04-Mysql常用操作

1. DDL
常见数据库操作
# 查询所有数据库
show databases;
# 查询当前数据库
select databases();# 使用数据库
use 数据库名;# 创建数据库
create database [if not exits] 数据库名; # []代表可选可不选# 删除数据库
drop database [if exits] 数据库名;常见表操作
创建表:
create table 表名(字段1 字段类型 [约束] [comment 字段1备注信息],...字段n 字段类型 [约束] [comment 字段n备注信息]
)[comment 表备注信息];# eg:
create table tb_user(id int primary key comment 'ID,唯一标识',username varchar(20) not null unique comment '用户名',name varchar(20) not null comment '姓名',age int comment '年龄',gender char(1) default '女' comment '性别'
)comment '用户表';常见约束:

# 查询当前数据库的所有表
show tables;
# 查询表结构
desc 表名;
# 查询建表语句
show create table 表名;
# 添加字段
alter table 表名 add 字段名 类型(长度) [comment 备注信息] [约束];
# 修改字段类型
alter table 表名 modify 字段名 新数据类型(长度);
# 修改字段名和字段类型
alter table 表名 change 旧字段名 新字段名 类型(长度) [comment 备注信息] [约束];
# 删除字段
alter table 表名 drop column 字段名;
# 修改表名
rename table 表名 to 新表名;2. DML(数据操作语言)
插入(insert)
# 指定字段添加数据
insert into 表名(字段1,字段2) values(值1,值2);
# 全部字段添加信息
insert into 表名 values(值1,值2);
# 批量添加数据(指定字段)
insert into 表名(字段1,字段2) values(值1,值2),(值1,值2);
# 批量添加数据(全部字段)
insert into 表名 values(值1,值2),(值1,值2);注意事项:
1. 插入数据时,指定的字段顺序需要与值的顺序一一对应
2. 字符串和日期型数据应该包含在引号中
更新(update)
# 修改数据
update 表名 set 字段名1=值1,字段名2=值2 [where 条件];删除(delete)
# 删除数据
delete from 表名 [where 条件];注意事项:
1. 如果没有where 条件,则会清空表
2. delete不能删除某一个字段的值(如果要操作,可以使用update,将该字段的值设为null)
3. DQL(数据查询语言) (select)
# 语法
select 字段名1,字段名2 from table 表1,表2
where 条件列表
group by 分组字段列表
having 分组后条件列表
order by 排序字段列表
limit 分页参数基本查询:
# 查询多个字段
select 字段1,字段2 from 表名;
# 查询所有字段
select * from 表名;
# 设置表名
select 字段1 as 别名1,字段2 as 别名2 from 表名;
# 去除重复记录
select distinct 字段列表 from 表名;条件查询(where)

分组查询(group by)
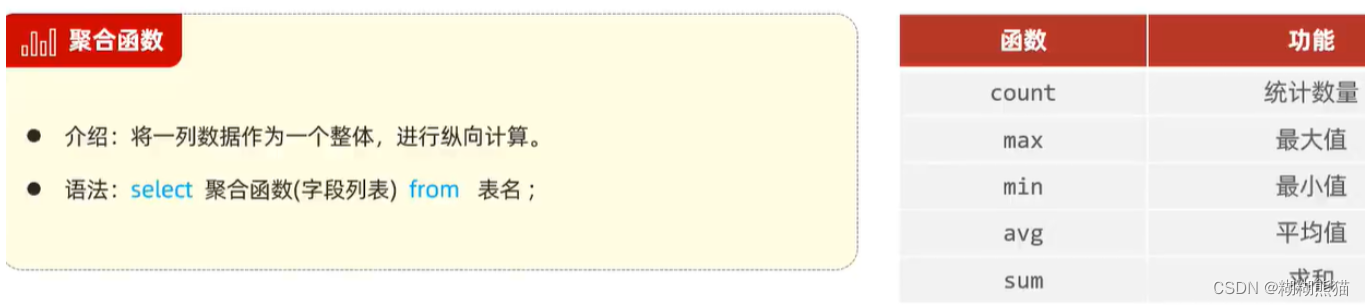
注意事项:
1. null 不参与所有聚合函数运算
2. 统计数量推荐使用 :count(*)
# 语法
select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组过滤条件];# eg:查询入职时间在‘2015-01-01’(包含)以前的员工,并对结果根据职位分组,获取庺数量大于等于2的职位
select job,count(*) from tb_emp where entrydate <= ‘2015-01-01’ group by job having count(*) >=2;排序查询(order by)
# 语法
select 字段列表 from 表名 [where 条件列表] [group by 分组字段] order by 字段1 排序方式1,字段2 排序方式2;默认排序方式:asc(升序)
desc(降序)
如果是多字段值排序,只有在前一个字段值相同的情况下,才会根据下一个字段排序
分页查询(limit)
select 字段列表 from 表名 limit 起始索引,查询记录数;注意事项:
1. 起始索引从0开始,起始索引=(查询页码-1)* 每页显示的记录数
2. 如果查询的是第一页数据,起始索引可以省略,直接简写 limit 查询记录数
补充:if条件语句
if条件语句:
if(条件表达式,true取值,false取值)
case表达式
case 表达式 when 值1 then 结果1 when 值2 then 结果2 else 其他结果 end
# eg1: 性别存储时,男存储的1,女存的2
select if(gender = 1 ,'男','女') 性别, count(*) from tb_emp group by gender;
# eg2: 职位在存储时,1:班主任 2:讲师 3:学工主管 4:教研主管 else 未分配职位
select (case job when 1 then '班主任' when 2 then '讲师' when 3 then '学工主管' when 4 then '教研主管' else '未分配职位') 职位, count(*)
from tb_emp group by job;4.多表操作
外键:
# 创建表时指定
create table 表名(...[constraint] 外键名称 foreign key(外键字段名) references 主表(字段名)
);
# 建完表后,添加外键
alter table 表名 add constraint 外键名称 foreign key(外键字段名) references 主表(字段名);
内连接:
# 隐式内连接
select 字段列表 from 表1,表2 where 条件;
# 显示内连接
select 字段列表 from 表1 [inner] join 表2 on 连接条件;外连接:
# 左外连接
select 字段列表 from 表1 left join 表2 on 连接条件;
# 右外连接
select 字段列表 from 表1 right join 表2 on 连接条件;5. 事务
概念:事务是一组操作的集合,它是不可分割的工作单位。事务会把所有操作作为一个整体一起向系统提交或撤销操作请求,即操作要么同时成功,要么同事失败。
事务控制:
# 开启事务
start transaction; / begin;
... (操作语句)
# 提交事务
commit;
# 回滚事务
rollback;四大特性(ACID):
原子性: 事务是不可分割的最小单元,要么全部成功,要么全部失败
一致性: 事务完成时,必须使所有的数据都保持一致的状态
隔离性: 数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行
持久性: 事务一旦提交或回滚,它对数据库中的数据的改变就是永久性的
6. 索引
概念:索引是帮助数据库高效获取数据的数据结构(默认B+Tree多路平衡搜索树)
优点:提高查询和排序的效率
缺点:占用磁盘空间、降低了insert、update、delete的效率
语法:
# 创建索引
create [unique] index 索引名 on 表名(字段名,...);
# 查看索引
show index from 表名;
# 删除索引
drop index 索引名 on 表名;注意事项:
1. 主键字段,在建表时,会自动创建主键索引
2. 添加唯一索引约束时,数据库会添加唯一索引