九耶丨钛伦特-用深度学习实现垃圾图像分类(一)

在这个项目中我们将结合我们的日常生活,让计算机帮助我们进行垃圾分类。比如让计算机能够正确将如下三张包含不同垃圾的图像进行分类。



我们希望计算机能够识别出三张图像依次是玻璃(玻璃瓶),纸张(信封)和塑料 (塑料瓶)。
面对这样一个实际的问题,我们首先需要将这个任务能够转化成一个在深度学习
监督任务场景下的问题。根据我们在项目一中的学习,深度学习中监督学习的任务流程如下:
1. 采集数据集及数据清洗
2. 数据加载及预处理
3. 用训练数据集训练神经网络
4. 用训练好的网络模型对测试数据集进行测试
5. 推导计算应用
根据一般的任务流程,我们首先需要搜集建立一个数据集,这个数据集需要包含玻璃纸张和塑料这三类垃圾的多张图像,并人为给出这三类图像的标签。为了简化大家的学习过程,平台提供了数据集 garbage。有了数据集之后,再来构造神经网络模型,接着将预处理好的数据集输入模型进行训练。完成训练之后对训练返回的模型在测试集上进行结果评估。
预加载代码:

一、加载数据集
这里平台提供数据集 garbage,garbage 数据集包含 6 个类别分别是:
• 硬纸板(cardboard)训练集有 322,测试集有 81,共 403 张图片
• 玻璃(glass)训练集有 400,测试集有 101,共 501 张图片
• 金属(metal)训练集有 328,测试集有 82,共 410 张图片
• 纸(paper)训练集有 475,测试集有 119,共 594 张图片
• 塑料(plastic)训练集有 385,测试集有 97,共 482 张图片
• 一般垃圾(trash)训练集有 109,测试集有 28,共 137 张图片
物品都是置于白板上在日光/室内光源下拍摄,图像的尺寸为 512 * 384 * 3。我们制作数据集时,将物体放在白色背景下,是为了实现单一背景,这样能够更好地突出需要识别和分类的物体。同样,我们也尽可能的让物体处于图像的中间位置,并占满全图。
下图是相关的部分图片。

从这个数据集可以看到,我们真实图像尺寸远远大于我们之前在项目一和项目二中实验的数据。所以面对这样的数据集时,我们不再使用之前的方法,将数据集转换成numpy array 的形式保存,而是直接以图像的格式,比如 jpg 或者 png 等格式。
这样保存的图像,让我们需要使用另外的方法来加载,这里我们介绍 torchvision 三方库下的方法 ImageFolder。
ImageFolder(root)
• root :str 图像数据集路径
我们从 torchvision 中导入 ImageFolder from torchvision.datasets import
ImageFolder,然后平台提供了数据集 garbage 的路径 GARBAGE_IMG_ROOT。因为数据集被分成了训练和测试两个部分,所以需要在 GARBAGE_IMG_ROOT 之后增加’train’和 ’test’来指明是训练还是测试数据。
样例代码:
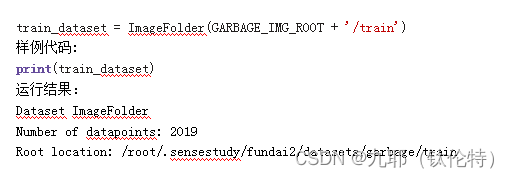
直接输出 train_dataset,可以看到 ImageFolder 并没有将图像加载进来,而是记录下了数据集的路径和图像总数,训练集一共有 2019 张图像。
需要说明的是,ImageFolder 返回的 train_dataset 是一个 Dataset,这个 Dataset 并不是数据集的英文翻译,而是 python 中的一个类对象。当模型进行计算时,PyTorch 的模型并不能够直接计算 numpy 数组,我们需要将 numpy 数组先转换成 Tensor,然后通过 Dataset 输入模型。详细过程的会在后面的实验中介绍。这里需要大家理解的是,这个 Dataset 类对象提供了一个方法,这个方法使得模型在进行计算时才会去加载图像。这样的设计就是为了减少内存的消耗,不需要在初始化时就将完整的数据集加载到内存中。
计算过程中的加载方法,就是通过引索来取出图像和对应的标签。
样例代码:

train_dataset 中每个元素是一个 tuple,包含一个 PIL 也就是 pillow 图像库的图像,尺寸为 512 宽 384 高 RGB3 通道,和一个对应的标签。我们可以直接使用 visualize 来可视化这个 PIL 图像。大家也可以使用 matplotlib 的方法
plt.imshow(train_dataset[index][0])
plt.show()
样例代码:
visualize(train_dataset[index][0])
运行结果:

另外我们可以通过 train_dataset.classes 的方法获得类别名称
样例代码:
print(train_dataset.classes)
运行结果:
['cardboard', 'glass', 'metal', 'paper', 'plastic', 'trash']
2 数据预处理
在项目一二中,我们会对数据进行必要的预处理过程,这个过程包括
1. 类型转换,将数据集从 uint8 转换到 float32
2. 归一化处理
3. 数据尺寸进行变换
同样,我们也需要对 train_dataset 进行这样的处理,这里我们介绍 torchvision 库中的 transforms 方法。、
样例代码
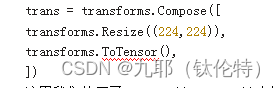
这里我们使用了 Resize((224, 224))来统一图像的尺寸,统一到 224 高 224 宽。大家可能会好奇为什么要统一到这个尺寸,其实这个尺寸并不是一个固定的值,大家也可以统一的其他的尺寸。但是需要注意模型对输入图像的尺寸要求。
ToTensor()顾名思义,将我们读取进来的图像转变成 PyTorch 模型能够计算的 Tensor,同时 ToTensor 还会同时进行类型变换,转变成 float32;和进行归一化处理,将像素值变化到[0,1]范围这两个操作。然后使用 Compose 的方法,将这两个变换结合起来。
在项目一二中我们是将数据读取进来之后,再对数据进行预处理。但是 ImageFolder 使用了不同的方法,我们先看示例代码:
样例代码:

可以看到,我们将结合好的预处理方法 trans 作为一个参数输入到了 ImageFolder 中。在上一步中我们知道 Dataset 类对象提供了一个加载方法,数据在需要时才会被真正读取进来,所以预处理的过程就被统一到了这个加载过程中。也就是说,只有在神经网络开始真正的计算时,才会加载图像,才会对加载进来的图像进行预处理。
我们可以使用函数 describe 查看这个 Tensor 的尺寸,类型和值的范围。从 Tensor 中值的范围 0 到 1 可以看到,ToTensor 确实对图像进行了归一化处理。
样例代码:
describe(train_dataset[0][0])
运行结果:
torch tensor of size torch.Size([3, 224, 224]) , dtype torch.float32 and range is [0.011764706, 0.972549].