FlinkX的安装与使用(异构数据同步工具——flinkx)

异构数据同步工具——flinkx - 知乎
一、概要简介
FlinkX是由袋鼠云开源基于Flink的分布式离线和实时相结合的数据同步框架,既可以采集静态的数据比如:MYSQL,HDFS等,也可以采集实时变化的数据比如:MYSQL BINLOG,KAFKA等。目前官方已经支持多种异构数据源之间高效的数据同步。
二、架构设计
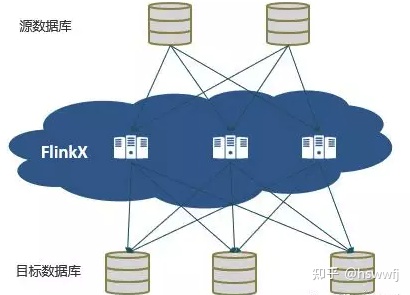
FlinkX整体架构设计采用Framework+plugin模式。不同数据源被抽象成不同的Reader plugin和Writer plugin,使用方只需要在配置文件配置相应插件参数就可以实现数据迁移,插件扩展上用户只需要实现Reader和Writer接口,其他的框架会给予支持。理论上FlinkX可以横向扩展支持任意类型数据源的同步。
三、支持的数据源
FlinkX目前已经支持十几种数据源:


四、基础特性
4.1 脏数据管理
异构系统执行大数据迁移不可避免的会有脏数据产生,脏数据会影响同步任务的执行,FlinkX的Writer插件在写数据是会把以下几种类型作为脏数据写入脏数据表里:
1、类型转换错误
2、空指针
3、主键冲突
4、其它错误
4.2 流控管理
大数据同步时在负载高的时候有时候会给系统带来很大的压力,FlinkX使用令牌桶限流方式限速,当源端产生数据的速率达到一定阈值就不会读取数据。
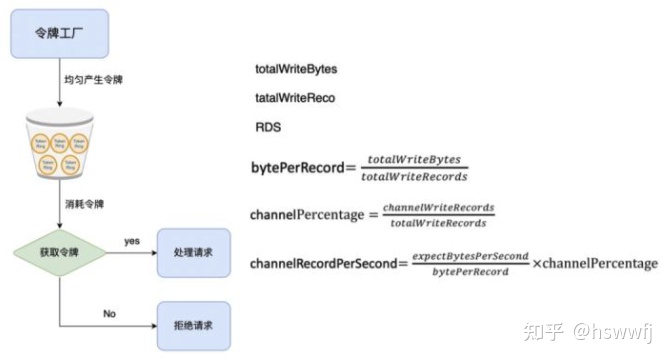
4.3 断点续传
部分插件支持通过Flink的checkpoint机制从失败的位置恢复任务。断点续传对数据源 ️强制要求:
1、中必须包含一个升序的字段,比如主键或者日期类型的字段,同步过程中会使用checkpoint机制记录这个字段的值,任务恢复运行时使用这个字段构造查询条件过滤已经同步过的数据,如果这个字段的值不是升序的,那么任务恢复时过滤的数据就是错误的,最终导致数据的缺失或重复。
2、数据源必须支持数据过滤,如果不支持的话,任务就无法从断点处恢复运行,会导致数据重复。
3、目标数据源必须支持事务,比如关系数据库,文件类型的数据源也可以通过临时文件的方式支持。
五、运行原理
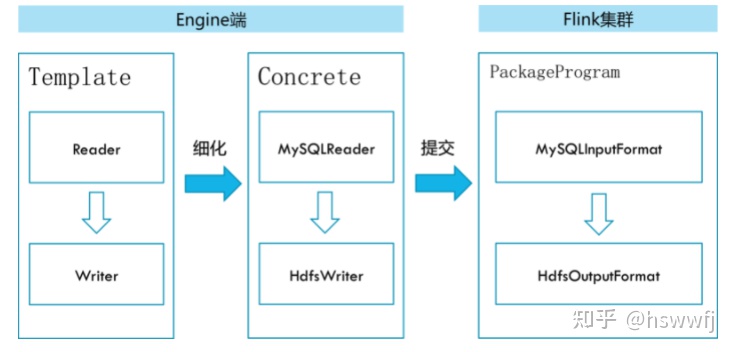
FlinkX底层实现上依赖Flink,数据同步任务会包装成StreamGraph在Flink上执行。
六、系统安装
6.1 flink集群安装
wget https://archive.apache.org/dist/flink/flink-1.10.3/apache-flink-1.10.3.tar.gz.asc
tar -zxvf apache-flink-1.10.3.tar.gz.asc# 目录修改 flink-conf.yaml 配置文件
cd ../conf
rest.bind-port: 8081# 启动flink
./bin start-cluster.sh 查看集群启动情况
在浏览器查看集群启动情况http://localhost:8081

6.2 安装flinkX
wget https://github.com/DTStack/flinkx/archive/1.10_release.zip
unzip 1.10_release.zip
cd flinkx-1.10_release#源码编译
mvn clean package -DskipTests#编译完之后在根目录生成syncplugins目录,里面包含启动类以及各种插件到此所有系统准备工作完毕。
七、配置示例
项目工程example目录提供了各个插件配置样例。由于我本地只安装了mysql,我这边就以mysql to mysql作为演示。
⚠️在同步之前需要确保目的数据库和表已经存在,否则会报错。
7.1 源表数据:

7.2 配置文件
配置文件mysql_mysql_batch.json:
{"job": {"content": [{"reader": {"name": "mysqlreader","parameter": {"column": [{"name": "id","type": "int"},{"name": "name","type": "string"},{"name": "age","type": "int"}],"username": "root","password": "root","connection": [{"jdbcUrl": ["jdbc:mysql://localhost:3306/rc?useSSL=false"],"table": ["my"]}]}},"writer": {"name": "mysqlwriter","parameter": {"username": "root","password": "test","connection": [{"jdbcUrl": "jdbc:mysql://localhost:3306/rc?useSSL=false","table": ["my_sync"]}],"writeMode": "insert","column": [{"name": "id","type": "int"},{"name": "name","type": "string"},{"name": "age","type": "int"}]}}}],"setting": {"speed": {"channel": 1,"bytes": 0}}}}7.3 local模式启动
bin/flinkx \\
-mode local \\
-job bin/mysql_mysql_batch.json \\
-pluginRoot syncplugins \\
-flinkconf flinkconf7.4 standalone模式启动
bin/flinkx \\
-mode standalone \\
-job bin/mysql_mysql_batch.json \\
-pluginRoot syncplugins \\
-flinkconf /Users/hsw/Documents/project_install/flink/flink-1.12.2/conf7.5 执行之后结果:

至此数据已经完美同步过来了。