分布式训练,DP,DDP

目录
分布式训练分为几类——
GPU训练
torch.cuda 常用方法
分布式训练分为几类:
2.更新方式:同步更新、一部更新
3.算法:parameter server 算法、AllReduce算法
(1)模型并行:不同GPU输入相同的数据,运行模型的不同部分,比如多层网络的不同层
数据并行:不同GPU输入不同的数据,运行相同的完整的模型
模型并行 数据并行
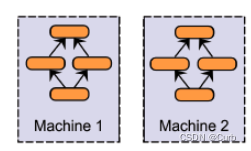
当模型非常大,一张GPU已经存不下的时候,可以使用模型并行
通常一张可以放下一个模型的时候,会采用数据并行的方式,各部分独立,伸缩性好。
(2)同步更新:每个batch所有GPU计算完成后,再统一计算新权值,然后所有GPU同步新值后,在进行下一个batch计算。(同步更新有等待,它的速度取决于最慢的那个GPU)
异步更新:每个GPU计算完梯度后,无需等待其他更新,立即更新整体权值并同步
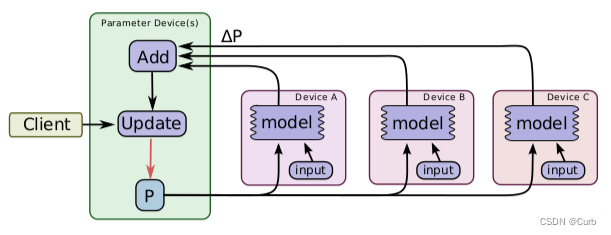
同步更新
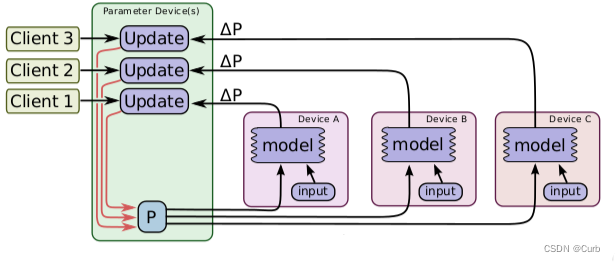
异步更新
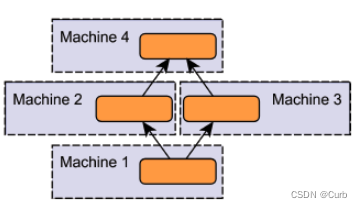
(3)Parameter Server:GPU 0将数据分成8份分到各个卡上,每张卡负责自己的那一份mini-batch的训练,得到grad后,返回给GPU 0上做累积,得到更新的权重参数后,再分发给各个卡。
缺点:通信成本大
Ring AllReduce:8张以环形相连,每张卡都有左手卡和右手卡,一个负责接收,一个负责发送,分为Scatter Reduce和All Gather两个环节。
优点:最小化网络争用的量,与GPU数量无关
GPU训练
1. 利用data.to('cpu') or data.to('cuda')实现数据的安放;to函数的对象要么是你的数据tensor或者是你的模型module
举个例子
# example1-转换数据的类型
x = torch.ones((3, 3))
x = x.to(torch.float64)# example2-把数据迁移到GPU上
x = torch.ones((3, 3))
x = x.to("cuda")# example3-转换模型的数据类型
linear = nn.Linear(2, 2)
linear.to(torch.double)# example4-把模型迁移到GPU上
gpu1 = torch.device("cuda")
linear.to(gpu1)torch.cuda 常用方法
import torch# 打印当前可见可用GPU数目
print(torch.cuda.device_count())# 获取GPU名字
print(torch.cuda.get_device_name())# 为当前GPU设置随机种子
torch.cuda.manual_seed(1)# 为所有可见可用GPU设置随机种子
torch.cuda.manual_seed_all(123)# 设置主GPU为哪一个物理GPU(不推荐)
torch.cuda.set_device(1)# 推荐 通过设置环境变量确定使用那些GPU
import os
os.environ.setdefault("CUDA_VISINLE_DEVICES","2,3")
多GPU的分发并行机制
过程:分发 ——>并行运算 ——> 结果回收。(有一个主GPU)
# 用于验证的时候,BN和dropout模式
# 模型预测阶段,我们需要将这些层设置到预测模式,model.eval()就是帮我们一键搞定的
model.eval()model.train()单机单卡:
单机多卡:DP、DDP
分布式训练 - 单机多卡(DP和DDP)
多机多卡:DDP
分布式训练 - 多机多卡 (DDP)