GeoDataFrame 应用:公园分布映射至subzone

0 问题描述
我们知道新加坡的monument分布:Monuments-Data.gov.sg
我们又知道新加坡的subzone信息: Master Plan 2019 Subzone Boundary (No Sea) - Datasets - Dataportal.asia
我们希望生成一个 dataframe,表示每一个subzone有几个monument
1 读取+处理数据
1.1 moument数据
1.1.1 读取数据
import geopandas as gpd
states = gpd.read_file('monuments-geojson.geojson')
states python包介绍:GeoPandas(初识)_UQI-LIUWJ的博客-CSDN博客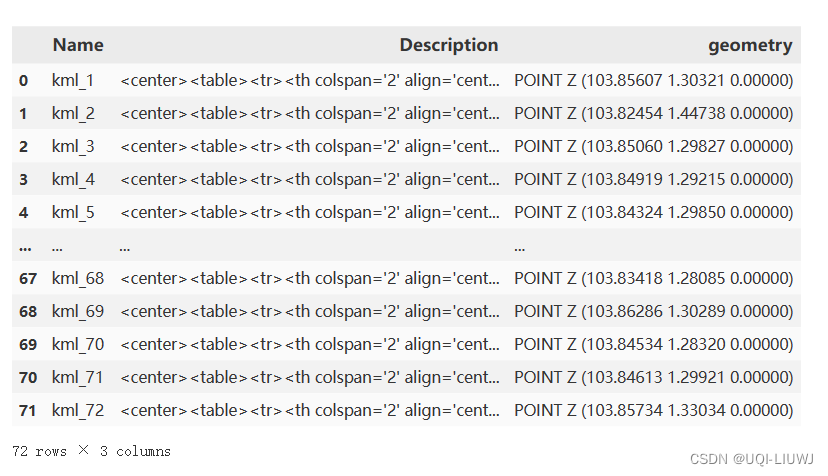
我们发现Description内容过长,显示不完整
于是我们加一行修饰
import geopandas as gpd
import pandas as pd
pd.set_option('max_colwidth',1000)
states = gpd.read_file('C:/Users/16000/Downloads/monuments/monuments-geojson.geojson')
states
1.2 subzone数据
1.2.1 读取数据
subzone = gpd.read_file('ura-mp19-subzone-no-sea-pl.geojson')
subzone
1.1.2 提取subzone、area和region
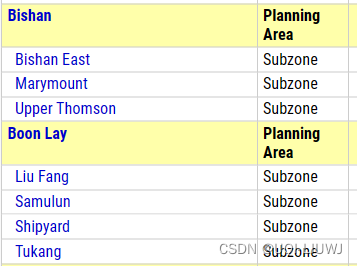
新加坡的行政区划分成了三级regions, planning areas and subzones(从大到小)
而在Desctiption中,也有这三个词条
我们接下来把他们分别提取出来,变成DataFrame的三个column
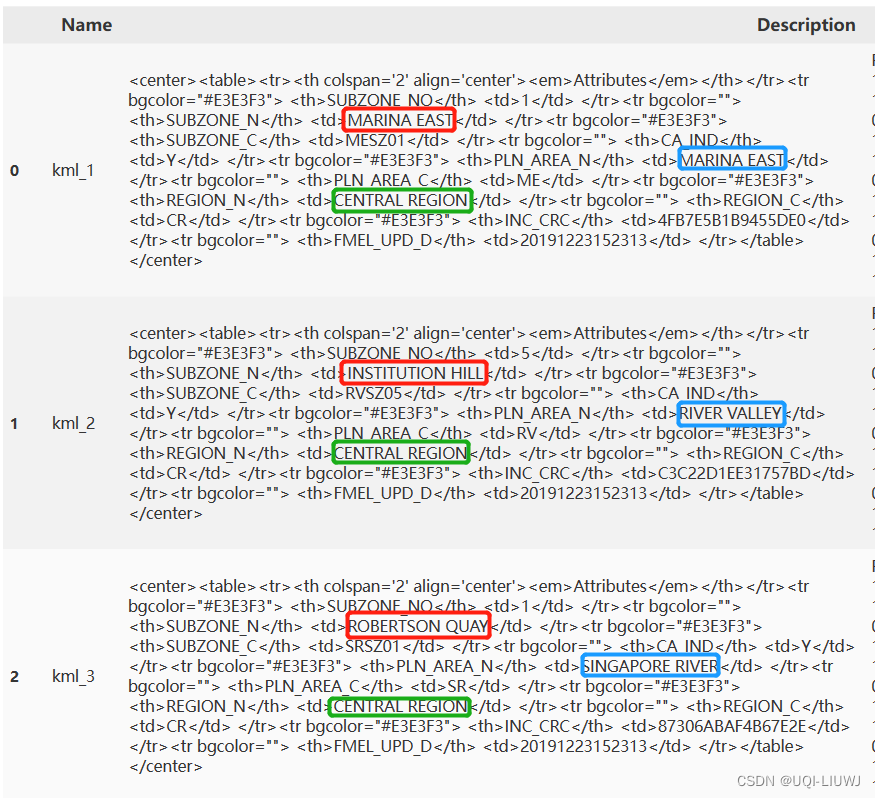
python笔记:正则表达式_UQI-LIUWJ的博客-CSDN博客
python 笔记:函数_UQI-LIUWJ的博客-CSDN博客
#我们使用正则表达式+Lambda 函数 进行subzone、area、region的信息提取#subzone
i=str(subzone.head(1).Description)
import re
accurate_name_subzone=lambda i:re.findall('<th>SUBZONE_N</th> <td>[\\s\\S]*?</td> </tr>',i)[0][23:-11]
accurate_name_subzone(i)
#'MARINA EAST'#area
i=str(subzone.head(1).Description)
import re
accurate_name_area=lambda i:re.findall('<th>PLN_AREA_N</th> <td>[\\s\\S]*?</td> </tr>',i)[0][24:-11]
accurate_name_area(i)
#'MARINA EAST'#region
i=str(subzone.head(1).Description)
import re
accurate_name_region=lambda i:re.findall('<th>REGION_N</th> <td>[\\s\\S]*?</td> </tr>',i)[0][22:0-11]
accurate_name_region(i)
#'CENTRAL REGION'subzone['subzone']=subzone.Description.apply(accurate_name_subzone)
#提取subzone这一列
subzone['area']=subzone.Description.apply(accurate_name_area)
#提取area这一列
subzone['region']=subzone.Description.apply(accurate_name_region)
#提取region这一列
subzone=subzone.drop(['Description'],axis=1)
#丢弃Description这一列
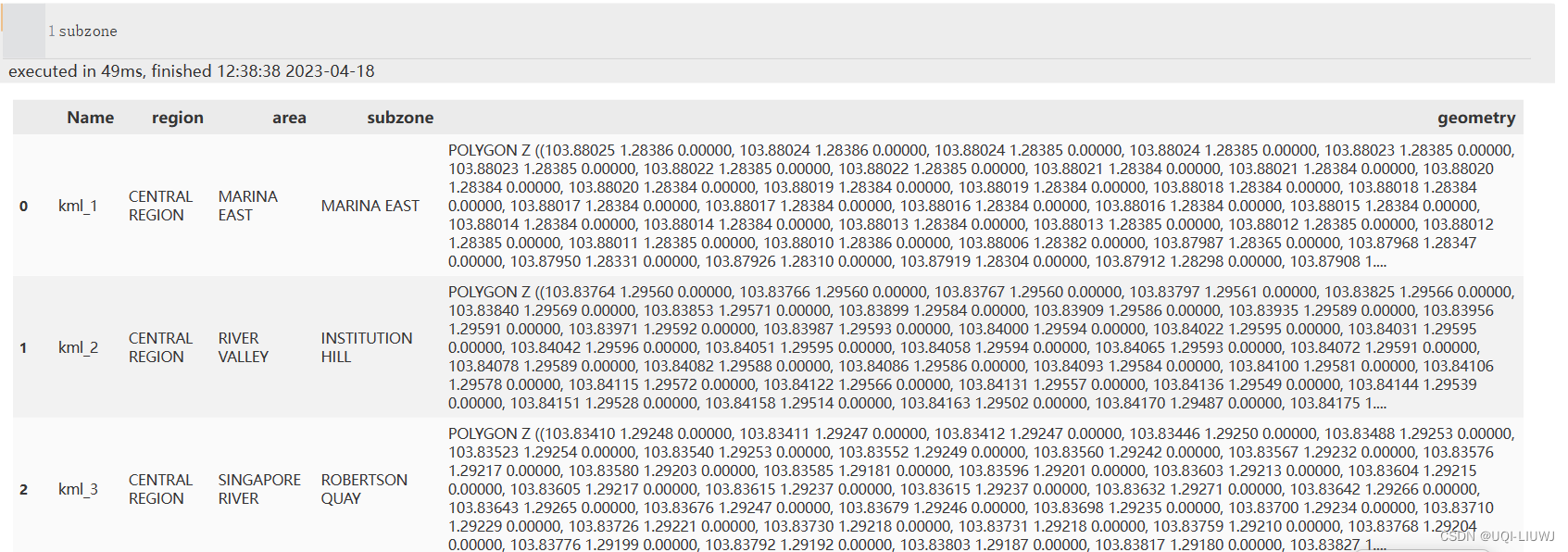
subzone=subzone[['Name','region','area','subzone','geometry']]
#重新排序subzone各列
subzone
2 绘制monument在subzone上的分布情况
ax=gpd.GeoSeries(subzone.geometry).plot(figsize=(50,15))
states['geometry'].plot(ax=ax,color='red')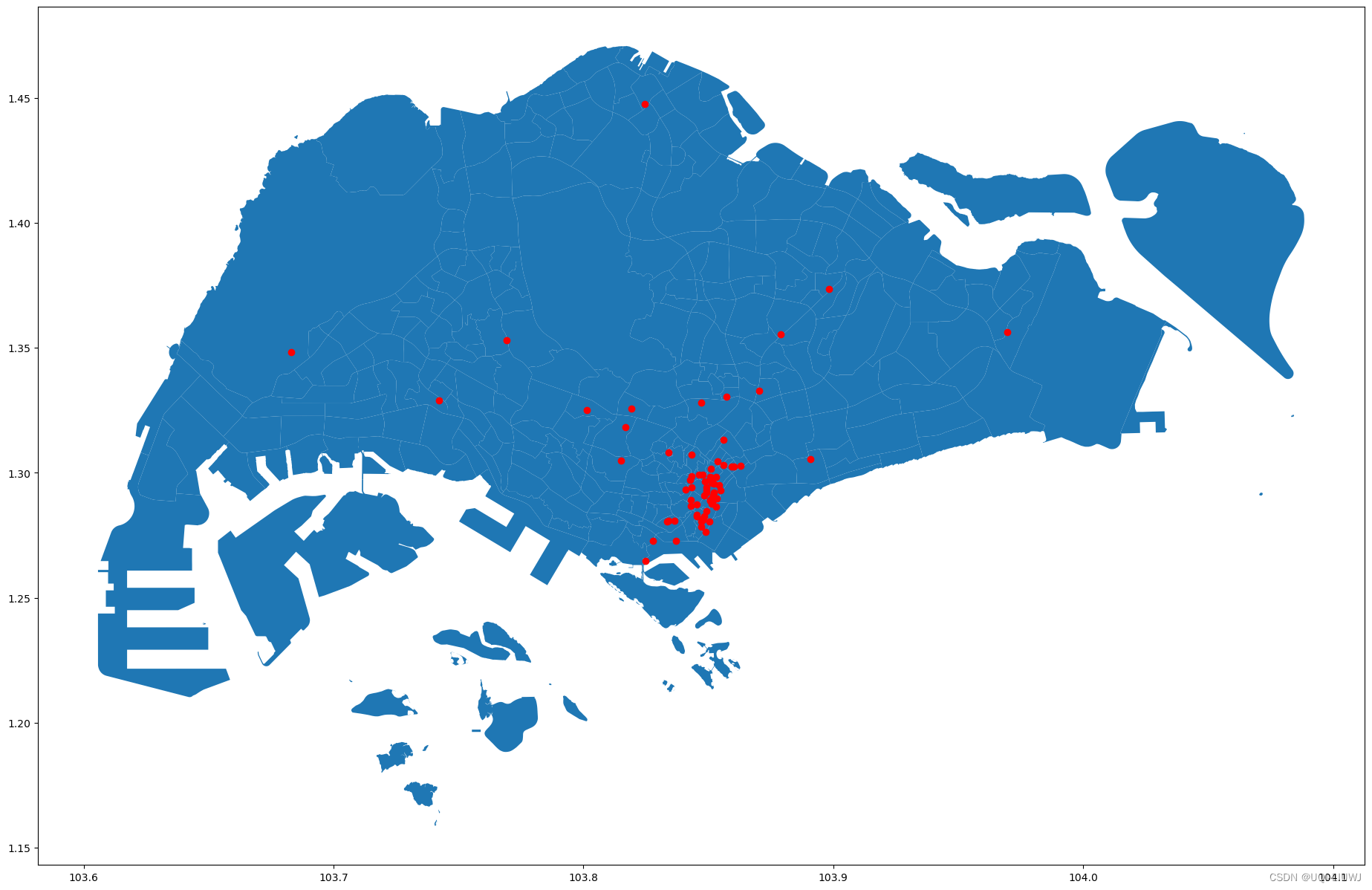
3 两个dataFrame进行合并
combine=gpd.sjoin(states, subzone, how='left',op="within")
combine=combine.drop(['Description'],axis=1)
combine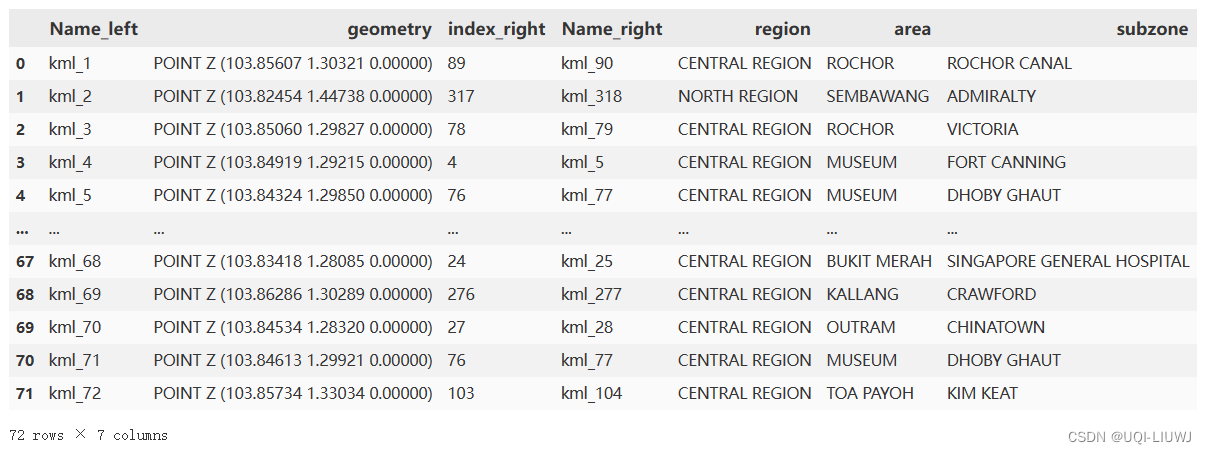
每一行就是某个monument对应哪个subzone的信息
4 统计每个subzone monument的
subzone['count_monument']=[0]*len(subzone)
#末尾添加一列,表示这个subzone有几个monuumentfor i in range(len(combine)):subzone.loc[subzone[subzone['subzone']==combine.iloc[i].subzone].index,'count_monument']+=1#subzone[subzone['subzone']==combine.iloc[i].subzone] 表示monument对应的subzone和哪个subzone对应
#加index是这个subzone在subzone DataFrame上的indexsubzone