字符集与字符编码的区别与演进(ASCII、GBK、UNICODE)

1 常见编码
1.1 单字节编码:ASCII
ASCII使用1个字节(8个bit)来记录一组常用字符,见下表:
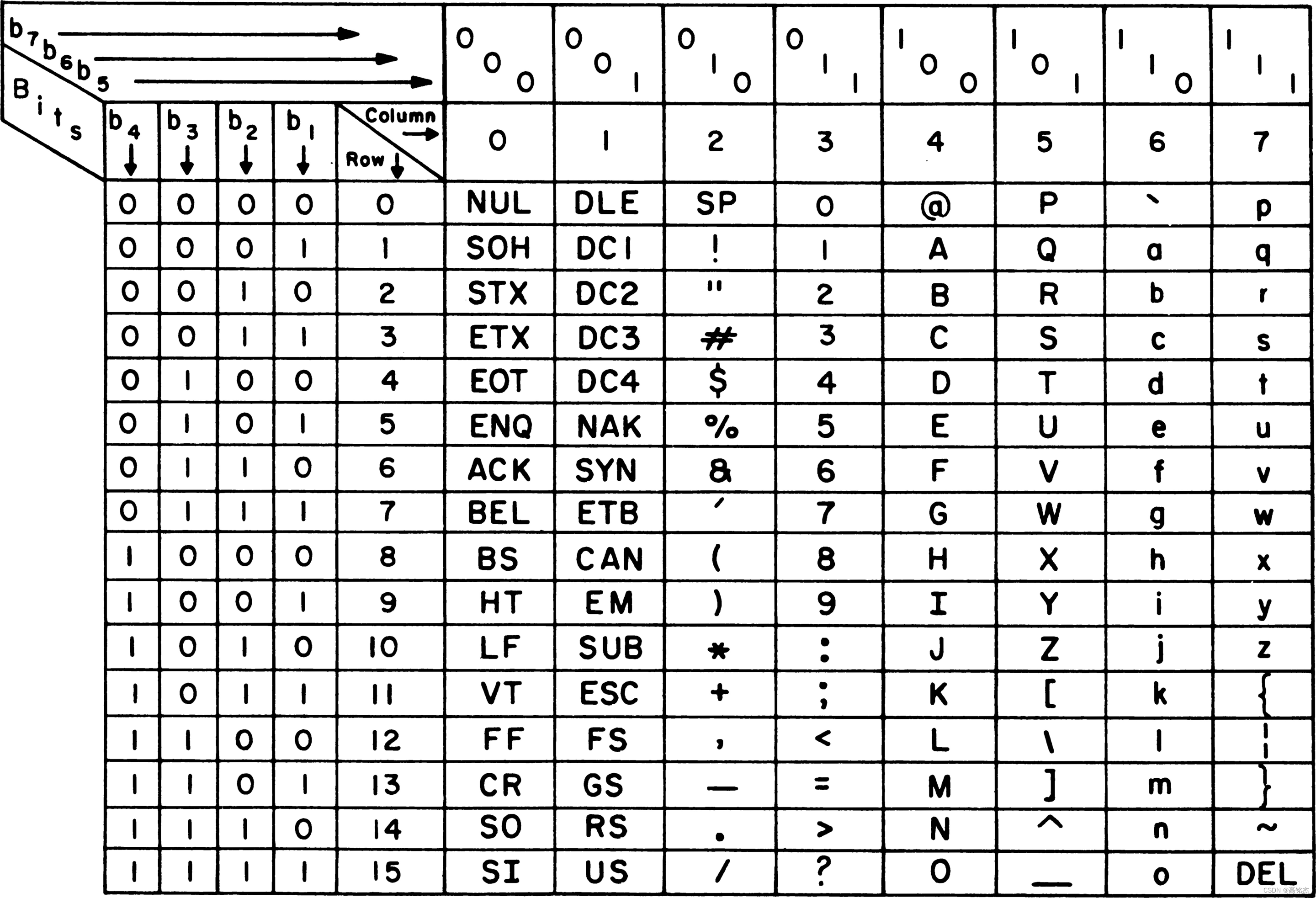
例如其中字母a的二进制位:1100 001 = 97,那么a在计算机中就可以用1100001来保存。
注意上表中其实只使用了7个二进制位,最高位b8没有使用。
所以目前ASCII只使用7个二进制位保存128个字符,还有128个位置未使用。
1.2 单字节编码:ASCII扩展OEM字符集
对于ASCII的第一次扩展:OEM(IBM PC)字符集,实际上就是使用了ASCII后面的128个位置,还是单字节字符集。
下面列举两种常用的:
ISO/IEC 8859-1:1998,又称Latin-1或“西欧语言”

ISO/IEC 8859-2:1999,又称Latin-2或“中欧语言”
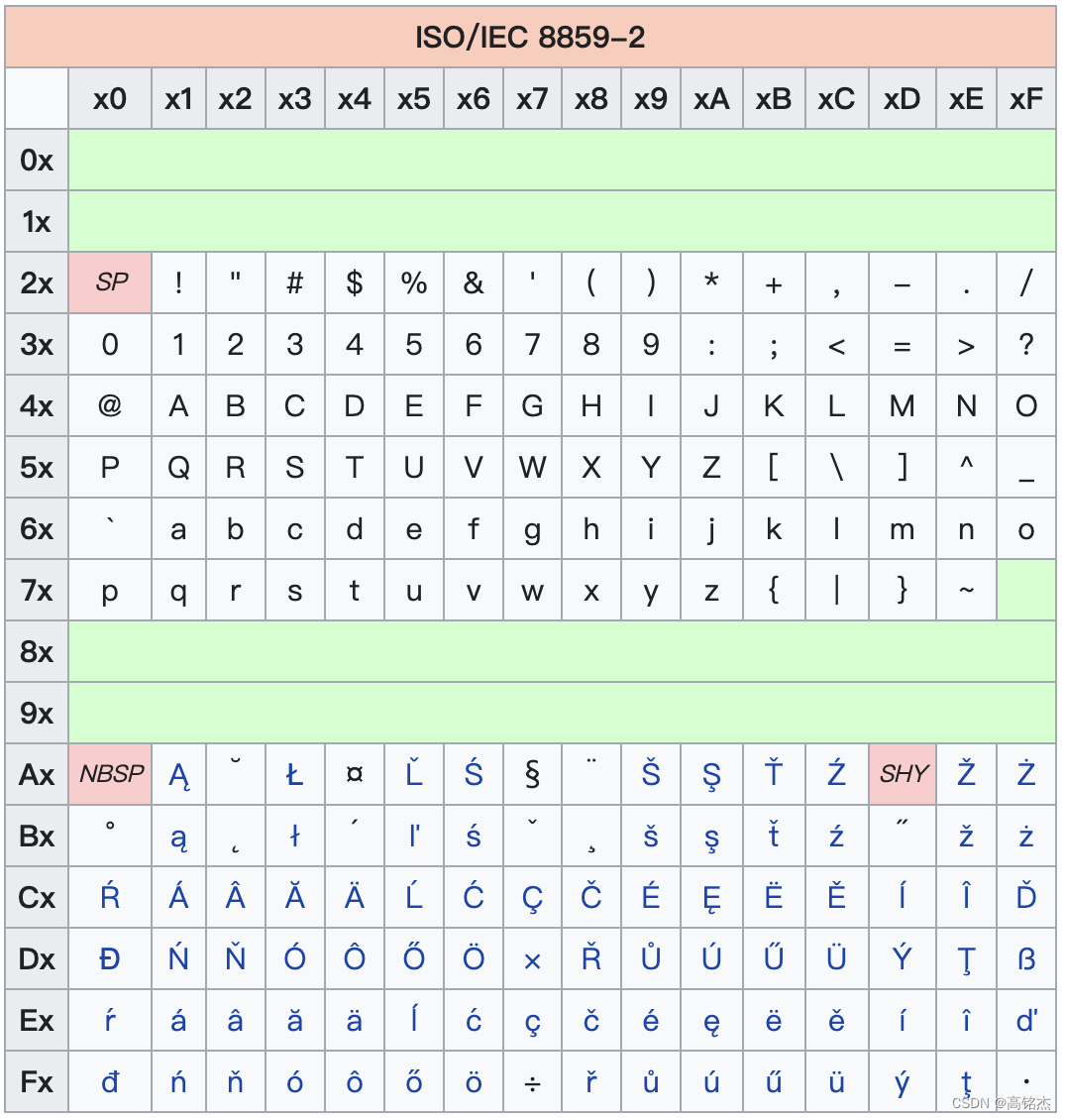
对于拉丁语国家,除了我们熟知的a-z、A-Z之外,还存在衍生拉丁字母:
Á É Í Ó Ú Ý À È Ì Ò Ù Â Ê Î Ô Û Ä Ë Ï Ö Ü Ÿ
á é í ó ú ý à è ì ò ù â ê î ô û ä ë ï ö ü ÿÇ Ş Ã Õ Ñ Ą Ę Į Ų Æ Œ Ø IJ ẞ Þ
ç ş ã õ ñ ą ę į ų æ œ ø ij ß þ
可以看到,对于拉丁语系国家,单字节可以覆盖所有字符,Latin编码足够使用了。
但是对于非拉丁语系国家,例如汉语,单字节编码的256个位置是远远不够的。
1.3 双字节编码:大五码、GB码
单字节编码在中文环境中显然是不够用的,中文区的标准编码是GB系列。
- 大五码是早期繁体中文的事实标准,基本被GB码取代。
- GB码初代没有包含繁体,到今天的国家标准GB18030已经囊括了基本所有中、少数民族、日、韩汉字。
- 演进:GB2312(2字节)→扩展繁体字→GBK(2字节)→扩展少数民族中日韩等→GB18030国家标准(4字节)。
- 注意GBK都是向下兼容的,即GB18030兼容GB2312,因为使用的编码位置没有重叠。
1.3.1 大五码
Big5码是一套双位元组字符集,使用了双八码储存方法,以两个字节来安放一个字。第一个字节称为“高位字节”,第二个字节称为“低位字节”。
“高位字节”使用了0x81-0xFE,“低位字节”使用了0x40-0x7E,及0xA1-0xFE。在Big5的分区中:
| 0x8140-0xA0FE | 保留给使用者自定义字元(造字区) |
|---|---|
| 0xA140-0xA3BF | 标点符号、希腊字母、特殊符号,包括在0xA259-0xA261,安放了九个计量用汉字:兙兛兞兝兡兣嗧瓩糎。 |
| 0xA3C0-0xA3FE | 保留。此区没有开放作造字区用。 |
| 0xA440-0xC67E | 常用汉字(5401字),字集来源除教育部“常用国字标准字体表”所列4808字外,并优先收编国中、国小教科书中常用字587字及异体字6字。先按笔画再按部首排序。 |
| 0xC6A1-0xC8FE | 保留给使用者自定义字元(造字区) |
| 0xC940-0xF9D5 | 次常用汉字(7652字),字集来源除教育部“次常用国字标准字体表”所列6330字外,并筛选编入教育部“罕用国字标准字体表”表中使用频率较高之1320字。亦是先按笔画再按部首排序。 |
| 0xF9D6-0xF9DC | 七个倚天外字集的扩充字:碁銹裏墻恒粧嫺(此七字分别为“棋鏽裡牆恆妝嫻”之异体字) |
| 0xF9DD-0xFEFE | 保留给使用者自定义字元(造字区) |
1.3.2 GBK
字符有一字节和双字节编码,00–7F范围内是第一个字节,和ASCII保持一致,此范围内严格上说有96个文字和32个控制符号。
之后的双字节中,前一字节是双字节的第一位。总体上说第一字节的范围是81–FE(也就是不含80和FF),第二字节的一部分领域在40–7E,其他领域在80–FE。
具体来说,定义的是下列字节:
| 范围 | 第1字节 | 第2字节 | 编码数 | 字数 |
|---|---|---|---|---|
| 水准GBK/1 | A1–A9 |
A1–FE |
846 | 717 |
| 水准GBK/2 | B0–F7 |
A1–FE |
6,768 | 6,763 |
| 水准GBK/3 | 81–A0 |
40–FE (7F除外) |
6,080 | 6,080 |
| 水准GBK/4 | AA–FE |
40–A0 (7F除外) |
8,160 | 8,160 |
| 水准GBK/5 | A8–A9 |
40–A0 (7F除外) |
192 | 166 |
| 用户定义 | AA–AF |
A1–FE |
564 | |
| 用户定义 | F8–FE |
A1–FE |
658 | |
| 用户定义 | A1–A7 |
40–A0 (7F除外) |
672 | |
| 合计: | 23,940 | 21,886 |
2 字符集标准
可以理解为标准是一套字符集的集合,根据本地化的规则选择使用哪个字符集。
注意这些标准互相是不兼容的。
2.1 ANSI
与字符集不同,另一个维度的概念是字符集标准:由于不同的地区定义了大量不同的字符集,就拿单字节编码的字符集来说,就有ASCII、latin等等,虽然前128个字符一样,但后128个字符就完全不同了。
标准协会选择了一些比较常用的单字节编码作为ANSI标准,ANSI不指定某一种具体的字符集,而是根据系统locale选择具体使用哪一种单字节字符集。
ANSI没有固定字符集。
2.2 ISO 8859-1
ISO 8859-1 也是一种编码标准,由欧洲开发。长度也是一个字节,前 0~127 与 ASCII 一致,剩下的128个字符大多是欧洲语言所使用的字符,所以可以认为ISO 8859-1是为欧洲语言所定制的一套编码标准。一般情况ISO 8859-1标准会使用Latin 1。
2.3 GBK
事实上我们使用的GBK、GB18030都是标准,但由于我们的标准只对应一套特定的字符集,所以可以认为GBK就是字符集。
3 大统一
字符集、标准种类繁多,但是无论使用哪一种字符集,都无法做到显示任意国家的字符,所以unicode字符集出现了。
3.1 unicode
unicode使用4字节共32个二进制位,为每个字符都确定了一个唯一的编码,由于整体搜索空间庞大,实际使用的量比较少。所以将整体分为了17组,叫做字符平面。平时使用0号平面即可覆盖大部分场景。0号平面也叫做基本多文种平面(Basic Multilingual Plane, BMP)。
from wiki:
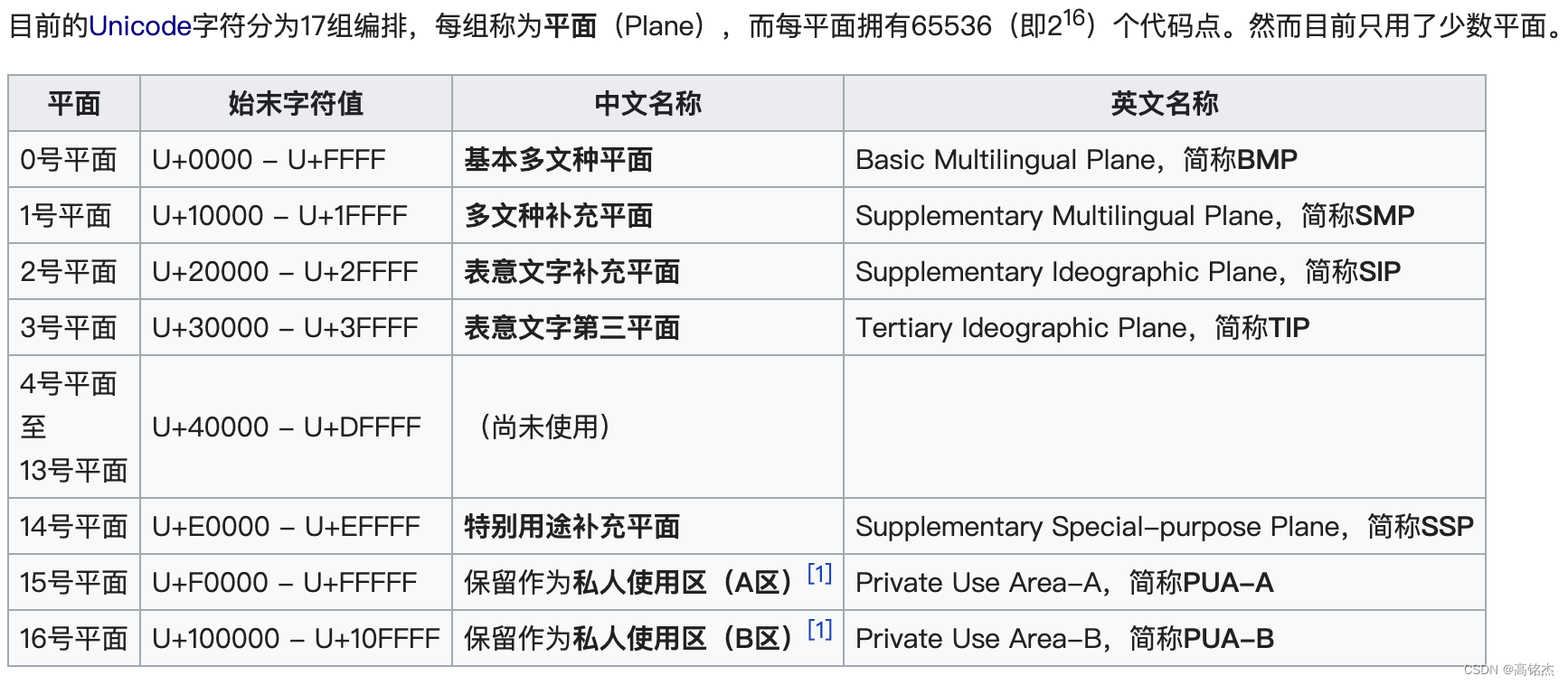
部分0号平面的分布: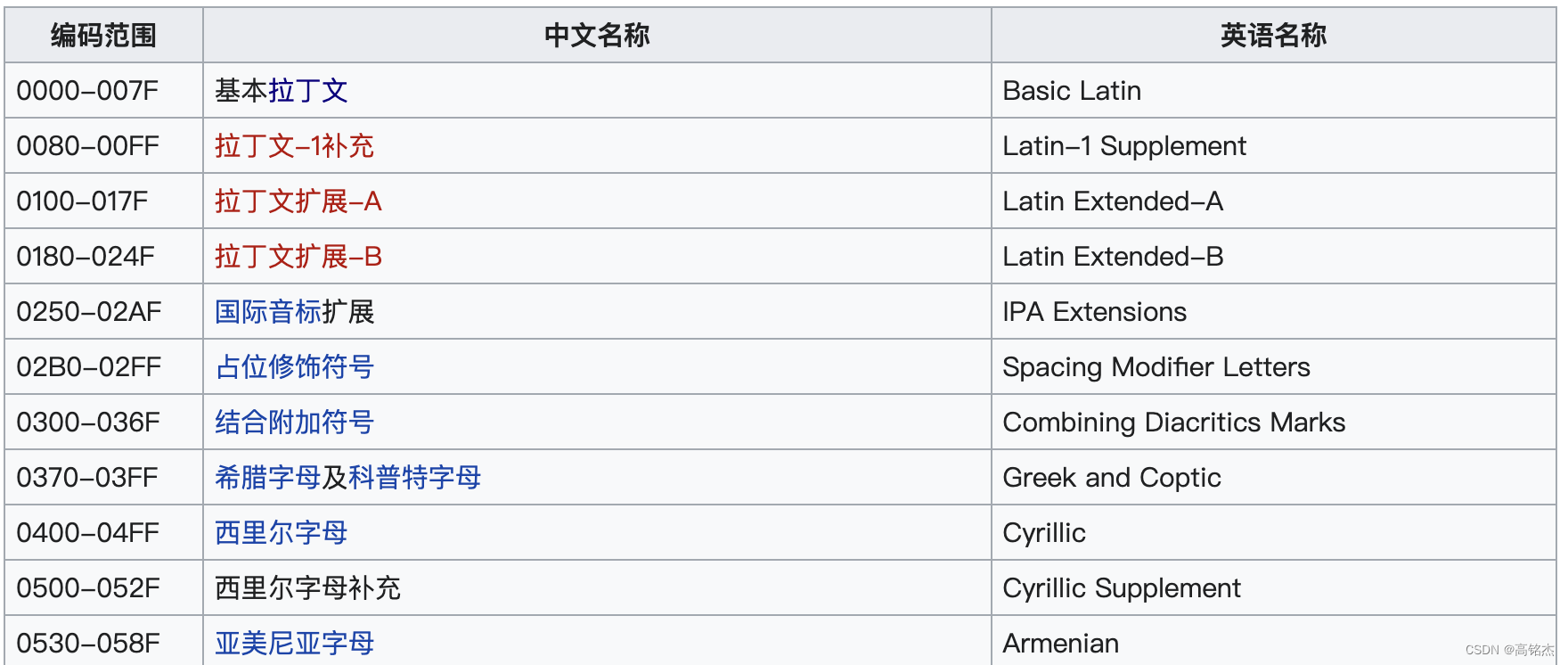
3.2 字符码与字符编码解耦
强映射的问题
传统编码中,字符码与字符编码是完全绑定的,例如在ASCII中,'a’的字符码是97,'a’的字符编码也是97。
在输入’a’时,系统直接映射为0110 0001存入即可,这种强映射方式好处是使用简单,快捷。但缺点是不灵活,每个字符码编码出的结果是固定的,如果存在这样一个场景:unicode四个字节中,英文字母只占很少的一部分,如果客户只使用英文,unicode中永远只有1个字节的数据是有意义的,剩下三个字节都没用到,但是强映射的方式下,数据传输、存储只能用4个字节,造成非常大的浪费。
unicode将字符码与编码解耦
在unicode中,每一个字符保证有唯一字符码,将 字符码到存储二进制之间的“字符编码”过程独立出来,提供了三种编码方法:
- UTF-8:使用1或2或3或4个字节。
- UTF-16:使用2或4个字节
- UTF-32:固定使用4个字节。

例如a在UTF-16下编码为0x0061占用两个字节,在UTF-8下编码为0x61占用一个字节。
4 总结
需要注意字符集和字符编码是不同的。比如当我们提到“数据库使用的是unicode字符集”,这样的说法是错误的,数据库中的数据一定要具体到某一种字符编码,只提到字符集是没有意义的,例如数据库使用UFT-8编码。
- 字符集:字符和字符码的映射关系,例如在ASCII中a的字符码就是97,表示在字符集的97号位置上是字符’a’。
- 字符编码:字符与字节流的映射关系,例如在ASCII中’a’的字节流就是01100001,在UTF中根据编码方式的不同,可能是
01100001或0000000001100001。
名字解释:
- Code Point = 字符码
- Character Set = 字符集
- Character Encoding = 字符编码