分布式数据一致性解决方案推理过程

- redis是一个极轻量级的进程,单机单线程单进程。
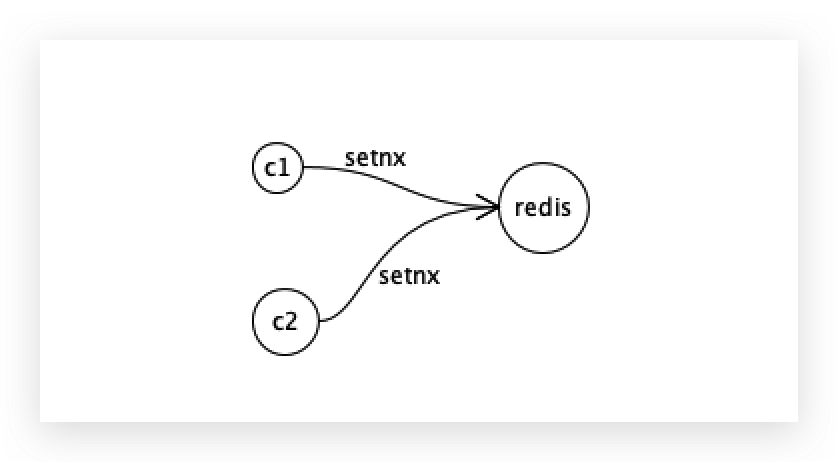
使用redis很容易实现分布式锁:setnx,同一个key,谁设置成功了,谁就抢到了锁,所以就产生了多锁问题。
假设客户端1抢到了锁,redis挂了,redis重启了之后,客户端2又抢到了锁。
redis持久化能否解决多锁问题?
持久化有RDB和AOF。
RDB是窗口机制的,会丢失将近一个窗口的数据,比如丢失半小时的数据。
AOF有三个缓存级别:每操作成功就记日志、一秒记一次、内核的缓冲区满了才记。
redis要开启AOF最高的缓存级别来保证锁的一致性。
用户发了一个setnx请求,立刻持久化到AOF里面,这样才能保证重启之后,锁被带到内存,另外一个客户端抢不到该锁,因为它没有被释放。
当开启redis持久化方案的时候,性能会下降,redis本来就是基于内存的,它的特征就是快,开启AOF必然降低性能。
如果不想开启AOF,开启哨兵模式:主从复制,加一个哨兵,把锁同步到另外一个节点。
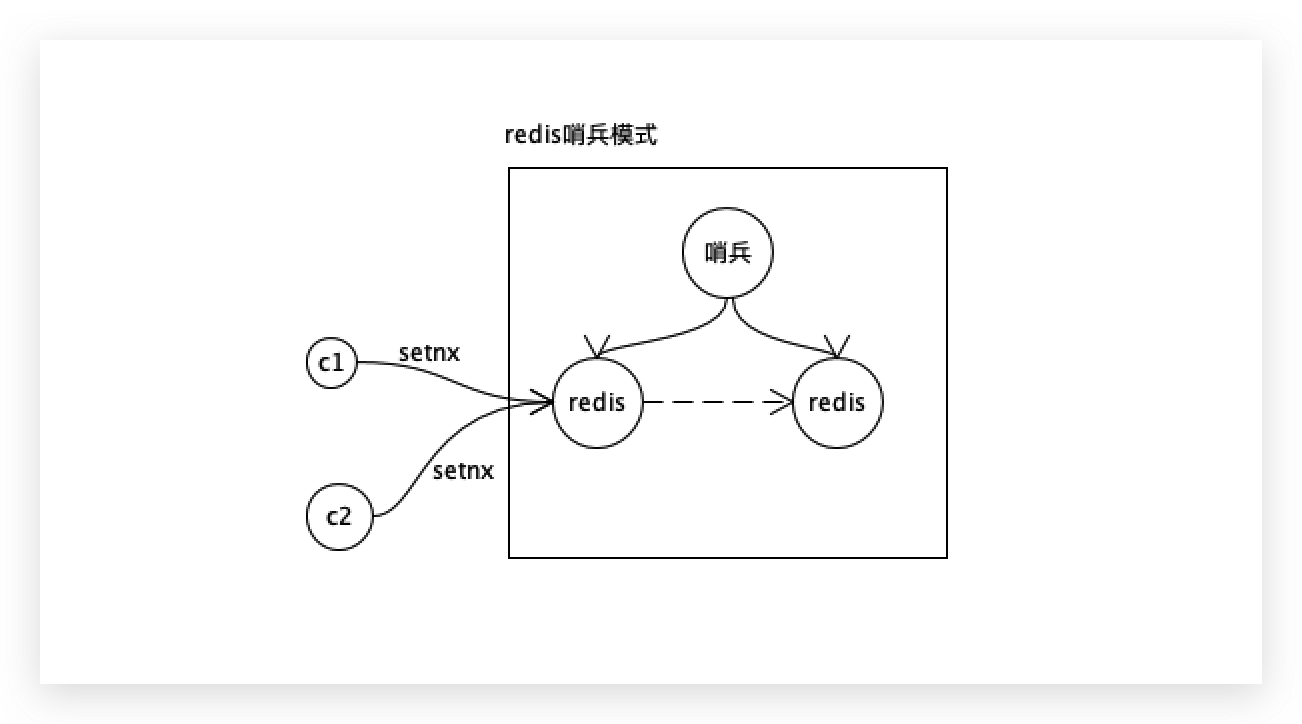
一个redis挂了之后,由哨兵快速的把另外一个redis切换成主。
redis数据同步
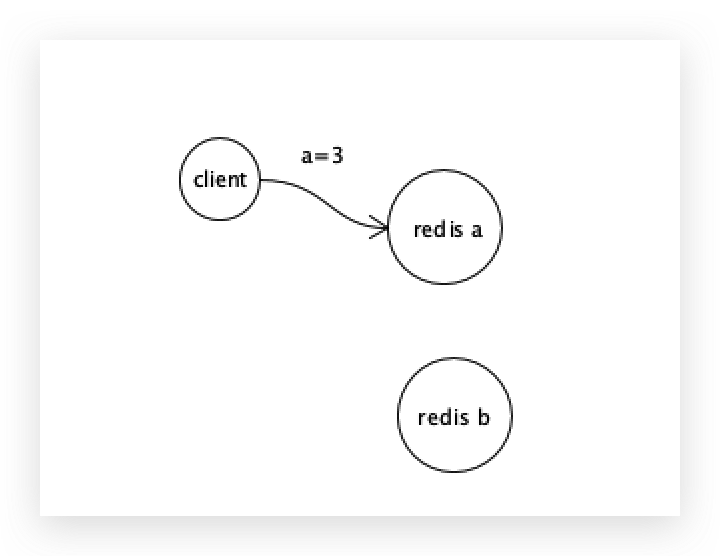
一个a程序、一个b程序、一个客户端,
客户端将a=3写入a程序,为了保证a和b 2个redis数据的一致性,会有2种同步方式:
第一种:
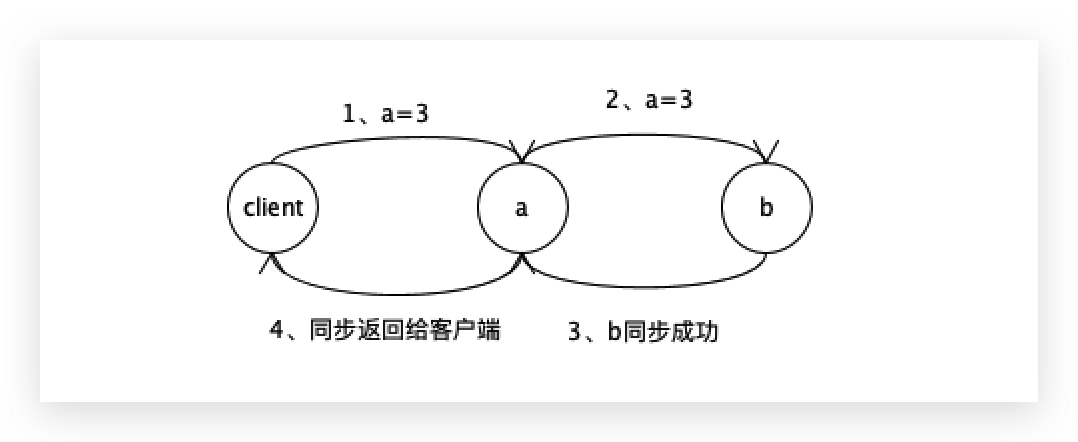
客户端将a=3写入a程序,写成功了,但不返回成功,还在这里阻塞着,a同步给b,把a=3写给b, b返回成功之后,a再给客户端返回成功。
如果a挂了,还可以从b取到a=3,这是强一致性的。
有了redis a,为什么还要有redis b?
为了解决可用性问题,本来不加b,a可以一直存活,加了b,b挂了,a没挂,给a写,还必须要同步给b,b还不在,只能阻塞等b恢复,即强一致性行为间接会破坏可用性。如果再有一个redis c,则出现问题的几率更高。
redis主从复制的确可以设置为强一致性,可以配置主收到几个从节点返回的ok,才允许客户端返回。
还有另外一种一致性行为,非同步阻塞,
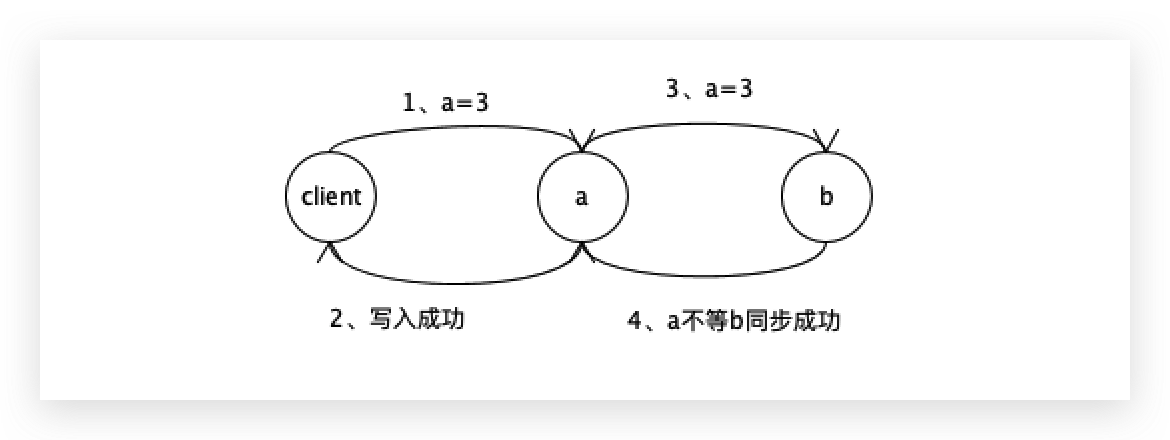
只要给a写入成功,就可以给客户端返回成功,
这时候a需要把数据发给b或发给c,但是a不等b或c返回ok,
若a刚给客户端返回ok,a挂了,但b和c还没有处理,此时随便选择一个当主,客户端就获取不到a=3了,这叫弱一致性,弱一致性不能保证数据的一致性。
a挂掉了,把a=3带走了,a把a=3给b和c的时候,这是一个不可靠的给法,因为它不知道对方有没有收到a=3或a=3有没有处理成功等一些列的未知情况。
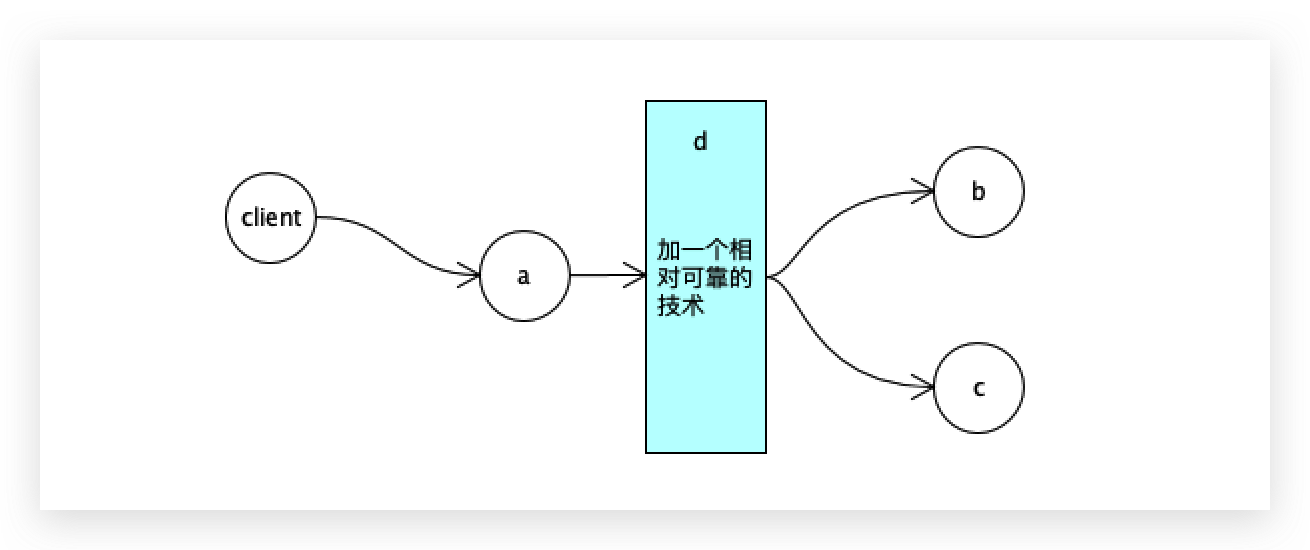
假设在a和b、c中间加一个可靠的技术d,d和a、b、c之间不会出现网络断开的情况。
a把a=3给到了d,a挂了,d还没有给到b和c,d中有a=3,未来只需要b能够连接到d这个区域,把a=3取回来,最终b和c可以还原到a挂机的状态。
数据同步可能会有延迟,但可以达到最终一致性。
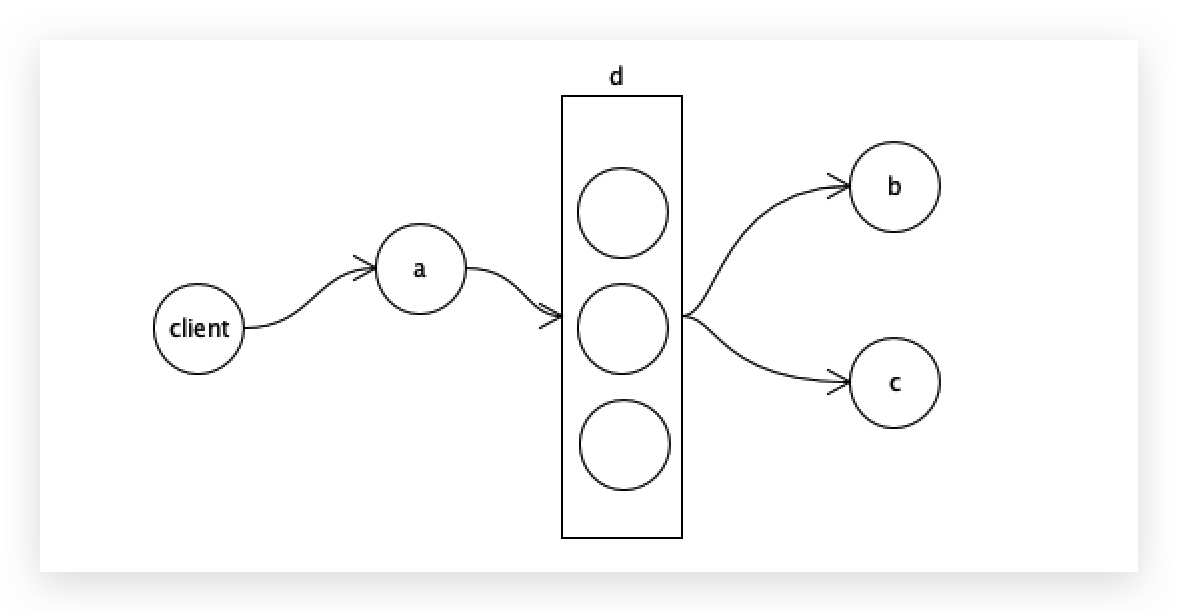
d区域一般不是一台服务器,推荐3、5、7..台。
客户端把a=3写入中间集群中的每一个节点,如果3个都返回ok,才返回给客户端,这是强一致性,但又破坏了可用性。
有一部分返回ok就可以的话就规避了挂机的风险。
那一部分是多少个呢?
如果把a=3请求其中一台,再请求另外两台的时候,就请求不到a=3了或者另外一个客户端从别的节点上取不到a=3。
如果1个节点的话,那更多的节点是取回数据不一致性的情况,但只要有一个节点活着,就可以对外提供服务。
如果是2个节点返回ok呢?
a给这个集群写a=3,返回2个ok。
同时不要只关注a,还要关注中间的这个集群,集群里面必须要两两通信。
只要两个节点能够互相通信,势力范围才能满足2,只要有一个节点不能和别人通信了,势力范围就是1了,不能满足2,这台就会shutdown自己,不会对外提供读写服务。
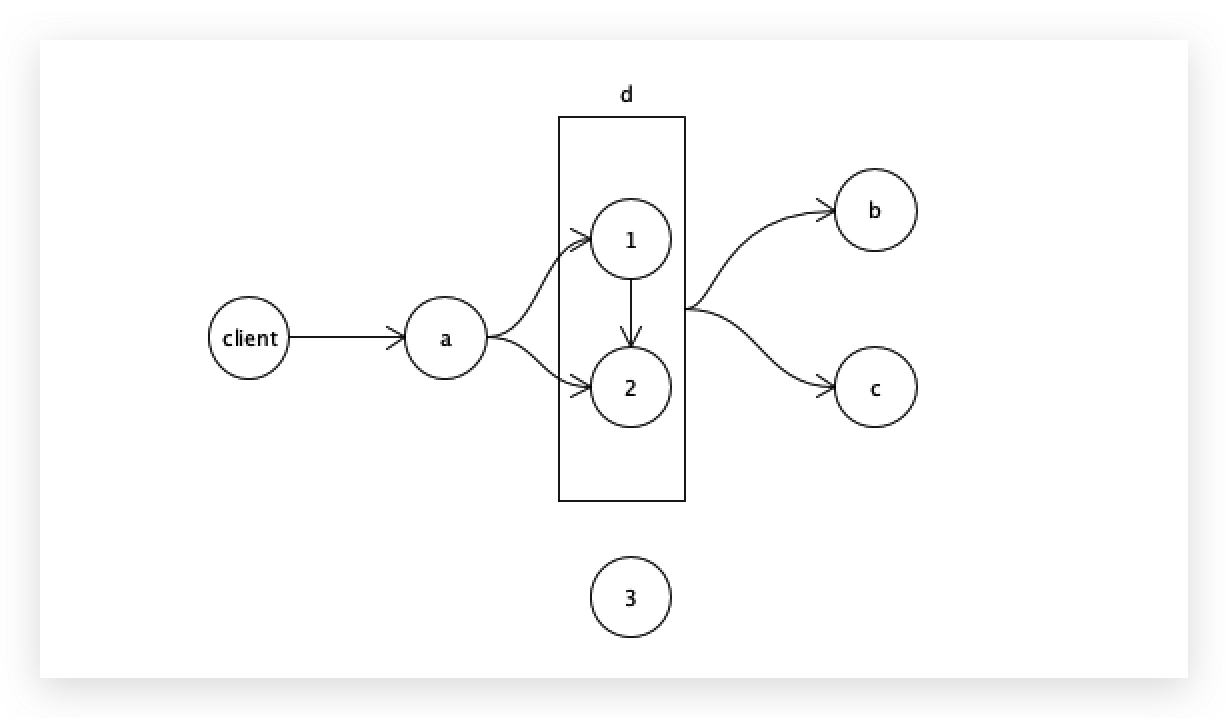
客户端从集群中节点3取数据的时候,因为它已经shutdown了(此时进程还活着,只是跟别的节点连不上 ,必须要找到另外一个小伙伴,2个节点的时候,才能对外提供服务), b和c只能从另外两台(节点1、2)取,这两台曾经又登记过a=3,所以对方一定能够取到正确的数据,这样就可以保证数据最终一致性了。
节点3也会从另外2个节点同步数据,最终整个集群也是数据一致的。
如果集群中有5个节点,
1,2组成一个小集群A,4,5组成一个小集群B,3谁也不理谁,2个小集群A,B都可以对外提供服务,这样出现了脑裂情况。
所以如果5个节点,3个组成一个小集群才能对外提供服务的话,上面的2个小集群均不能对外提供服务,即redis b和c从小集群A和B上是获取不到a=3的,因为不满足3个节点,不能对外提供服务,
集群中,5个节点,同时给这3(节点1-2-3)个写入成功,这3个组成的小集群才能对外提供服务。
如果不过半,就通过,那么就会产生脑裂问题。
可不可以偶数个节点?
3台过半是2台,允许一台挂机,集群还能继续运行。
四台过半数是3,承担风险还是1个。
奇数3和偶数4承担的风险是一样的,4台还更容易挂一台,所以偶数台没有必要,风险反而更大,所以从成本和风险考虑,选择奇数台。
中间这个集群是什么?
zk是分布式协调服务,自带高可靠光环。
redis组建一个主从复制分布式集群,需要解决分布式数据同步或选主等分布式行为。
zk给别人提供服务的时候,如果它自己都不可靠的话,那别人更不可靠。
zk必须是集群多机的,所以自带了高可靠的光环,挂了一台无所谓,依然对外提供服务。
zk对外提供服务的时候,还需要考虑成本,
a和集群中的5个节点都建立连接,然后过半的节点都给它返回ok,这样增加了客户端连接和通信的成本。
将中间区域做一个整体对外提供服务
a向这个中间件发送数据,中间件返回给a有没有写入成功即可。
redis集群部署的时候,一般是主从集群,在三个里面,选出一个leader,这个leader负责增删改查和向其他从节点同步数据,只要leader活着,其他从节点有一个活着,在满足势力范围是2的条件下,就可以组成一个小集群对外提供服务。
a只要发给中间件集群中的leader节点就可以了。
zk为了完成分布式协调做了一些事情,redis却没有做这些事情。
zk在leader节点活着的时候叫主从集群,和主节点通信就可以了,主在同步给从节点,主一旦挂掉了,就会进入无主集群,只有主才能对外提供服务,此时就会立刻选主,从剩下2台中选择一个主,只要选主够快,对外影响就不大。
选的要够快,而且能够选出来,官方在集群压测的情况下,恢复leader时间是200ms,
里面也有observer观察者,即便zk集群很大,最终选主投票的节点可以限定的很少,所以恢复leader的时间是很快的,
这么快是怎么实现的?
比如班级100个人中,投票选举谁最帅,每个人都发自己最帅,这样会陷入恶性循环,第一轮投票失效,可能会投出30秒或30个小时。加一个条件,谁可以说话,谁就最帅,这样只能选择老师,只有老师才可以说话。
zk哨兵模式就是这样做的,zk配置文件中有一个myid,server.1 server.2 ... 会给每一个zk server一个数值,而且全局唯一不能重复。
主从集群有一个好处 ,主是单点的,一台很容易实现串行化。
还有一个事务id,客户端给主发了一个操作,给一个事务id加1,第二个操作再增加1,这就是zxid。
当有一个节点挂了之后,剩余存活的节点要亮出自己的2个id,优先判断谁的事务id最大,因为事务id最大代表数据最全,所以谁的事务id最大,谁立刻就是leader了。
如果两个人的事务id都一样,就亮出自己的全局唯一的id,谁最大,谁就是leader,所以选举的过程,根本不需要消耗太多的时间,这是谦让机制。
从无主投票到过半机制,其实是符合paxos协议的,zk单独实现了paxos协议,叫zab协议。
如果想使用redis做分布式锁怎么做
redis开启磁盘持久化后性能会下降,开启主从复制,强一致性数据同步容易破坏可用性,redis中间还没有加数据缓冲的过程即上面所说的中间件区域,redis本身没有实现,但zk实现了。
redis自己同步数据的时候只能实现弱一致性,可能会出现数据不一致,就会造成双锁的现象。
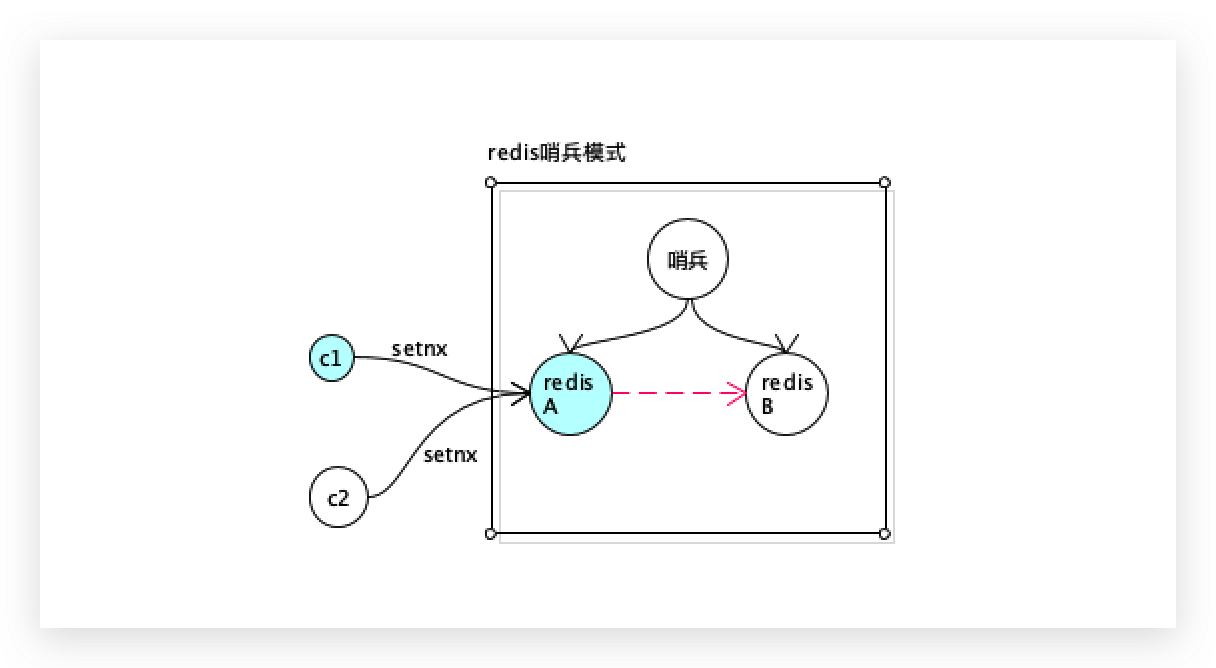
c1从redis A获取到了分布式锁,redisA还没有来得及同步给redisB,redisA就挂了。
哨兵把redisB设置成主,c2从新主抢到了锁,结果2个客户端都拿到一把锁。
使用redis做分布式锁一直就存在争议。
替代性redis分布式锁的是zk,zk做分布式协调,本身就是主从的。
redis 胖客户端
应用程序中引入redis jar包,客户端自己每次要写三个,
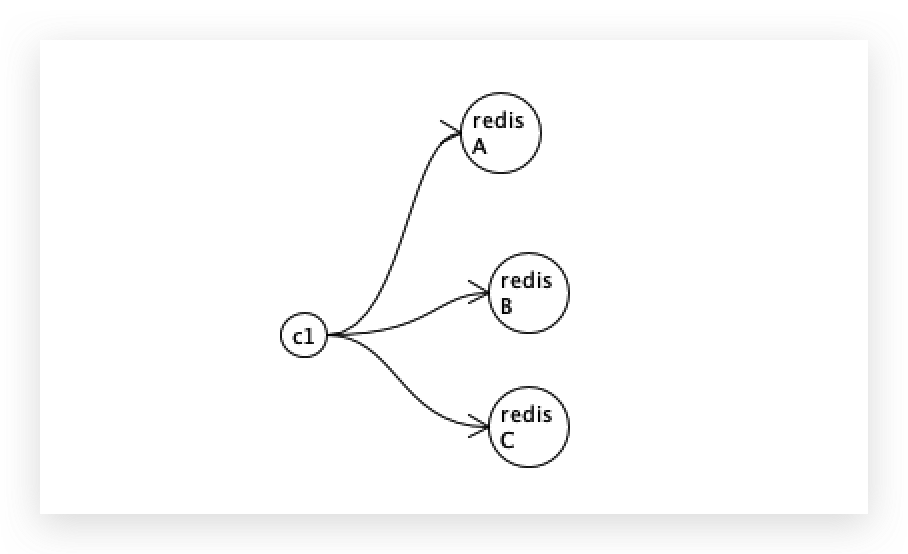
这是一个间接的伪cp,客户端尽量向所有redis去写数据,
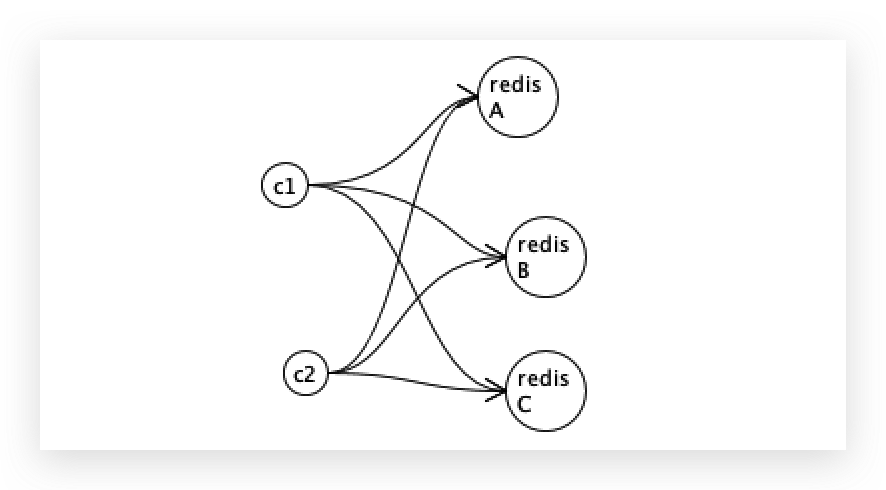
客户端1和客户端2都去抢锁,如何确定锁的唯一性?
不是redis自身实现的(类似于zk实现的),而是由客户端来代替了leader角色。
俩客户端去抢锁,要是zk的话 ,客户端给zk的leader就可以了,zk自己去同步。
redis胖客户端写数据给redis集群中的每个节点,写之后,另外一个客户端如果想判断有没有这把锁,有的话,就说明被其他客户端是使用了,尽量查询每个节点数据,客户端再判断到底有没有这把锁。
这种方式也可以承担一部分挂掉的风险,3个redis节点允许挂掉一个。
解决分布式数据一致性的话,要么是基于paxos协议,由中间件自己去设计实现,要么就是由客户端自己完成对过半机制的判定。
不推荐redis实现分布式锁,zk肯定要优于redis,还有另外一种k8s etcd速度高于zk,实现较复杂。