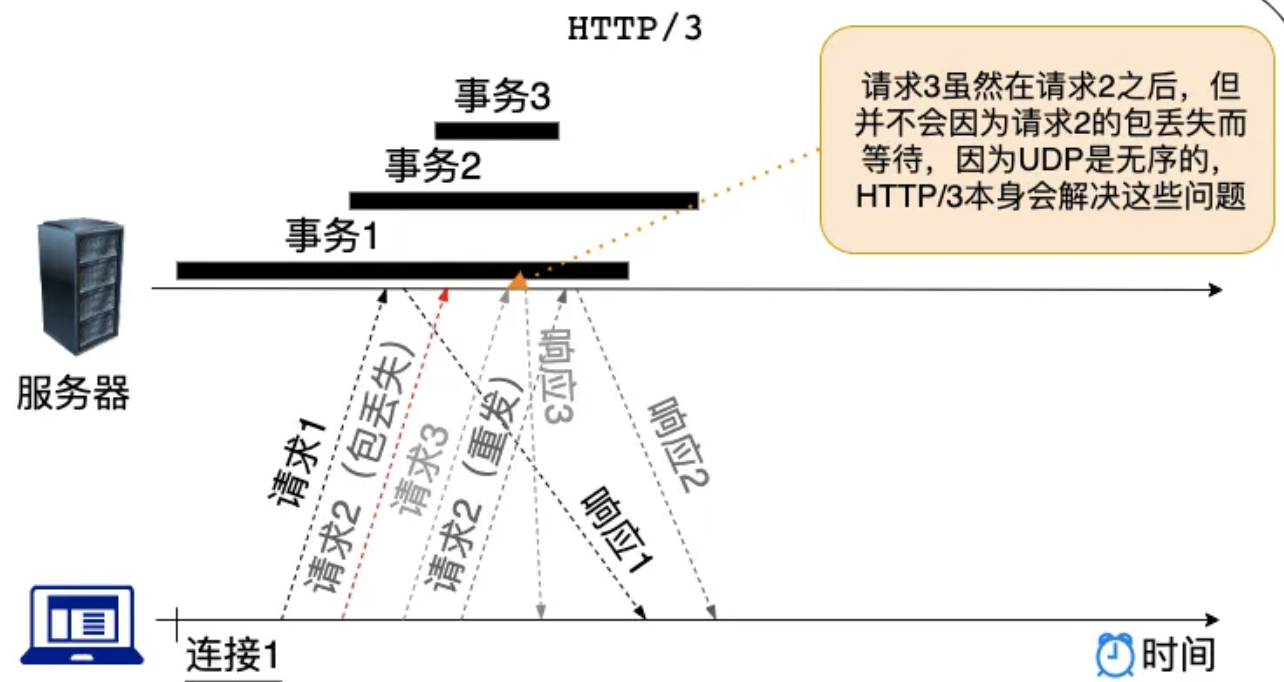
选择的替代方法是以 QUIC 的形式实现一个全新的传输层协议。它运行在不可靠的 UDP 协议之上。但它包括 TCP 的所有特性(可靠性、拥塞控制、流量控制、排序等),且集成了TLS,不允许未加密的连接。故创建了 HTTP/3,运行在QUIC协议上。