【论文阅读笔记|CASE 2022】EventGraph: Event Extraction as Semantic Graph Parsing

论文题目:EventGraph: Event Extraction as Semantic Graph Parsing
论文来源:CASE2022
论文链接:https://aclanthology.org/2022.case-1.2.pdf
代码链接:GitHub - huiling-y/EventGraph
0 摘要
事件抽取涉及到事件类型检测、提取事件触发词和相应的事件论元。现有的系统通常将事件抽取分解为多个子任务,而不考虑它们可能的交互。在本文中,我们提出了一个用于事件抽取的联合框架,它将事件编码为图。我们将事件触发词和论元表示为语义图中的节点。因此,事件抽取成为了一个图解析问题,它提供了以下优点: 1)联合执行事件检测和论元抽取;2)从一段文本中检测和提取多个事件;3)捕获事件论元和触发词之间的复杂交互。在ACE2005上的实验结果表明,我们的模型与最先进的系统具有竞争力,并大大改进了论元抽取的结果。此外,我们从ACE2005中创建了两个新的数据集,其中我们保留了事件论元的整个文本跨度,而不仅仅是开始词。
1 引言
事件抽取的目的是根据预定义的事件本体,将非结构化文本中与事件相关的信息抽取为结构化形式(即触发词和论元)。在这些类型的本体中,事件的特征是事件触发词,并包含一组预定义的论元类型。图1显示了一个包含两个事件的句子示例,一个是由“friendly-fire”触发的Attack事件,另一个是由“died”触发的Die事件;这两个事件共享相同的论元,但每个事件在特定事件中扮演不同的角色。例如,“U.S.”是Die事件中的Agent,但在Attack事件中扮演Attacker的角色。
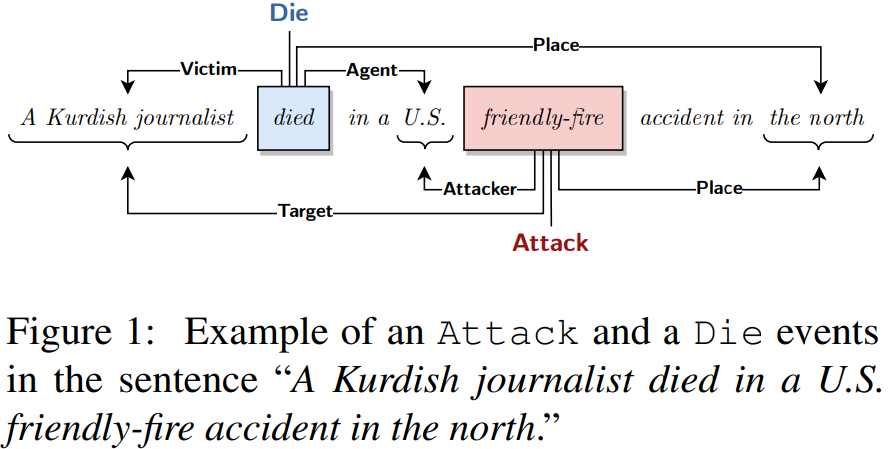
与将事件抽取划分为独立的子任务不同,我们利用了语义依赖解析方面的最新进展,并开发了一个端到端事件图解析器,称为事件图。我们采用直观的图编码来表示单个事件图中一段文本的事件提及情况,并直接从原始文本中生成这些事件图。我们在ACE2005(LDC2006T06)上评估了我们的事件图系统。我们的模型与现有模型的对比结果显示,我们的模型提高了事件论元抽取的性能。这项工作的主要贡献是:
- 我们提出了事件图,一个文本到事件的框架,它解决了事件抽取作为语义图的解析。该模型不依赖于任何特定语言的特性或特定的本体,因此可以很容易地应用于新的语言和新的数据集。
- 我们设计了一种直观的图编码方法来表示单个事件图中的事件结构。
- 我们的方法的多功能性允许毫不费力地解码完全触发词和论元提到。我们从ACE2005中创建了两个新颖的、更具挑战性的数据集,并提供了相应的基准测试结果。
2 相关工作
我们的工作与事件抽取和语义解析这两个研究方向密切相关。
监督事件抽取是自然语言处理中已成熟的研究领域。获取事件的结构化信息有不同的方法,主流方法可以分为: 1)基于分类的方法:将事件抽取视为几个分类子任务,或者以基于pipline的方式分别求解,或共同推断多个子任务;2)基于生成的方法:将事件抽取定义为一个序列生成问题;3)提示调优方法:受自然语言理解任务的启发,这些方法利用了“离散提示”
Meaning Representation Parsing近年来引起了人们极大的兴趣。与语法依赖表示不同,这些语义表示关键不是树,而是一般的图,其特征是可能有多个入口点(roots),而不一定是连接的,因为不是每个token都是图中的一个节点。在开发能够生成这种语义图的基于转换和基于图的dependency parsers的变体方面,已经进一步取得了相当大的进展。
在当前的上下文中,最近一个高度相关的发展是将semantic parsers应用于NLP任务,而不是语义表示分析。这些方法依赖于将特定于任务的表示重新表述为语义依赖图。例如,Yu等人(2020)利用Dozat和Manning(2018)的分析器来预测命名实体的span,而Kurtz等人(2020)将否定解析任务作为一个图解析任务。最近,Barnes等人(2021)提出了一种依赖解析方法,从文本中提取意见元组,称为结构化情绪分析,最近一项致力于该任务的共享任务证明了图分析方法对EE的有效性。与我们的工作最相似的是Samuel等人(2022)的工作,该工作采用PERIN解析器直接从原始文本解析为情感图。
3 事件图表示
我们采用了一种有效的“标记边”表示方法来进行句子范围内的事件图编码。事件图中的每个节点对应一个事件触发词或一个论元,它锚定到句子中一个唯一的文本跨度,除了顶部节点,它只是每个事件图的一个虚拟节点。边仅约束在顶部节点和事件触发词之间,或在事件触发词和论元之间,相应的边标签作为事件类型或论元角色。“标记边”编码能够表示:1)多个事件提及;2)嵌套结构(论元或触发词论元之间的重叠);3)单个论元的多个论元角色。以图2中的事件图为例,句子包含两个事件提及,它们共享相同的论元“the hills above Chamchamal”,但作为不同的角色,论证“coalition”嵌套在“coalition fighter jets”中。
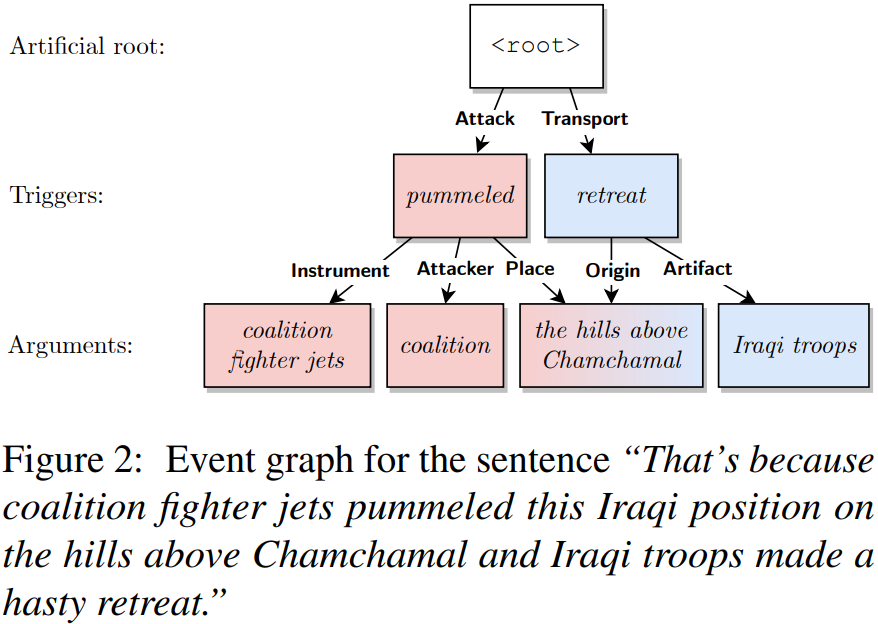
4 事件分析
事件图是对PERIN的改编,PERIN是一种用于文本到图解析的一般排列不变框架。给定事件图的“标记边”编码,我们通过自定义PERIN的模块来创建事件图,如图所示,其中包含三个分类器,分别生成节点、锚点和边。每个输入序列由四个事件模块处理,生成最终的结构化表示。
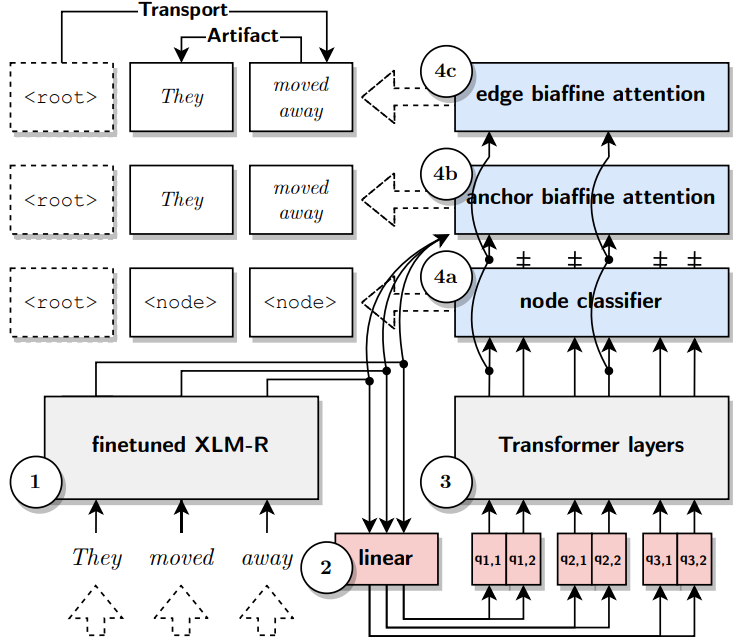
编码器
我们使用大版本的XLM-R-large作为编码器来获得输入序列的上下文表示;每个token通过在子词上学习到的子词注意层获得上下文嵌入。
查询生成器
我们使用一个线性转换层来将每个嵌入的token映射到n个query上。
解码器
解码器是一堆Transformer编码器层,没有位置编码,这是排列不变的(非自回归);解码器通过建模查query之间的相互依赖关系来处理和增强每个token的查询。
解析器头
它由三个分类器组成: a) 节点分类器是一个线性分类器,通过对每个token的增强查询进行分类来预测节点的存在;因为为每个token生成多个查询,单个token可以产生多个节点;b) 锚biaffine分类器使用增强查询和上下文嵌入之间的深度biaffine注意力,将预测节点映射到表面token;c) 边缘双仿射分类器使用两个深度biaffine注意力模块来处理生成的节点,并预测一对节点与边缘标签之间的边缘存在。
给定一段文本,EventGraph生成相应的图,从节点和边中提取事件提及的结构化信息并不费力。
5 实验设置
5.1数据集
我们在广泛使用的基准数据集ACE2005上评估了我们的系统。ACE2005数据集包含599个英文文档,其中注释了多个任务、实体、值、关系和事件,包括一个包含33种事件类型的事件本体和35个论元角色。事件论元同时来自于实体和值。一个实体的注释还包括其标题字;例如,从表1中可以,实体“the Iraqi government’s key center of power”以“center”作为标题字。根据之前的工作,我们对数据集进行预处理,并获得以下配置:
- ACE05-E: Wadden等人(2019)保留22个事件论元角色(不包括“时间”和“值”事件论元),忽略具有多个token的触发词(s)的事件,并且只使用事件论元的标题字(s)。
- ACE05-E+:与Wadden等人(2019)类似,Lin等人(2020)只使用22个事件论元角色,只保留事件论元的标题字(s),但保留具有多个token的触发词(s)的事件。
- ACE05-E++:我们创建了一个新的数据集,它保留了事件触发词和事件论元的全文跨度,但同时也保留了22个论元角色,以便与以前的工作进行比较。
- ACE05-E+++:我们创建了另一个数据集,它保留了ACE2005中的所有35个论元角色,并具有事件触发词和论元的全文span。
表1显示了在ACE05-E+和ACE05-E++中如何提取一个事件提及,而在ACE05-E中不存在相同的事件。尽管保留论元的全文跨度会使论元抽取的任务更加困难,但我们认为所提取的事件信息更丰富、更独立。

5.2 评价指标
我们报告了以下每个评估标准的精度P、召回R和F1分数
- 触发词分类(Trg-C):如果一个事件触发词的偏移量和事件类型与gold触发词相匹配,则可以正确预测该事件触发词。
- 论元分类(Arg-C):如果一个事件论元的偏移量、论元角色和事件类型与gold论元相匹配,则可以正确地预测该事件参数。
对于论元分类,为了更好地了解我们的模型在多token论元上的表现,我们加入了另一个基于token级span重叠的指标来识别论元,而不是完美匹配。
- token级span重叠:如果一个事件论元的偏移量与gold论元有80%的重叠(token级),并且正确预测它的论元角色和事件类型与gold论元匹配。
5.3 baselines
我们将事件图与以下事件抽取系统进行比较:
- DYGIE++(Wadden等人,2019):基于span的框架,捕获局部和全局上下文
- ONEIE(Lin等人,2020):用于一般信息抽取的端到端框架
- TEXT2EVENT(Lu等人,2021):基于生成的序列到事件生成模型
- GTEE-DYNPREF(Liu等人,2022):基于模板的文本到事件生成方法。
5.4 实施细节
我们的代码是建立在PERIN解析器的官方实现。对于每个数据集,我们用5个不同的随机种子训练5个模型,并报告相应结果的均值和标准偏差。
6 结果与分析
在表4中,我们将我们在ACE05-E和ACE05-E+上的结果与之前的系统进行了比较。在两个数据集上,EventGraph在Arg-C上均获得SOTA结果,比ACE-E提高7个百分点,F1分比ACE05-E+提高超过10个百分点。对于Trg-C,尽管没有击败SOTA系统,但我们的结果仍然非常有竞争力。
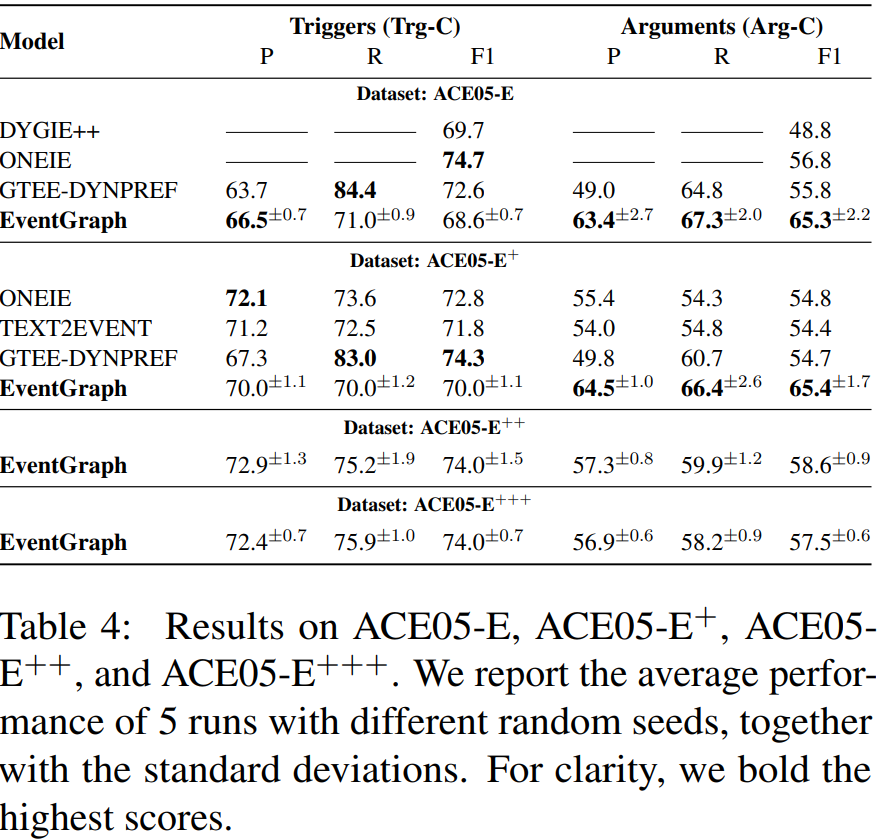
在我们创建的两个新数据集上,EventGraph取得了很好的结果(表4)。在ACE-E++上,尽管有更长和更复杂的论元,事件图在ACE-E+上产生了与GTEE-DYNPREF(当前SOTA)相似的结果。在ACEE +++上,即使论元角色集从22个扩展到35个论元角色,但在Arg-C上的事件图的结果仍然保持稳定。
结果表明,EventGraph在事件触发词和论元的联合建模方面表现良好,并受益于事件触发词和论元的文本跨度更长。当使用全文的论元,模型接收更多的训练信号,所以它有更多的信息区分句子包含事件的没有,如表6所示,从而识别事件触发词,也显示了增加Trg-C分数从ACE-E和ACE-E+ACE-E++和ACE-E+++。例如,如表1中的例子所示,“the Iraqi government’s key center of power”并不仅仅是“center”更模糊。如表3所示,ACE-E++和ACE-E+++的平均论元长度要长得多,但四个数据集的平均触发词长度非常相似;很明显,单token论元占所有论元的很大比例,即使是ACE-E++和EACE-E+++,因此论元长度分布有一个长尾。对于较长的论元,更难获得与gold论元的完美匹配,因此我们观察到,当事件图在ACE-E++和ACE-E+++上进行评估时,Arg-C分数下降。

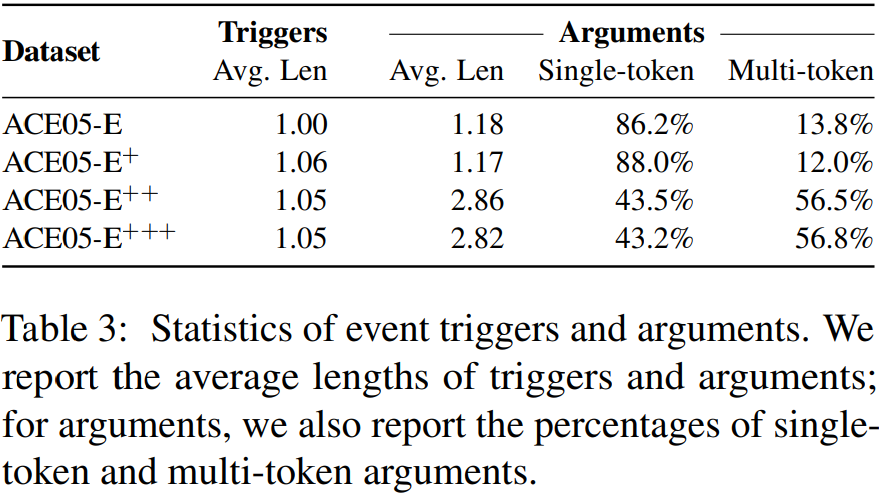
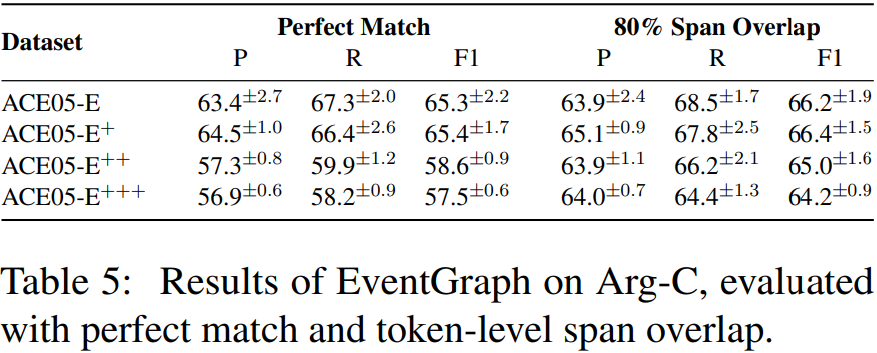
为了进一步研究我们的模型在识别多token事件论元方面的性能,特别是那些包含超过5个token的事件论元,我们进一步报告了基于token级span重叠的Arg-C分数。如表5所示,当我们将论元识别从完美匹配放松到80%的token级跨度重叠时,Arg-C的分数持续增加,特别是ACE-E++和ACE-E+++的分数,现在可以与ACE-E和ACE-E+的结果相比较。
7 结论
本文提出了一种新的事件抽取作为语义图解析的方法。我们提出的事件图在ACE2005的事件触发词分类任务上取得了有竞争的结果,并为论证角色分类任务获得了新的最新的结果。我们还提供了一个图形表示,以更好地可视化事件提及,并提供了一个有效的工具来促进图形转换。我们从ACE2005中创建了两个新的数据集,其中包括触发词和论元的全文span,并提供了相应的基准测试结果。我们表明,尽管添加了更多和更长的文本序列,证据图的性能优于以前在更有限的数据集上测试的模型。在未来的工作中,我们希望实验不同的预训练语言模型,并进行更详细的误差分析。