〖Python网络爬虫实战⑰〗- 网页解析利器parsel实战

- 订阅:新手可以订阅我的其他专栏。免费阶段订阅量1000+
python项目实战
Python编程基础教程系列(零基础小白搬砖逆袭)
- 说明:本专栏持续更新中,目前专栏免费订阅,在转为付费专栏前订阅本专栏的,可以免费订阅付费专栏,可报销(名额有限,先到先得)。
- 作者:爱吃饼干的小白鼠。Python领域优质创作者,2022年度博客新星top100入围,荣获多家平台专家称号。
最近更新
〖Python网络爬虫实战⑯〗- 网页解析利器parsel
🌟 上节回顾
我们在上一节我们学习了parsel的基本语法,我们知道其可以使用xpath和css还有正则表达式。parsel 是一个融合了 XPath、CSS Selector 和正则表达式的提取库,功能强大又灵活。
⭐️网页解析利器parsel实战
我们以实际的案例,来具体了解学习其功能。我们在这里重点讲解其两种方式。一个是XPATH,一个是CSS。我们以某网为例,获取其新闻标题。
🌟 parsel简介
Parsel是一个用于解析JSON数据的Python库。它提供了一个简单易用的API,可以轻松地从JSON文件或字符串中解析数据。可以对 HTML 和 XML 进行解析,并支持使用 XPath 和 CSS Selector 对内容进行提取和修改,同时它还融合了正则表达式提取的功能。功能灵活而又强大。
🌟发送请求
我们先确定目标网址,我们为了让新手更好的学习,我们这里以中国新闻网为例,不讲太复杂的案例。如果,想更好的提升自己,可以尝试学习我之前发的Python项目实战——外汇牌价(附源码)。这篇文章使用的方法也是parsel。
我们发送请求,获取数据。我们相信大家这里的代码都会写了。
import parsel
import requestsurl = 'https://www.xxxxx.com/importnews.html'responses = requests.get(url)
responses.encoding=responses.apparent_encoding
print(responses.text)我们使用requests.get()函数来发送HTTP请求,并将响应存储在responses变量中。在这个例子中,我们将响应的文本内容存储在responses.text变量中。
🌟解析数据
我们获取到了网页源代码之后,我们使用parsel方法对其解析,处理网页源代码。
selector = parsel.Selector(responses.text)我们使用 parsel 库的 Selector 对象来选择 responses.text 中的特定元素。
我们使用开发者工具,观察标题在哪个标签位置里面。
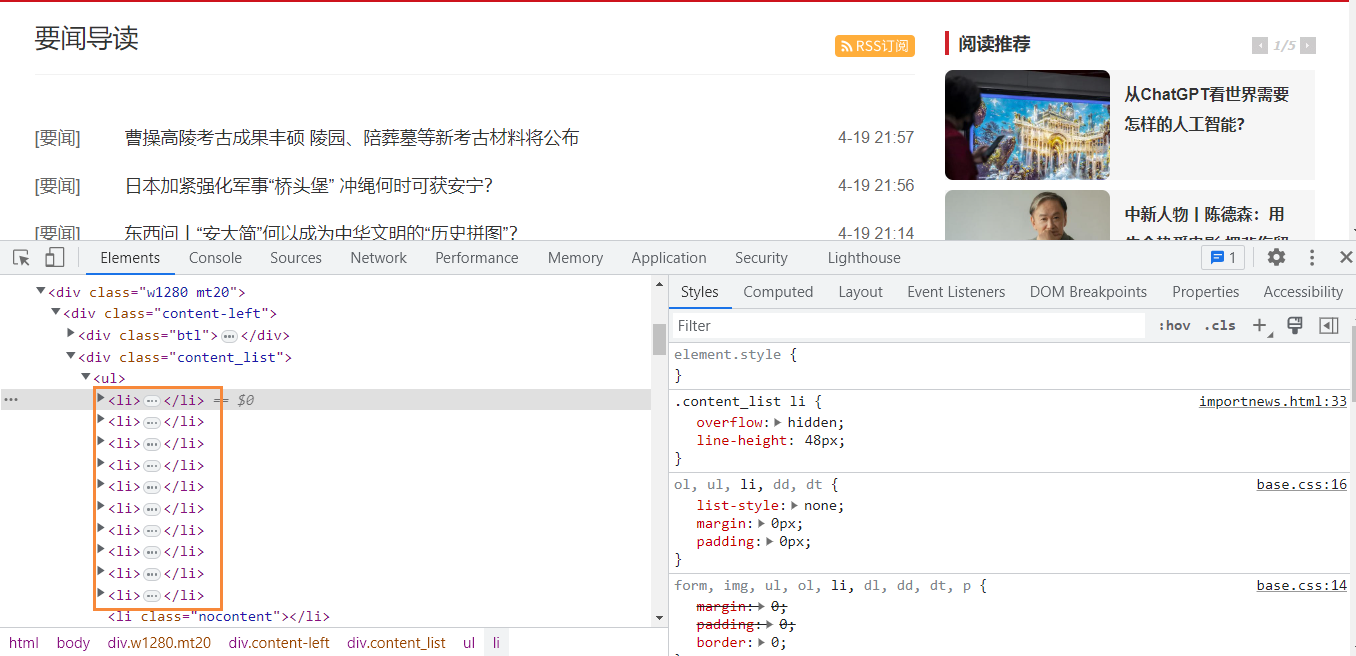
由上图,我们可以看到,我们标题信息就在<li>标签里面。我们可以提取<li>标签里面所有的内容。在这里,我们只获取新闻的标题内容。下面我们将用两种方式获取。
✨XPATH方式
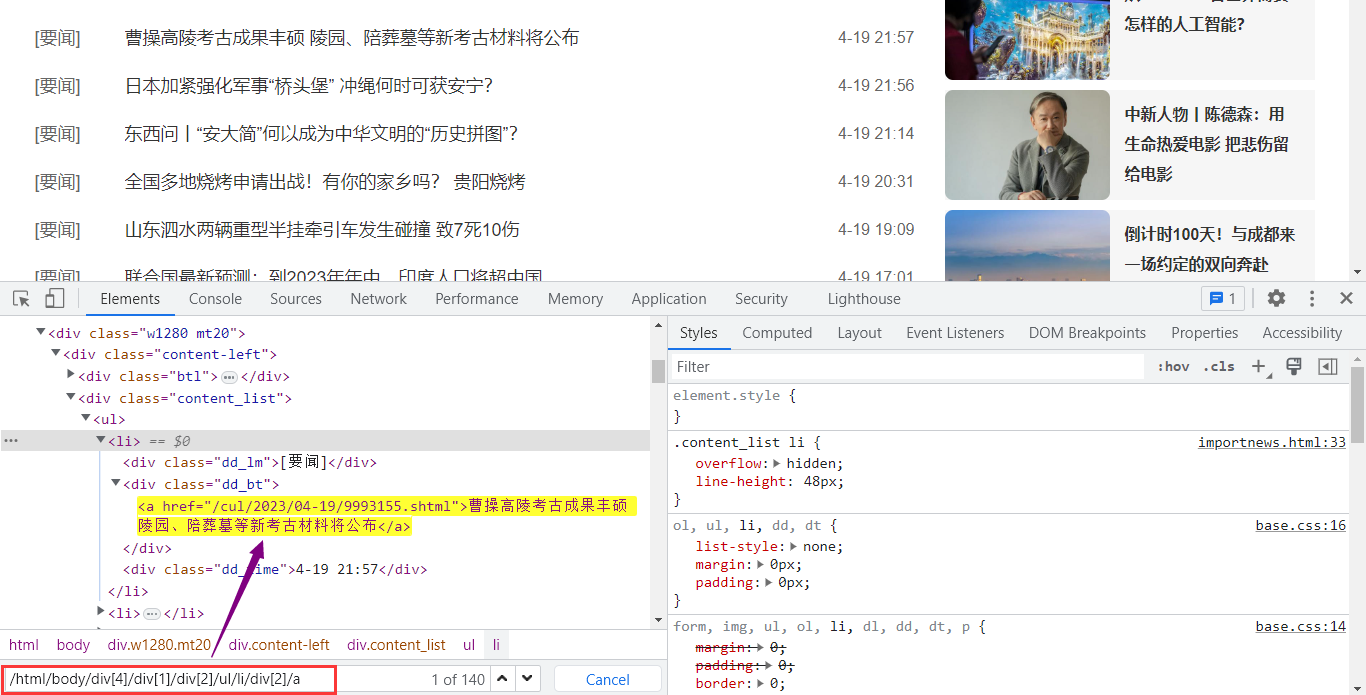
我们很容易获取到了标签所在的位置,大家不会写的话,可以右击copy—xpath。我们来写代码。
titles = selector.xpath('/html/body/div[4]/div[1]/div[2]/ul/li/div[2]/a/text()').getall()xpath 方法是 Selector 对象中的一个方法,用于指定 XPath 表达式,它可以用于选择 HTML 元素。在这个例子中,我们使用 xpath 方法来选择 /html/body/div[4]/div[1]/div[2]/ul/li/div[2]/a/text() 表达式指定的所有 <a> 元素,并将它们的文本内容作为列表返回。
我们这里会得到一个所有新闻的标题列表,我们for遍历一下。我们看看效果。

✨CSS方法
我们刚刚用了XPATH的方法获取新闻的标题,我们接下来,我们使用CSS的方法来获取标题。
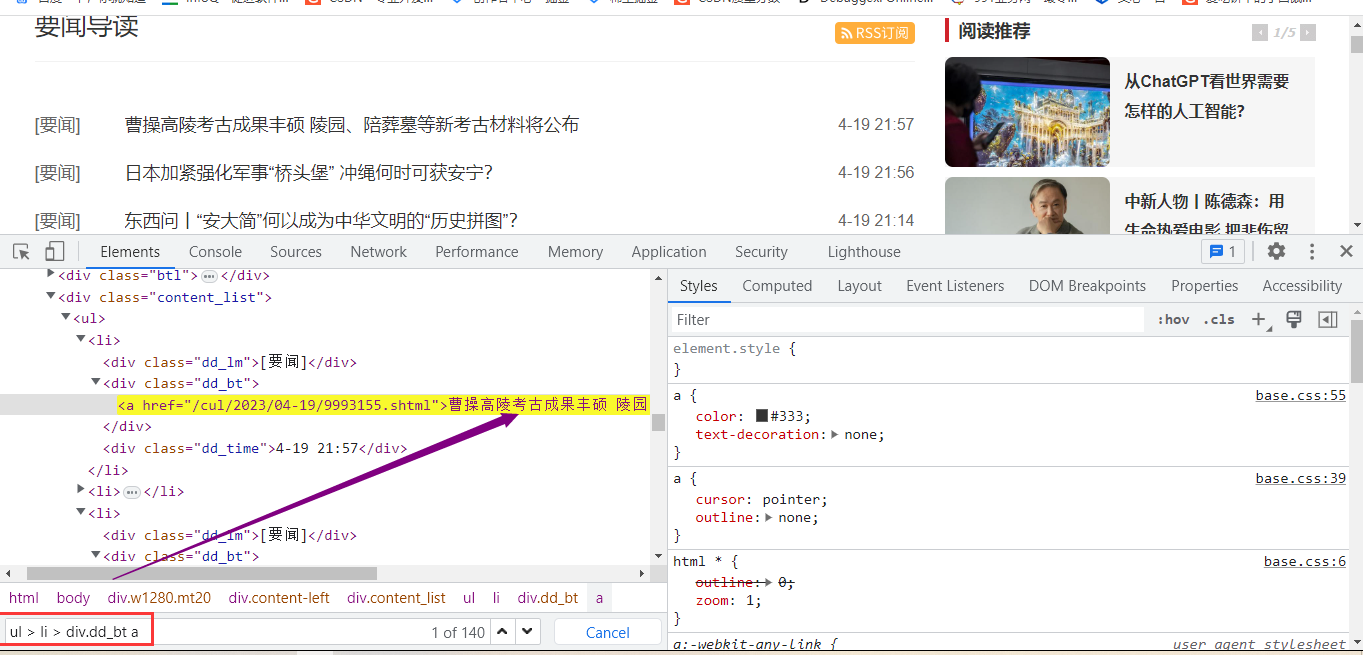
我们这里,直接写代码了。
titles = selector.css('ul > li > div.dd_bt a::text').getall()css 方法是 Selector 对象中的一个方法,用于指定 CSS 属性,它可以用于选择 HTML 元素。在这个例子中,我们使用 css 方法来选择 ul > li > div.dd_bt a 表达式指定的所有 <a> 元素的文本,并将它们的样式作为列表返回。
我们CSS语法还可以这样写。
titles = selector.css('.dd_bt a::text').getall()css 方法是 Selector 对象中的一个方法,用于指定 CSS 属性,它可以用于选择 HTML 元素。在这个例子中,我们使用 css 方法来选择 .dd_bt a::text 表达式指定的所有 <a> 元素,并将它们的文本内容作为列表返回。
我们会发现是一样的效果,不管怎么样,大家都要会一种方法。
🌟总结
在parsel实战中,我完成了一个使用 parsel 库的选择器来选择 特定元素的内容。在这个实战中,我使用了 xpath 和 css 方法来指定选择的元素的位置和样式,使用 Selector 对象来指定选择的元素,并使用 getall 方法来获取选择的所有元素。
首先,我们需要更好地理解 xpath 和 css 方法的使用,以便更准确地选择元素。其次,我们需要更好地理解 Selector 对象的使用,以便更准确地指定选择的元素。
