牛客竞赛字符串专题 NC237664 Typewriter(SAM + 树上倍增 + 二分 + 线段树优化dp)

本题主要考察了如何用 SAM 求原串每个前缀对应的能与非后缀匹配的最长后缀,以及如何求 SAM 每个节点 right 集合的 min / max。很有价值的一道串串题。
题意:
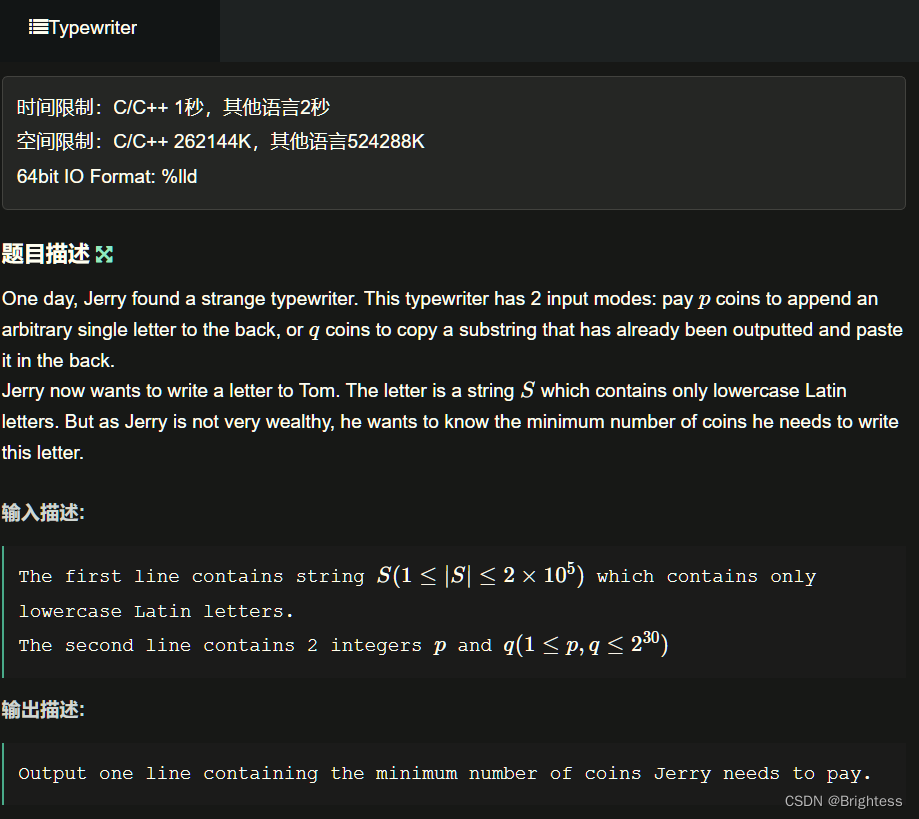
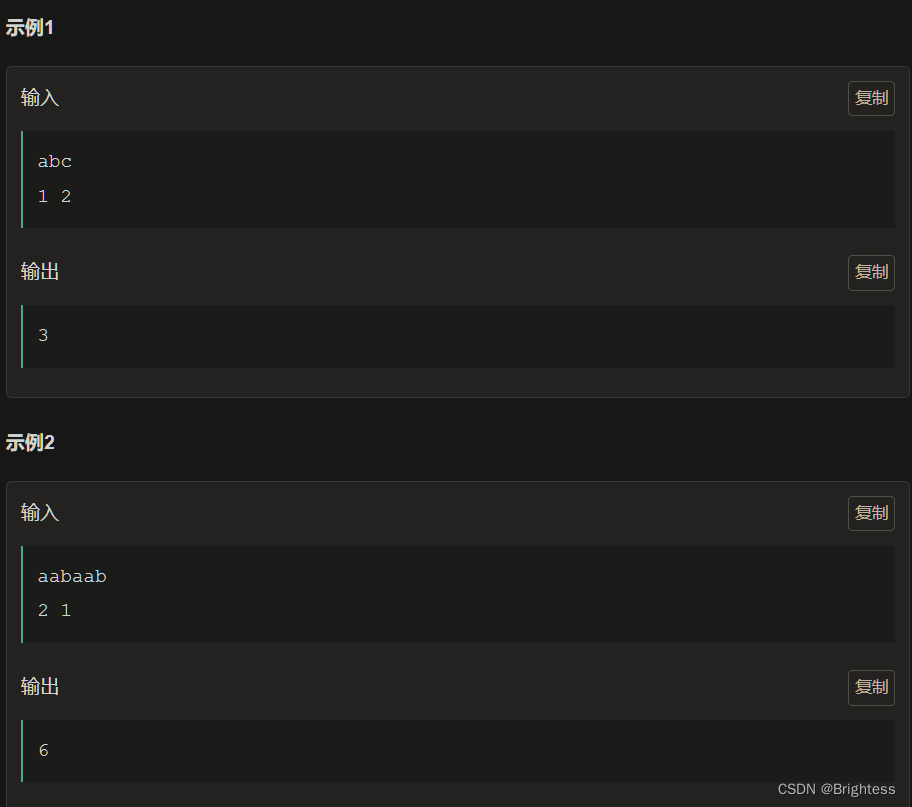
你有一台打字机,你需要用它打出一段只由小写字母构成的文本S。
设某个时刻,你已经打出来的文本为 T,你可以执行两种操作:
- 花费 p 块钱,将T后面添加一个字符 ch,得到 T = T + ch。
- 花费 q 块钱,将 T 的一个 子串 S 复制一份,添加到 T 的后面,得到 T = T + S。
问:为了得到 S,最少的花费是多少。
思路:
本题可以用 DP 解决,设 dp[i] 表示得到 S[1, i] 的最小代价。
考虑如何计算 dp[i]:
- 第一种操作带来的转移是:dp[i] ← dp[i - 1] + p。
- 第二种操作要求我们求最长的 S[1, i] 的后缀 S[i - x + 1, i],使得他在 S[1, i - x] 中也出现过,带来的转移是:dp[i] ← min(dp[i - x, …, i - 1]) + q。
Q1:对于每个前缀 S[1, i],如何预处理它最长的后缀 S[i - x+ 1, 1],使得他在 S[1, i - x] 中也出现过呢?
-
我们可以结合在 NC237662 葫芦的考验之定位子串 这题中的思想进行思考:对于某一个前缀 S[1, i],他的所有后缀均在它所在节点与根相连的后缀链接上。因此,我们可以不断在后缀链接上找,当链上某个节点 u 代表的长度范围在 len[fa[u]] + 1 ~ len[u] 的这类子串中,存在一个长度为 anslen 的子串(注意这里是存在即可),它结束位置的最小值 mned[u] < i - anslen + 1 退出查找(贪心的找最深的节点,因为节点越深越能包含更长的子串)。还没完,我们还需要在这个节点上二分子串长度,寻找该前缀的最长后缀。
-
显然上述查找节点的过程不能暴力地找,要使用树上倍增(dfs 预处理倍增表)。
Q2:第二步操作带来的状态转移需要求区间 min,怎么优化?
- 线段树优化 dp。
时间复杂度:
构建 SAM:O(n)
两个预处理、线段树优化 dp:O(nlogn)
代码:
#include<bits/stdc++.h>using namespace std;
const int N = 2e5 + 10, M = N << 1, mx = 20;
int ch[M][26], fa[M], len[M], np = 1, tot = 1;
vector<int> g[M];
//分别表示:节点代表子串最小结束位置,每个前缀对应的能与非后缀匹配的最长后缀
int mned[M], x[M];
char s[N];
int p, q;
int pa[M][mx]; //倍增表
struct node
{int l, r;long long mn;
} dp[N << 2]; //直接把线段树数组当做 dp 数组void extend(int c)
{int p = np; np = ++tot;len[np] = len[p] + 1, mned[np] = len[np] - 1;while (p && !ch[p][c]) {ch[p][c] = np;p = fa[p];}if (!p) {fa[np] = 1;}else {int q = ch[p][c];if (len[q] == len[p] + 1) fa[np] = q;else {int nq = ++tot;len[nq] = len[p] + 1;fa[nq] = fa[q], fa[q] = fa[np] = nq;while (p && ch[p][c] == q) {ch[p][c] = nq;p = fa[p];}memcpy(ch[nq], ch[q], sizeof ch[q]);}}
}void dfs(int u, int f) //dfs 预处理树上倍增表
{pa[u][0] = f;for (int i = 1; i <= mx - 1; ++i) {pa[u][i] = pa[pa[u][i - 1]][i - 1];}for (auto son : g[u]) {dfs(son, u);mned[u] = min(mned[u], mned[son]);}
}void init() //预处理 x 数组
{int p = 1;for (int i = 0; s[i]; ++i){p = ch[p][s[i] - 'a'];int tmp = p;for (int j = mx - 1; j >= 0; --j) {int ff = pa[tmp][j];int mnlen = len[fa[ff]] + 1;//倍增父节点不满足就一直跳,满足了立刻退出,找满足条件最深的节点if (mned[ff] >= i - mnlen + 1) { tmp = ff;}}tmp = pa[tmp][0]; //再跳一格//首先不能是根,其次要满足条件,我们才在该节点二分答案if (p > 1 && mned[tmp] < i - (len[fa[tmp]] + 1) + 1){int l = len[fa[tmp]] + 1, r = len[tmp];while (l < r) {int mid = l + r + 1 >> 1;if (mned[tmp] < i - mid + 1) l = mid;else r = mid - 1;}x[i] = r;}else x[i] = 0; //如果是根或者不满足条件,也就是不存在对应后缀,置为 0}
}void pushup(int u)
{dp[u].mn = min(dp[u << 1].mn, dp[u << 1 | 1].mn);
}void build(int u, int l, int r)
{dp[u] = { l, r };if (l == r) {dp[u].mn = 0;return;}int mid = l + r >> 1;build(u << 1, l, mid), build(u << 1 | 1, mid + 1, r);
}void modify(int u, int x, long long v)
{if (dp[u].l == x && dp[u].r == x) {dp[u].mn = v;return;}int mid = dp[u].l + dp[u].r >> 1;if (x <= mid) modify(u << 1, x, v);else modify(u << 1 | 1, x, v);pushup(u);
}long long ask(int u, int l, int r)
{if (l <= dp[u].l && r >= dp[u].r) {return dp[u].mn;}int mid = dp[u].l + dp[u].r >> 1;long long ans = 1e18; //由于是 long long 这里要尽可能大,建议直接上 1e18if (l <= mid) ans = min(ans, ask(u << 1, l, r));if (r > mid) ans = min(ans, ask(u << 1 | 1, l, r));return ans;
}signed main()
{memset(mned, 0x3f, sizeof mned); //这里很重要,首先要全初始化为 infmned[0] = 0; //然后节点 0 要初始化为 0scanf("%s%d%d", s, &p, &q);int n = strlen(s);for (int i = 0; i < n; ++i) {extend(s[i] - 'a');}for (int i = 2; i <= tot; ++i) {g[fa[i]].emplace_back(i);}dfs(1, 0); //dfs 预处理树上倍增表init(); //预处理 x 数组build(1, 1, n), modify(1, 1, p);for (int i = 2; i <= n; ++i) {modify(1, i, ask(1, i - 1, i - 1) + p);if (x[i - 1]) { //只有对应后缀存在才进行转移!long long tmp = min(ask(1, i, i), ask(1, i - x[i - 1], i - 1) + q);modify(1, i, tmp);}}printf("%lld\\n", ask(1, n, n));return 0;
}