爬虫请求头Content-Length的计算方法

重点:使用node.js 环境计算,同时要让计算的数据通过JSON.stringify从对象变成string。
1. Blob size
var str = '中国'
new Blob([str]).size // 62、Buffer.byteLength
# node
> var str = '中国'
undefined
> Buffer.byteLength(str, 'utf8')
6原文:Content-Length的计算 - 掘金
在写live-dev-server,向html文件中inject代码片段时,设定Content-Length出现了ERR_CONTENT_LENGTH_MISMATCH。
Content-Length
developer.mozilla.org/en-US/docs/…
Content-Length实体标头指示发送给接收者的实体主体的大小(以字节为单位)。用十进制标识的8位字节。
当浏览器接收内容的时候,如果设定了比正确的内容长度小的Content-Length,浏览器接收到内容就会被截断。如下,body,html标签已经被截断了:
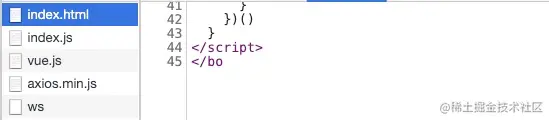
如果设定大了,浏览器就会一直处于等待加载更多内容的状态,然后再抛出ERR_CONTENT_LENGTH_MISMATCH。

res.setHeader('Content-Length', len + 200)
复制代码英文、数字长度计算
服务端在设定Content-Length的时候,可以设置charset,一般设定为UTF-8。我们在计算长度的时候,UTF-8编码下,英文、数字用一字节编码。如下伪代码:
const INJECT_STR = fs.readFileSync('./inject', { encoding: 'utf-8' })
// 在返回的时候
let len = INJECT_STR.length
len += res.getHeader('Content-Length')
res.setHeader('Content-Length', len)
复制代码这个一般是没有问题的,但是前提是在inject文件里,没有出现中文。如果出现中文,就会有截断的情况出现。
中文长度计算
UTF-8里面,绝大多数中文是3个字节,字符串的length是1,这就造成了结果长度必然小于实际长度,导致内容被截断。 计算的方式可以用下面的方法计算,
参考见 stackoverflow.com/questions/5…
1. Blob size
var str = '中国'
new Blob([str]).size // 6
复制代码2. charCodeAt
stackoverflow.com/questions/5…
function byteLength(str) {// returns the byte length of an UTF-8 stringvar s = str.length;for (var i=str.length-1; i>=0; i--) {var code = str.charCodeAt(i);if (code > 0x7f && code <= 0x7ff) s++;else if (code > 0x7ff && code <= 0xffff) s+=2;if (code >= 0xDC00 && code <= 0xDFFF) i--; //trail surrogate}return s;
}
byteLength(str) // 6
复制代码3. Buffer.byteLength
# node
> var str = '中国'
undefined
> Buffer.byteLength(str, 'utf8')
6
复制代码总结
- 在如果中文可以不要的情况下,尽量改用英文。
- 使用方法正确计算出
Content-Length。 - node中使用
Buffer.byteLength或Blob计算长度。
作者:lceric
链接:https://juejin.cn/post/6919396936382414861
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。