重写equlas时为什么一定要重写hashcode方法?

equals方法和hashCode方法都是Object类中的两个基本方法,它们共同来判断两个对象是否相等。为什么要两个方法结合起来使用呢?原因是在 ‘性能’ 上面。
使用过 hashMap 我们知道,通过 hash 计算 ,可以快速的在常量时间内找到某个值的存储位置。如果没有 hash 值我们的查找可能是通过遍历一个个询问比较找到这个对象再去比较值。显然这种遍历比较的方式效率比 hash 定位低。这就是 hash 和 hashCode 的存在意义。
hashCode 寻址:(高效)
遍历寻址:(低效率)

所以在进行比较两个对象是否相等时候会先进行 hashCode 比较 hash 值是否相等,相等再进行 equals 比较内容是否相同,否则直接不同(hash 值相同对象不一定相同,hash 值不相同对象一定不相同)。以配合的方式来提交效率。
那为什么不直接使用 hashCode 就确定两个对象是否相等呢?
这是因为不同对象的 hashCode 可能相同;但 hashCode 不同的对象一定不相等,所以使用 hashCode 可以起到快速初次判断对象是否相等的作用。
但即使知道了以上基础知识,依然解决不了本篇的问题,也就是:重写 equals 时为什么一定要重写 hashCode?要想了解这个问题的根本原因,我们还得先从这两个方法开始说起。
1.equals 方法
Object 中的 equals 方用于检测两个对象的引用是否相同,如果引用相同那他们一定相同。
equals 方法源码实现:
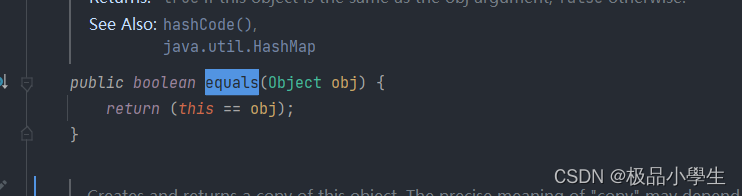
通过比较对象引用其实不具有参考价值。大多数比较的情况下,我们用来比较对象是否相同,这就完全没有意义(每一个对象的引用都不相同)
通过以下实例,可以说明这个问题:
public class equals {public static void main(String[] args) {Student s1 = new Student("极品小學生",18);Student s2 = new Student("极品小學生",18);System.out.println(s1.equals(s2));}
}class Student {private String name;private int age;public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}public Student(String name, int age) {this.name = name;this.age = age;}
}
运行结果:
重写 equals 方法
@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;return age == student.age && Objects.equals(name, student.name);}运行结果:

因此,我们在判断两个对象是否相等时,一定要重写 equals 方法,这就是为什么要重写 equals 的原因。
2.hashCode 方法
hashCode 中文为散列码,他是由对象推导出的一个整形值,这个值是随意的可能是任何一个值。
注意:散列码没有规律。如果x,y是两个不同的对象,x.hashCode()和y.hashCode()基本上不会相同(由于哈希值只是一个整数,它的范围是有限的),但是如果两个对象的值相同,那他们的hashCode 一定相同。
hashCode,源码实现:
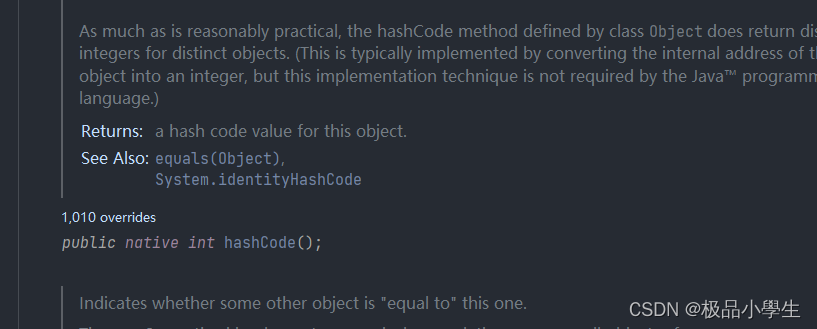
从源码中看出,Object 中的 hashCode 调用的本地方法(native),返回一个 int 类型整数。
相等的值 hashCode 一定相同的示例:
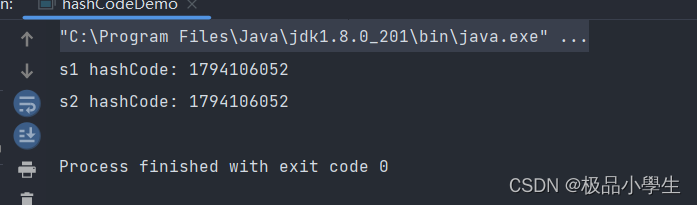
public class hashCodeDemo {public static void main(String[] args) {String s1 = "hello world";String s2 = "hello world";System.out.println("s1 hashCode: " + s1.hashCode());System.out.println("s2 hashCode: " + s2.hashCode());}
}以上代码运行结果,如下图所示:
不同值的 hashCode 可能相同实例:
public class hashCodeDemo {public static void main(String[] args) {String s1 = "Aa";String s2 = "BB";System.out.println("s1 hashCode: " + s1.hashCode());System.out.println("s2 hashCode: " + s2.hashCode());}
}

3.为什么要一起重写?
1.为了提高查询效率,先通过 hashCode 比较再比较 equals 方法。
2.保证 Set 方法正常使用
Set 集合用来保存不同对象的,相同的对象就会被 Set 合并,保留下一份。
Set 正常使用演示:
public class hashCodeDemo {public static void main(String[] args) {Set<String> set = new HashSet<>();set.add("小红");set.add("小红");set.add("小明");set.add("小明");set.add("老六");System.out.println("Set 集合长度为: " + set.size());for (String s : set) {System.out.println(s);}}以上代码执行结果:如下图所示:
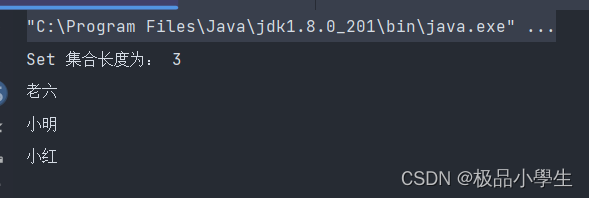
从实例中看出,重复的对象被 Set 集合合并,这也是 Set 集合最大特点: 去重
Set 集合 '异常'演示
然而,如果我们在 Set 集合中存储的是,只重写了 equals 方法的自定义对象时,有趣的事情就发生了,如下代码所示:
public class equals {public static void main(String[] args) {Set<Student> set = new HashSet<>();Student s1 = new Student("极品小學生",18);Student s2 = new Student("极品小學生",18);set.add(s1);set.add(s2);System.out.println("Set 集合长度为: " + set.size());for (Student s : set) {System.out.println(s);}}
}class Student {private String name;private int age;@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student student = (Student) o;return age == student.age && Objects.equals(name, student.name);}@Overridepublic String toString() {return "Student{" +"name='" + name + '\\'' +", age=" + age +'}';}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}public Student(String name, int age) {this.name = name;this.age = age;}
}
以上代码运行结果:如下图所示:
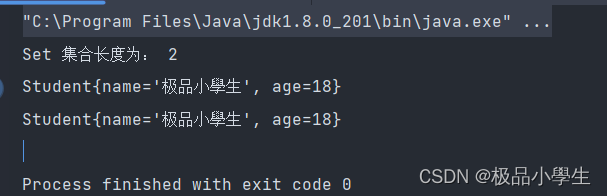
可以看出,两个相同内容的对象 被 Set 集合加入了两次并没有进行去重操作 。这样的结果显然不是我们想要的。首先我们要知道 Set 集合中,元素的唯一性是通过 equals 和 hashCode 方法共同来判断的。所以我们要重写 hashCode 方法。
重写了 hashCode 方法:
@Overridepublic int hashCode() {return Objects.hash(name, age);}
运行结果:
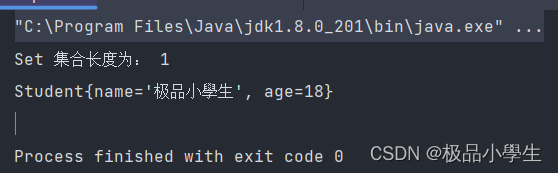
注意:Set 集合去重问题需要重写 equals 和 hashCode 两个方法,缺一种都是不可以的。
4.原因分析
在 Set 集合中,元素的唯一性是通过 equals 和 hashCode 方法共同来判断的。当往 Set 集合中添加一个元素时,首先会计算该元素的 hashCode 值,然后根据该值查找集合中是否已存在与该元素 hashCode 值相等的元素。
如果存在相等的 hashCode 值,则会继续调用它们的 equals 方法进行比较。如果两个元素的 equals 方法返回 true,那么就认为这两个元素相等,并且后来添加的元素将不被加入到集合中。
如果不存在相等的 hashCode 值,则认为当前元素与集合中的所有元素都不相等,直接将其加入到集合中。
因此,在 Set 集合中去重操作是基于 hashCode 和 equals 两个方法实现的,确保了集合中不会存在相同的元素。同时,为了保证正确性,我们需要在自定义对象的类中同时重写 equals 和 hashCode 方法,以便让它们能够正确地工作。
总结
hashCode 和 equals 方法 结合一起使用来提高判断对象是否相等的效率
因为 Set 集合通过 hashCode 和 equals 两个方法共同判断两个对象是否重复,所以要解决 Set 集合的异常,也需要重写这两种方法。