医学图像分割之TransUNet

目录
一、背景
二、提出问题
三、解决问题
四、网络结构详解
CNN部分(ResNet50的前三层)
transformer部分
U-Net的decoder部分
五、模型性能
开头处先说明下TransUNet的地位:它是第一个将transformer用于U型结构的网络。
一、背景
医学图像分割是发展卫生保健系统的先决条件,尤其对疾病诊断和质量方案。在各种医学图像分割模型中,U型结构,也就是U-Net非常流行。
二、提出问题
- 由于卷积运算的内在局限性,或者说是卷积运算中,感受野小的原因,导致U-Net在建模过程中,远程依赖方面受限。
- transformer是全局自注意机制的可替代结构。但由于transformer的低级细节不足,导致其定位能力受限。
三、解决问题
在解决U型结构感受野小、远程依赖受限的问题上,很多作者给出的解决办法是使用自注意力机制。由于Transformer中自带自注意力机制,作者是第一个将transformer和U-Net相结合的人。
- 由于U-Net结构在医学图像分割中非常流行,可以说是默认的医学图像分割的backbone了,所以作者选择在U-Net结构上进行改编。
- 由于transformer的输入为1D的序列,所以在其训练的所有阶段只关注了建模的上下文信息,导致缺少含有细节定位信息的高分辨率特征。所以作者选择将transformer与U-Net结构相结合,将transformer作为U型结构的encoder部分。
- transformer作为encoder部分,对transformer后的编码特征是
,为了恢复空间信息,将
,然后使用U-Net的decoder部分,上采样恢复分辨率至 H*W。虽然也能产生合理的结果,但结果比较粗糙,缺少高分辨率的细节信息。也就是说此时的结构不是transformer的最佳应用,因为通常
比H*W小很多,分辨率在恢复至H*W过程中,不可避免导致定位信息的损失。为了弥补这种定位细节信息的损失,作者继续提出了CNN-Transformer的混合结构。
- CNN-Transformer作为U型结构的encoder部分。因为CNN能提取到低级定位细节信息,正好弥补Transformer缺少低级定位信息的不足。在此部分,作者选择使用resnet50的前3阶段作为CNN部分。将resnet50第三阶段得到的特征图作为transformer的patch来源。从而使得transUNet的U型结构得到闭环。
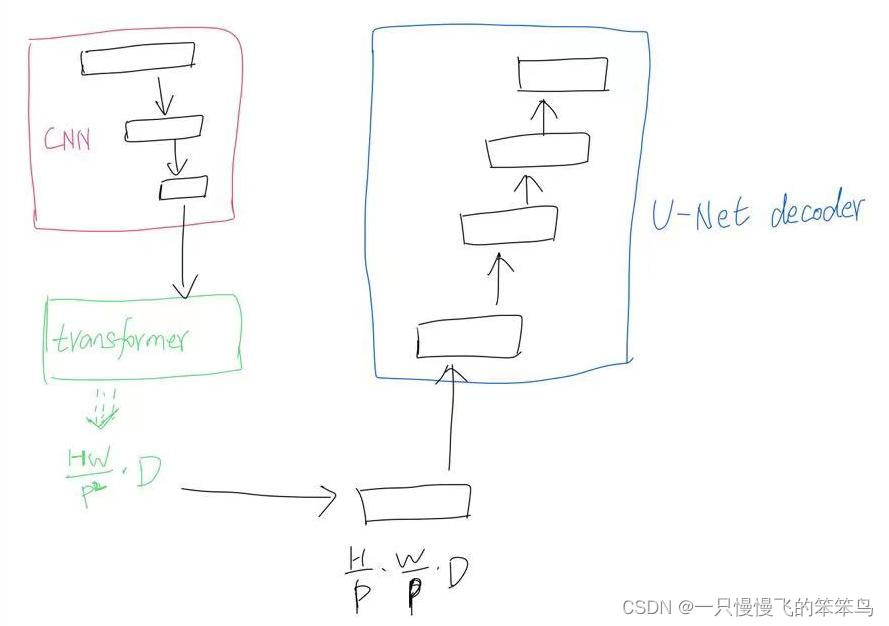
图1 TransUNet结构简图
四、网络结构详解
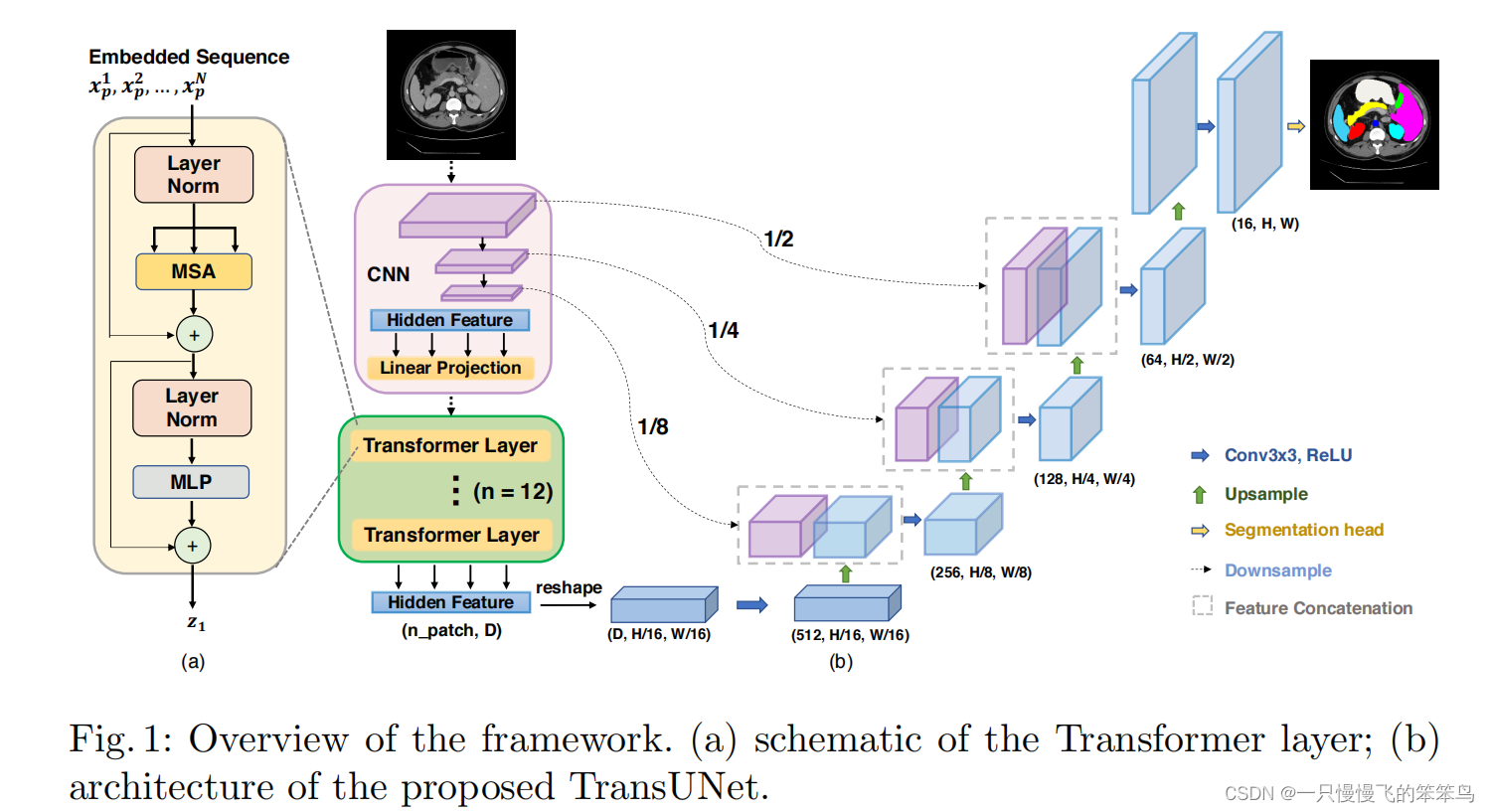
从图中也可以看出,TransUNet的网络结构可以分为三部分学习,分别是CNN部分(resnet50的前三层)、transformer部分、U-Net的decoder部分。
CNN部分(ResNet50的前三层)
CNN部分作者选用了ResNet50的前三层,至于为什么CNN选用的ResNet50,作者并没有给出原因。我的理解是:U-Net的decoder部分除去encoder5外,还有4层,从上往下计数,decoder4和transformer的结果进行skip-connection,上面还剩3层decoder,所以此处采用的ResNet50的前三层,方便后续的跳跃连接 。
TranUNet中的该部分代码中,要将这三层的每层结果进行保存,每层的结果还要用于skip-connection,除此之外,第三层的特征图还要产生一系列的patches,作为transformer的输入内容。ResNet50的前三层结构如下图所示:
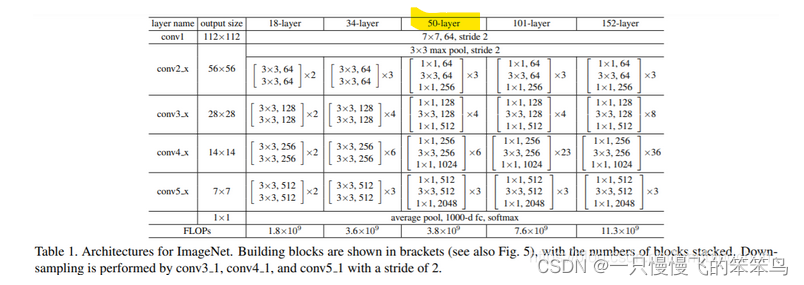

图3 ResNet50网络结构
transformer部分
此处的transformer部分采用了12层,也就是将transformer运算重复了12次。首先将CNN部分的第三层获得的特征图进行P=16处理,获得16*16=256个patches。将一系列patches输入到transformer模块中,获得 (n_patch, D)= 维度的结果,为了恢复特征图的空间结构,reshape至
,然后进行上采样操作。
关于transformer的具体实现,我想仔细学一些Vis Transformer,然后出一篇博客,详细讲解。
U-Net的decoder部分
此部分和U-Net的decoder部分完全一样,后面专门出一篇U-Net文章。
五、模型性能
在我的数据集CT图像上进行训练,发现TransUNet的性能并没有很好,是不如UNet的。TransUNet的dice是0.8171,而UNet的dice是0.9488。TransUNet的泛化能力不是很好。
以上是本人对TransUNet的理解,欢迎大家一起交流学习。
参考:经典网络ResNet介绍_fengbingchun的博客-CSDN博客