Redis数据库

文章目录
一、NoSQL
NoSQL(not only sql)
一类新出现的数据库,泛指
非关系型数据库;
不支持SQL语法;
存储结构和传统关系型数据库中的那种关系完全不同,nosql中存储的数据都是KV形式;
NoSQL中没有一种通用的语言,每种NoSQL数据库都有自己的api和语法,以及擅长的业务场景;
NoSQL种类很多,如Redis、MongoDB、Hbase hadoop、Cassandra hadoop
NoSQL和SQL数据库区别
话用场景不同 : sql数据库适合用于关系特别复杂的数据查询场景,nosql反之
事务特性的支持: sql对事务的支持非常完善,而nosql基本不支持事务
两者在不断地取长补短,呈现融合趋势
二、Redis数据库
Redis简介
Redis是一个开源的使用ANSI C语言编写·支持网络、可基于内存亦可持久化的日志型,Key-Value数据库,并提供多种语言的AP1。Redis是 NOSQL技术阵营中的一员,它通过多种键值数据类型来适应不同场景下的存储需求,借助一些高层级的接口使用其可以胜任,如缓存、队列系统的不同角色
Redis特性
Redis 与其他 key - value 缓存产品有以下三个特点 :
Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
Redis支持数据的备份,即master-slave模式的数据备份。
Redis优势
性能极高:Redis能读的速度是110000次/s,写的速度是81000次/s
丰富的数据类型:Redis支持二进制案例的 Strinas,Lists,Hashes.Sets 及 Ordered Sets 数据类型操作
原子:Redis的所有操作都是原子性的:
丰富的特性:Redis还支持 publish/subscribe,通知,key 过期等等特性
Redis应用场景
用来做缓存,redis的所有数据是放在内存中的(内存数据库)
可以在某些特定应用场景下替代传统数据库,比如社交类的应用
在一些大型系统中,巧妙地实现一些特定的功能:session共享·购物车
Redis中文官网
三、Redis使用(windows)
Redis下载地址,下载后解压,配置环境变量
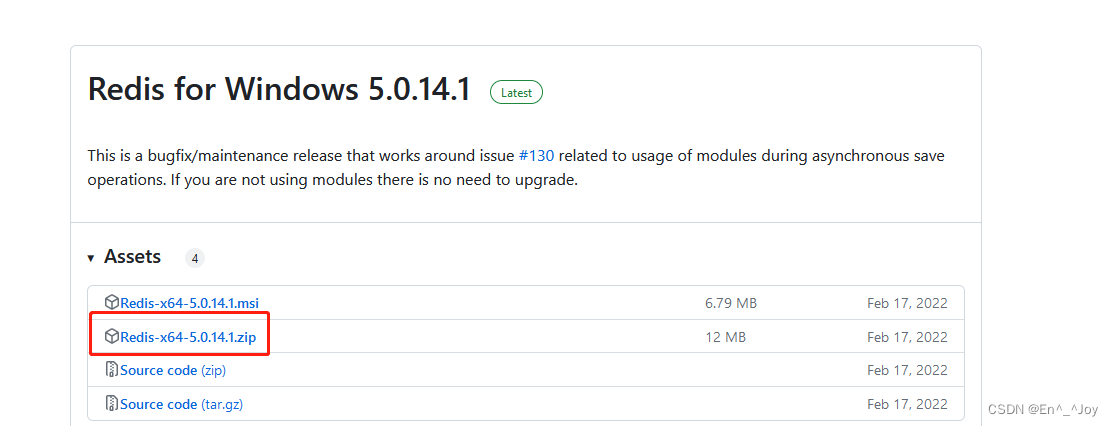
启动服务:redis-server
连接:redis-cli (可通过-h指定ip,-p指定端口,连接后运行ping测试是否连通)
redis配置文件为:redis.windows.conf、redis.windows-service.conf
redis绑定地址以及默认端口配置都可在这两个文件中找到
如果要远程访问,可以注释redis.windows.conf文件中的bind 127.0.0.1或者绑定一个真实的ip,里面的port为默认ip(6379)
该数据库默认有16个库,连上数据库后使用指令select 数字可以切换redis库(如select 0表示选择第一个库)
redis是key-value的数据结构,每条数据都是一个键值对,键的类型是字符串(键不能重复),值得类型有5种(字符串string、哈希hash、列表list、集合set、有序集合zset)

3.1 数据操作
数据操作行为:保存,修改,获取,删除
下面的操作都要在启动并连接之后在操作:启动服务:redis-server,连接:redis-cli
3.1.1 string
字符串类型是 Redis 中最为基础的数据存储类型,它在 Redis 中是二进制安全的,这便意味着该类型可以接受任何格式的数据,如JPEG图像数据或Json对象描述信息等:在Redis中字符串类型的Value最多可以容纳的数据长度是512M
操作:
如果设置的键不存在则为添加,存在则修改
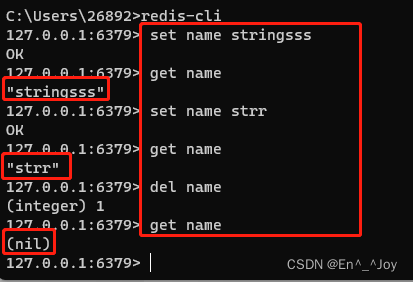
设置键值:set key value(如set name stringsss)
获取键值:get key(如get name)
删除键值:del key(如del name)
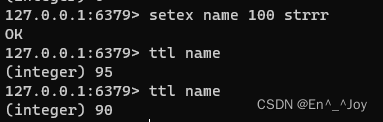
设置有效期:setex key expire_second value(如setex name 100 stringsss为设置name为stringsss保存100秒,到时间自动删除)
查看有效期:ttl key(如ttl name)
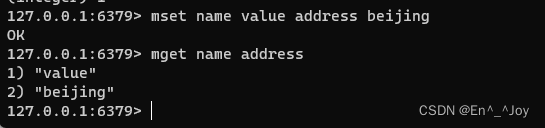
设置多个值:mset key1 value1 key2 value2
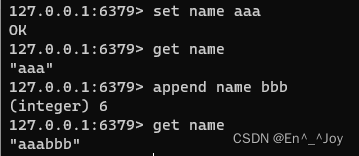
追加值:append key value(如append name aaa)
举例:设置键为name值为stringsss的数据:set name stringsss
举例:设置并查看有效期(到事件自动删除)
举例:设置并获取多个键值
举例:追加值(先设置为aaa,在添加bbb)
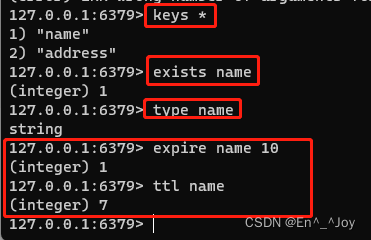
键的操作:
删除键值:
del key(如del name)
查看所有键:keys *(查看所有a开头的键:keys a*)
判断是否存在键值:exists key(如exists name)
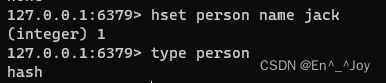
查看键值得类型:type key(如type name)
设置过期时间:expire key time(如expire name 10,使用ttl name查看)
3.1.2 hash类型
下面的操作都要在启动并连接之后在操作:启动服务:redis-server,连接:redis-cli
hash用于存储对象,对象的结构为属性、值,值得类型为string
设置单个属性:
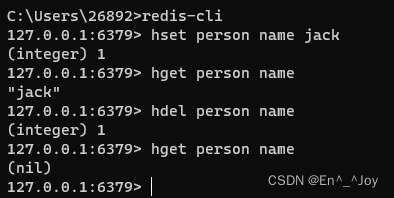
hset key field value(如设置键person的属性name为jack:hset person name jack)
获取单个属性:hget key field(如获取键user的属性name:hget person name)
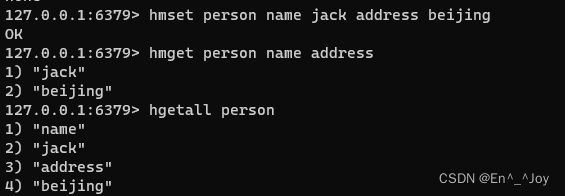
设置多个属性:hmset key field1 value1 field2 value2...(如设置person属性name和address:hmset person name jack address beijing)
获取多个属性:hmget key field1 field2...(如hmget person name address)
获取所有数据:hgetall key(如hgetall person)
查看所有key:hkeys key(如hkeys person)
查看所有value:hvals key(如hvals person)
删除单个属性:hdel key field(如hdel person name)
删除所有属性:del key(如del person)
修改值:hset key field values(如hset person name toy,存在则修改,不存在则添加)
查看键值得类型:type key(如type name)
举例:单个属性的设置、获取、删除
查看类型
多个元素的操作
3.1.3 列表(有序可重复)
列表的元素类型为string,安装插入顺序排序
下面的操作都要在启动并连接之后在操作:启动服务:redis-server,连接:redis-cli
左边插入(前面):
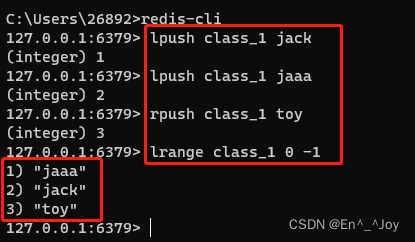
lpush key value( lpush class_1 jack)
右边插入(后面):rpush key value(rpush class_1 toy)
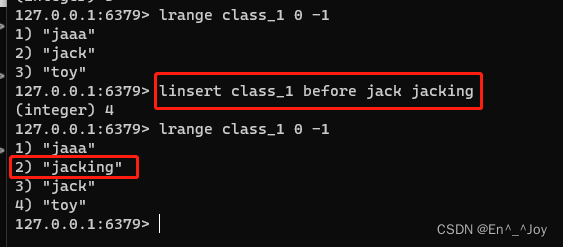
指定位置插入:linsert key before|after pivot value(before和after表示插入pivot的前面或者后面位置,pivot为存在的value)
获取列表:lrange key start stop(lrange class_1 0 -1) (0 -1是所有元素,后两个为索引号)
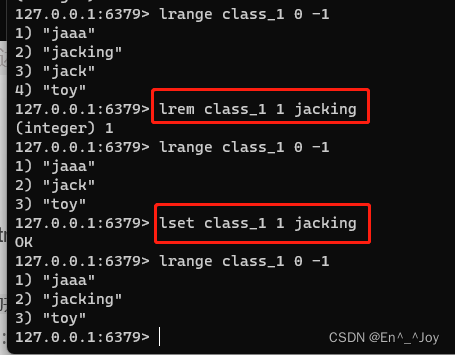
移除:lrem key count value(lrem class_1 1 jack) (count为0删除所有值为value相同的元素,count大于0从左边(上)删,小于0从右边(下)删,count为几删除几个)
修改数据:lset key index value(lset class_1 0 jacking) (index为索引号)
插入与查询
指定位置插入
删除与修改
3.1.4 set类型(无序不可重复)
set类型为无序集台,元素为string类型,元素具有唯一性,不重复,对于集合没有修改操作
下面的操作都要在启动并连接之后在操作:启动服务:redis-server,连接:redis-cli
添加元素:
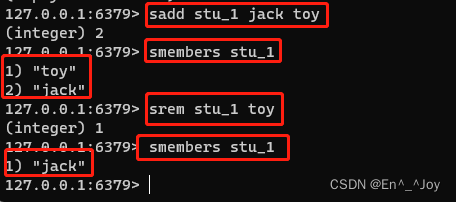
sadd key member1 member2 ...(sadd stu_1 jack toy)
查询:smembers key(smembers stu_1)
移除:srem key member1(srem stu_1 toy)
3.1.5 zset(有序集合)
zset类型为有序集台,元素为string类型,元素具有唯一性,不重复,每个元素都会关联一个double类型的score,表示权重,通过权重将元素从小到大排序,没有修改操作
下面的操作都要在启动并连接之后在操作:启动服务:redis-server,连接:redis-cli
添加:
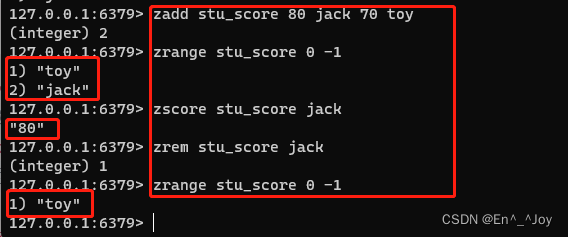
zadd key score1 member1 score2 member2 ...(如添加成绩单:zadd stu_score 80 jack 70 toy) (后续添加,顺序可能会改变,按权重score)
查询:zrange key 0 -1(zrange stu_score 0 -1)
查询权重在一定范围的元素:zrangebyscore key min max(zrangebyscore stu_score 50 80)
查看权重:zscore key member(zscore stu_score jack)
删除指定元素:zrem key members1 members2 ...(zrem stu_score jack)
删除权重在一定范围的元素:zremrangebyscore key min max(zremrangebyscore stu_score 50 80) (包括50和80)
3.2 Python操作Redis
上面几种操作的各种方法就是下面实例对象的操作函数
import redis# 创建redis连接实例
# 在连接/获取外界资源的时候一定要注意使用try
# host指定主机,port指定端口号,db指定第几个(总共16个,终端使用select切换)
r = redis.Redis(host='localhost', port=6379, db=0)
# 插入数据
result = r.set('foo1', 'bar')
# 查询获取数据
data = r.get('foo1')
print(result, data) # True b'bar'
四、搭建主从模式
主从概念
一个master(主)可以拥有多个slave(从),一个slave又可以拥有多个slave,如此下去,形成了强大的多级服务器集群架构。master用来写数据,slave用来读数据。通过主从配置可以实现读写分离。一主多从,当某个从出现问题,还有其他从可以使用
主服务器写数据,从服务器读数据(不能写)(连接时需指定ip和port:redis-cli -h 192.168.0.110 -p 6378),主从同步
配置主从
配置主:
ipconfig查看本地IP
修改redis.windows.conf文件如下内容为上面查询的IP:bind 192.168.0.110
重启redis服务:redis-server D:\\Redis\\redis.windows.conf
配置从:
复制redis.windows.conf到./slave.conf (后者名字任意)
修改redis/slave.conf内容如下:
bind 192.168.0.110
slaveof 192.168.0.110 6379
port 6378
运行从服务器redis服务:
redis-server D:\\Redis\\slave.conf
查看主从关系:redis-cli -h 192.168.0.110 info Replication

在上面搭建成功后,可以从新打开终端,分别连接主从服务(redis-cli -h 192.168.0.110 -p 6378),连接后可以查看一样的数据,主可以写入读取,从只能读取

五、搭建集群
之前我们已经讲了主从的概念,一主可以多从,如果同时的访问量过大,主服务肯定就会挂掉数据服务就挂掉了或者发生自然灾难。大公司都会有很多的服务器(华东地区、华南地区、华中地区、华北地区、西北地区、西南地区、东北地区、台港澳地区机房)。集群是一组相互独立的、通过高速网络互联的计算机,它们构成了一个组,并以单一系统的模式加以管理。一个客户与集群相互作用时,集群像是一个独立的服务器。集群配置是用于提高可用性和可缩放性。当请求到来首先由负载均衡服务器处理,把请求转发到另外的一台服务器上。
redis集群
软件层面:只有一台电脑,在这台电脑上启动了多个redis服务
硬件层面:存在多台电脑,每台电脑启动一个或多个1服务器
集群配置(如下为两台机器,每台3个)
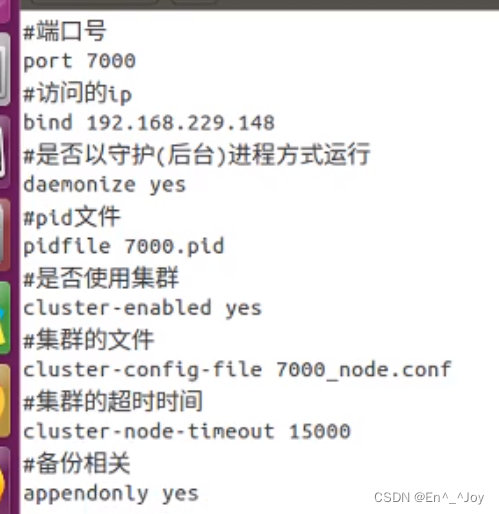
配置机器1:
在演示中,192.168.0.110为当前电脑的ip
在192.168.0.110机器上创建conf目录
在conf目录下创建文件7000.conf,编辑内容如下
port 7000
bind 192.168.0.110
daemonize yes
pidfile 7000.pid
cluster-enabled yes
cluster-config-file 7000_node.conf
cluster-node-timeout 15000
appendonly yes
在conf目录下创建文件7001.conf,编辑内容如下(标红为和上面的区别)
port 700
1
bind 192.168.0.110
daemonize yes
pidfile 7001.pid
cluster-enabled yes
cluster-config-file 7001_node.conf
cluster-node-timeout 15000
appendonly yes
在conf目录下创建文件7002.conf,编辑内容如下(标红为和上面的区别)
port 700
2
bind 192.168.0.110
daemonize yes
pidfile 7002.pid
cluster-enabled yes
cluster-config-file 7002_node.conf
cluster-node-timeout 15000
appendonly yes
配置机器2:
在演示中,192.168.0.111为当前ubuntu机器的ip
在192.168.0.111机器上创建conf目录
在conf目录下创建文件7003.conf,编辑内容如下
port 7003
bind 192.168.0.111
daemonize yes
pidfile 7003.pid
cluster-enabled yes
cluster-config-file 7003_node.conf
cluster-node-timeout 15000
appendonly yes
在conf目录下创建文件7004.conf,编辑内容如下(标红为和上面的区别)
port 700
4
bind 192.168.0.111
daemonize yes
pidfile 7004.pid
cluster-enabled yes
cluster-config-file 7004_node.conf
cluster-node-timeout 15000
appendonly yes
在conf目录下创建文件7005.conf,编辑内容如下(标红为和上面的区别)
port 700
5
bind 192.168.0.111
daemonize yes
pidfile 7005.pid
cluster-enabled yes
cluster-config-file 7005_node.conf
cluster-node-timeout 15000
appendonly yes
创建集群
redis的安装包中包含了redis-trib.rb,用于创建集群
接下来的操作在192.168.0.110机器上进行
将命令复制,这样可以在任何目录下调用此命令:sudo cp /usr/share/doc/redis-tools/examples/redis-trib.rb /usr/local/bin/
安装ruby环境,因为redis-trib.rb是用ruby开发的
sudo apt-get install ruby 在提示信息处输入y,然后回车继续安装
运行如下命令创建集群:redis-trib.nb create --replicas 1 192.168.0.110:7000 192.168.0.110:7001 192.168.0.110:7002 192.168.0.111:7003 192.168.0.111:7004 192.168.0.111:7005
(上面的1表示一主一从,是三个节点)
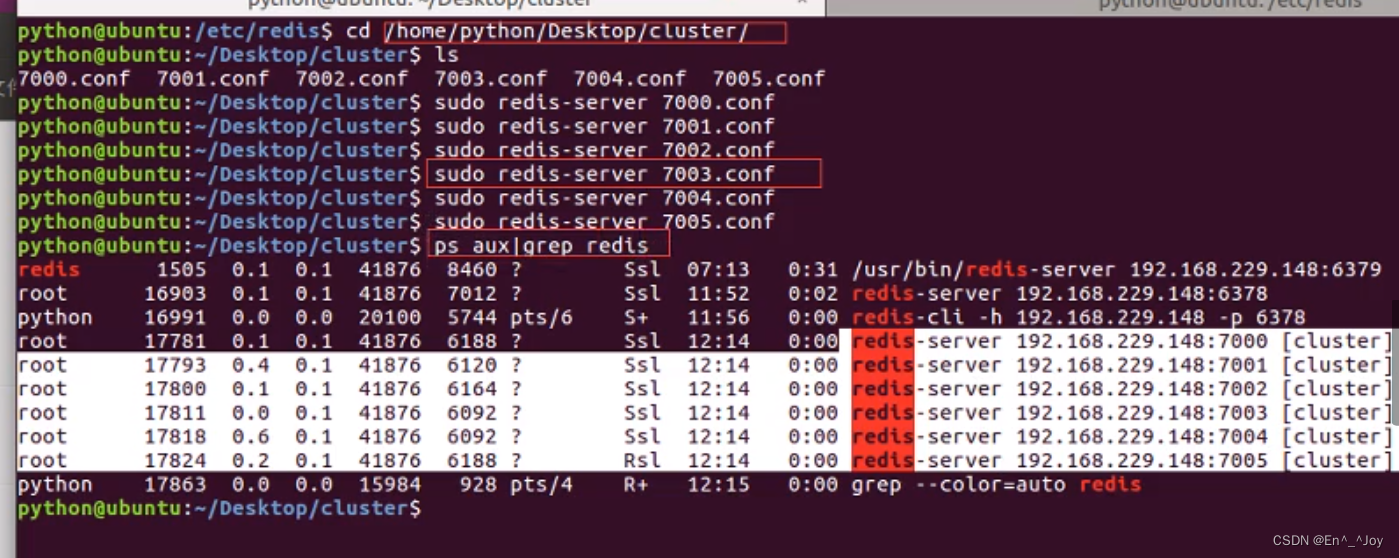
连接集群:redis-cli -h 192.168.229.148 -p 7000 -c,连接后写入数据不一定写在7000里面,通过一定的算法可能写在7001或者其他地方
redis cluster在设计的时候,就考虑到了去中心化,去中间件,也就是说,集群中 的每个节点都是平等的关系,都是对等的,每个节点都保存各自的数据和整个集 群的状态,每个节点都和其他所有节点连接,而且这些连接保持活跃,这样就保 证了我们只需要连接集群中的任意一个节点,就可以获取到其他节点的数据
Redis集群没有并使用传统的一致性哈希来分配数据,而是采用另外一种叫做哈希槽 (hash slot)的方式来分配的·redis cluster 默认分配了 16384 个slot,当我们set一个key 时,会用CRC16算法来取模得到所属的slot,然后将这个key 分到哈 希槽区间的节点上,具体算法就是:CRC1(key)% 16384·所以我们在测试的 时候看到set 和 get 的时候,直接跳转到了7000端口的节点
Redis 集群会把数据存在一个 master 节点,然后在这个 master 和其对应的salve 之间进行数据同步。当读取数据时,也根据一致性哈希算法到对应的 master 节点获取数据·只有当一个master 挂掉之后才会后动一个对应的 salve 节点,充当master
需要注意的是:必须要3个或以上的主节点,否则在创建集群时会失败,并且当存 活的主节点数小于总节点数的一半时,整个集群就无法提供服务了
六、python实现集群
pip install redis-py-cluster
from rediscluster import *
from rediscluster import StrictRedisCluster
# 构建所有的节点,Redis会使用CRC16算法,将银和值写到某个节点上
star = [{'host': '192.168.26.128', 'port': '7000'},{'host': '192.168.26.130', 'port': '7003'},{'host': '192.168.26.128', 'port': '7001'},
]
# 构建StrictRedisCluster对象
src=StrictRedisCluster(startup_nodes=star, decode_responses=True)
# 设置键
src.set('foo','bar')
print(src.get('foo'))
运行后,在终端查询不同数据时,会自动切换端口