【Python_Scrapy学习笔记(十)】基于Scrapy框架的下载器中间件创建代理IP池

基于Scrapy框架的下载器中间件创建代理IP池
前言
本文中介绍 如何基于 Scrapy 框架的下载器中间件创建代理IP池。
正文
1、添加中间件的流程
- 在 middlewares.py 中新建 代理IP 中间件类
- 在 settings.py 中添加此下载器中间件,设置优先级并开启
2、基于Scrapy框架的下载器中间件创建User-Agent池的具体操作
-
在 middlewares.py 中新建 代理IP 中间件类
# 中间件2:随机的代理 import random from .proxies import proxy_lstclass BaiduRandomProxyDownloaderMiddleware(object):def process_request(self, request, spider):"""创建代理IP池:param request::param spider::return:"""proxy = random.choice(proxy_lst)# 如何包装到请求对象中去?# 使用meta属性# 作用1:在不同解析函数之间传递数据 作用2:可以定义代理request.meta['proxy'] = proxyprint(proxy)def process_exception(self, request, exception, spider):"""处理异常:代理IP可能不能用,scrapy会自动尝试3次抛出异常,需要一直尝试:param request::param exception::param spider::return:"""# Called when a download handler or a process_request()# (from other downloader middleware) raises an exception.# Must either:# - return None: continue processing this exception# - return a Response object: stops process_exception() chain# - return a Request object: stops process_exception() chainreturn request``` 注意1:因代理IP质量不一,故当遇到无效的代理 IP 时需要捕获异常更换 IP,或重新尝试,Scrapy 框架提供了 process_exception() 方法进行异常的捕获。```pythondef process_exception(self,request,exception,spider):return request注意2:
from .proxies import proxy_lst是在项目目录下创建的存放代理 IP 的 py 文件proxy_lst = ['http://27.42.168.46:55481','http://61.216.185.88:60808', ]
-
在 settings.py 中添加此下载器中间件,设置优先级并开启
# Enable or disable downloader middlewares # See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html # 开启中间件 DOWNLOADER_MIDDLEWARES = {"BaiduMiddle.middlewares.BaidumiddleDownloaderMiddleware": 543,"BaiduMiddle.middlewares.BaiduRandomProxyDownloaderMiddleware": 300, } -
运行效果
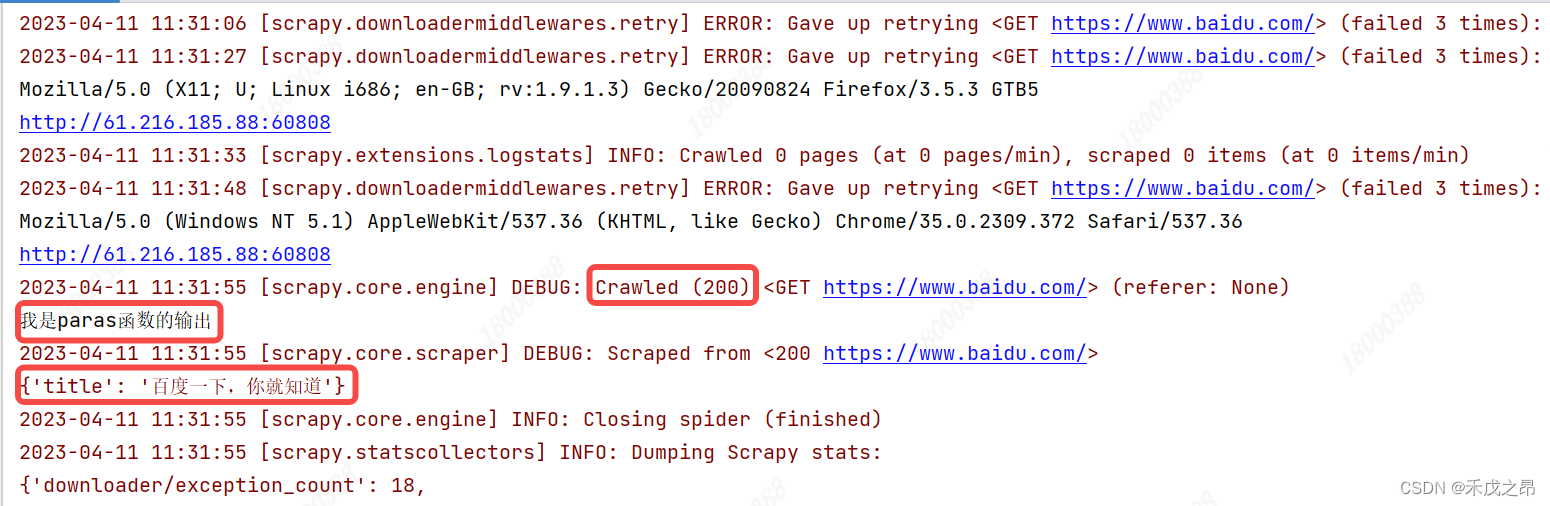
可以看到通过 代理IP 成功访问了百度。