MongoDB实现---事务机制

事务机制
原子性是MongoDB实现事务的难点,隔离性和持久性则是MongoDB事务机制的亮点
- ACID支持:由于前面说过MongoDB是基于大数据、提供高度可扩展和高可用;所以其事务机制不仅仅是一般ACID还是结合了BASE理论下的ACID
- 原子性:保证单文档单命令的原子性,在4.0 版本之后,MongoDB 开始支持多文档的事务,针对多文档的事务操作,MongoDB 提供 “All or nothing” 的原子语义保证。
- 一致性:
- 在分布式BASE理论下,一致性支持是最终一致性,所以就会影响到读数据的隔离性
- 隔离性:
- MongoDB通过四个隔离级别的读策略和读依赖以及MVCC实现分层次的隔离性;
- 持久性:
- MongoDB通过确认机制维持持久性(就是写关注)和高性能的权衡,MongoDB支持类似MySQL不丢失的持久性、也支持大概率不丢失或者不考虑丢失的持久性;
原子性
原子性实现
-
参考MySQL,单机原子性毫无疑问依赖于锁机制、回滚日志
- MongoDB没有回滚日志,但是其实有内存实现了回滚日志功能的、记录update和 insert的链表
- MongoDB同样使用多粒度封锁协议,最小的粒度是文档(相当于行锁)
-
单文档事务原子性:
- 单文档事务实现是通过文档加锁+index、oplog、文档数据写入原子性实现的;
- 单文档事务原子性是MongoDB存储引擎层实现的(这一点类似redis实现事务原子性);
- 单文档事务原子性本质只支持单命令原子性;
-
分布式事务(多文档事务)原子性:多文档事务原子性则将事务的控制交给了应用层,涉及到很多问题
- MongoDB默认就是有分布式支持(数据分片),所以需要支持分布式事务
- 事务副本集需要oplog同步,而多文档事务使用的oplog资源不能占据超过限制(否则副本集将没法增量更新)
- oplog的全局顺序性和WT实现的事务id没有关联:则导致MongoDB集群看到的事务提交顺序与 WiredTiger 看到的事务提交顺序不一致。
- 多文档事务占据的资源(特别是锁),将可能严重影响性能(由于事务周期长导致长期占用不释放)
多文档原子性
Session和全局时序
Session
- 为了实现多文档事务,MongoDB首先提出了session的概念;Session即事务的上下文
- Session保证了会话中事务id递增、事务内操作id递增即保存操作id;
- Session保证因果一致性、会话一致性;
- Session记录了读写关注;
- Session记录了读依赖;
全局时序
- MongoDB通过事务时间戳(transaction timestamp)机制实现全局时序;Server的oplog和WT引擎通过全局时序保证双方事务一致(事务提交和事务回滚);
实现
- Read as of a timestamp:换句话说就是内存的undo log,即保证:
- 事务未提交时本事务可见、其他事务根据隔离级别可见;
- 未提交时,本事务的数据不影响其他事务数据;
- 由于是内存的undo log,所以如果保留的版本太多,也会对 WT cache 产生很大的压力。所以MongoDB允许自动更新 oldest timestamp,以删除不必要的版本;
- 回滚:考虑到副本集,在MongoDB的回滚机制中,副本集不是通过server层操作oplog进行回滚,而是通过存储引擎进行回滚;(或许这也是不需要undo log的原因之一)
- 本机不仅仅是回滚本事务,而是直接回滚到一个检查点;
- 副本集同样回滚到该检查点,这样所有数据就快速回滚到一致性状态;
- 这个检查点依赖于
stable timestamp。WiredTiger 会确保stable timestamp之后的数据不会写到 Checkpoint里,MongoDB 根据复制集的同步状态,当数据已经同步到大多数节点时(Majority commited),会更新stable timestamp,因为这些数据已经提交到大多数节点了,一定不会发生 ROLLBACK,这个时间戳之前的数据就都可以写到 Checkpoint 里了。这要求必须尽快提交stable timestamp以避免oplog过大,内存保存大量版本数据;
持久性
写关注点
-
写关注点包括:写确认机制(ACK机制:从节点确认、落盘确认)、超时等待
-
{writeConcern : { w: <value>, j: <boolean>, wtimeout: <number> }} # w:已传播到指定数量的mongod实例或具有指定标记的mongod实例 # j:设为1表示确认写入操作的请求已经写入磁盘日志(on-disk journal),也就是下一次Journal log提交。 # wtimeout选项:指定时间限制,以防止写操作无限期阻塞。
-
-
4.4后副本集和分片集群支持设置全局默认的write concern。没有显示指定写关注的操作将继承全局默认的设置;
-
允许多粒度的写关注点
-
实现过程
- 写请求首先到达主节点
- 主节点向从节点同步数据
- 从节点根据落盘确认机制确定发回ACK的时机
- 主节点:
- 超时发回失败,进行回滚
- 收到足够数量的ACK发回成功
隔离性
读关注点
读关注定义了四个隔离级别的读策略
- local/available: 语义基本一致,都是读操作直接读取本地最新的数据,但不保证该数据已被写入大多数复制集成员。
- available:无法用于因果关系是一致的会话和事务。
- local:可用于具有或不具有因果一致的会话和事务。
- majority:读取 majority committed 的数据,可以保证读取的数据不会被回滚,但是并不能保证读到本地最新的数据。受限于不同节点的复制进度,可能会读取到更旧的值。
- 副本集必须使用WiredTiger存储引擎
- 多文档事务中的操作,仅当事务以写策略“majority”提交时,读策略"majority"才能得以保证 。否则,读策略"majority"不能保证事务中读取的数据。
- linearizable:读取 majority committed 的数据,但会等待在读之前所有的 majority committed 确认。它承诺线性一致性,要求读写顺序和操作真实发生的时间完全一致,既保证能读取到最新的数据,也保证读到数据不会被回滚。
- 仅为主节点上的读操作指定读策略"linearizable”。
- 无法用于因果关系是一致的会话和事务。
- 只对读取单个文档时有效;
- snapshot:所有的读都将使用同一个快照,直到事务提交为止该快照才被释放,可以避免脏读、不可重复读和幻读;
- 仅可用于多文档事务。
- 分片群集上的事务,如果事务中的任何操作涉及已禁用读策略“majority”的分片,则不能对事务使用读策略"snapshot"。
https://blog.csdn.net/zxwjx/article/details/106069585
读依赖readPreference(读策略)
使用
-
多文档事务: “snapshot”,"local"和 “majority”
-
单文档事务:除了snapshot;
-
db.collection.find().readConcern(<level>)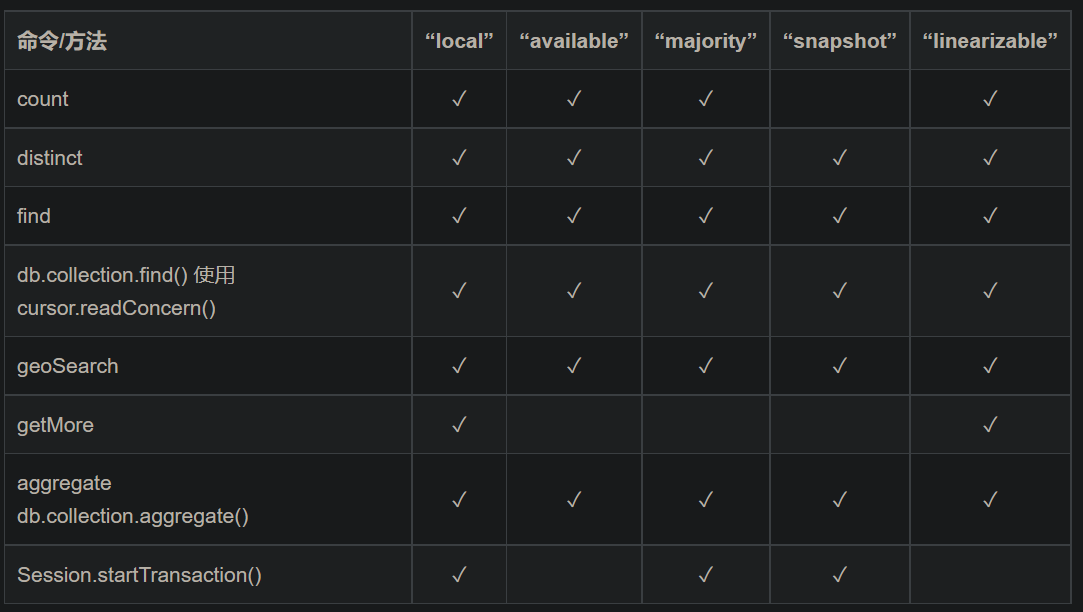
一致性
- journal log