【Flink】Flink基础

Flink 官网地址 (官网介绍的非常详细,觉得看英文太慢的直接使用浏览器一键翻译,本文是阅读官方文档后进行的内容梳理笔记) https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/dev/python/overview/
一、Flink 做什么
- 流处理 🌰
处理无界数据,换句话说,数据输入永远不会结束 - 批处理
处理有界数据的工作范式
在 Flink 中,应用程序由流数据组成,从一个源开始,经过处理,最后再以一个接收器结束 ,下面来自 Flink 官网的一张图很好的描述了这一过程 。
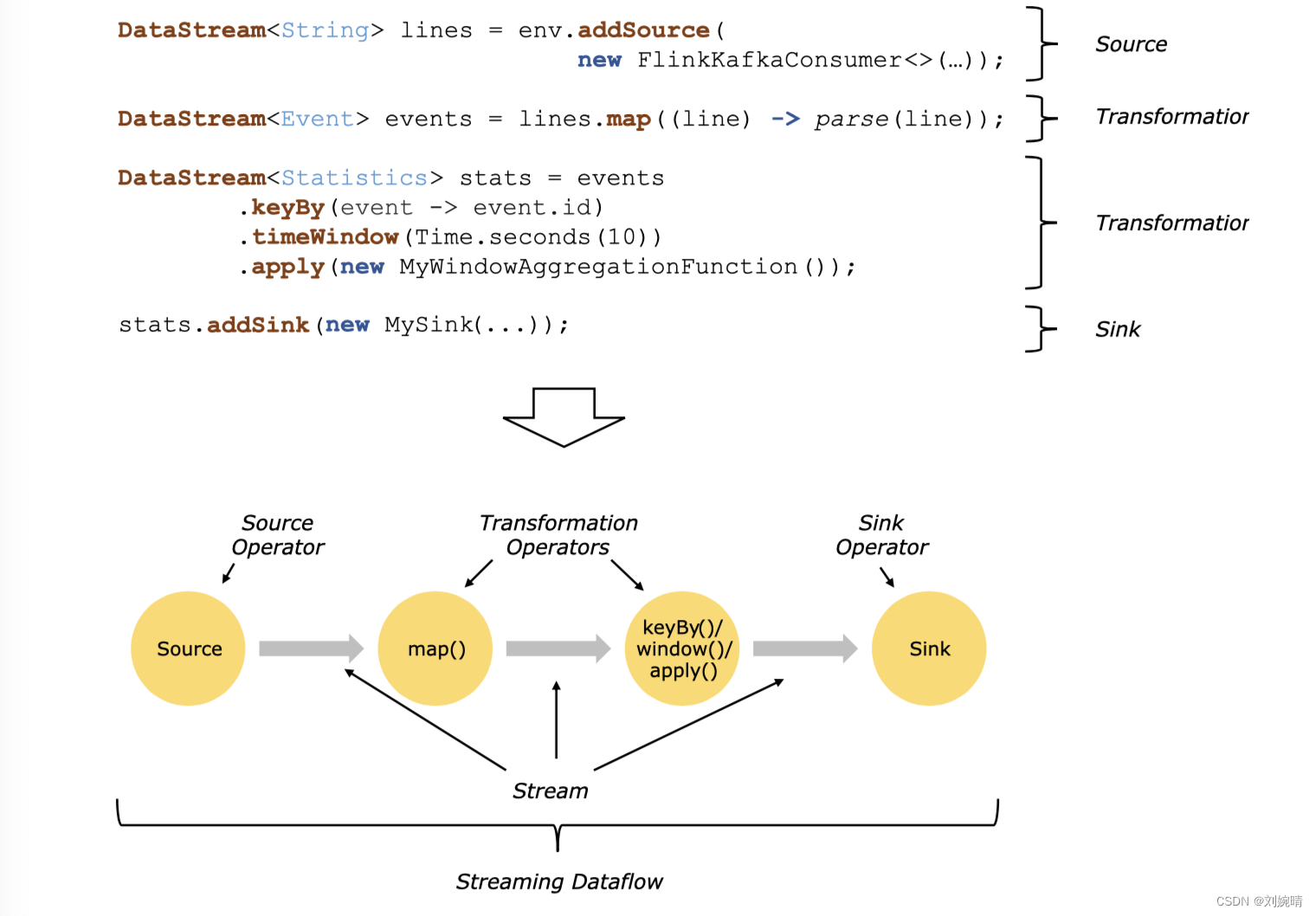
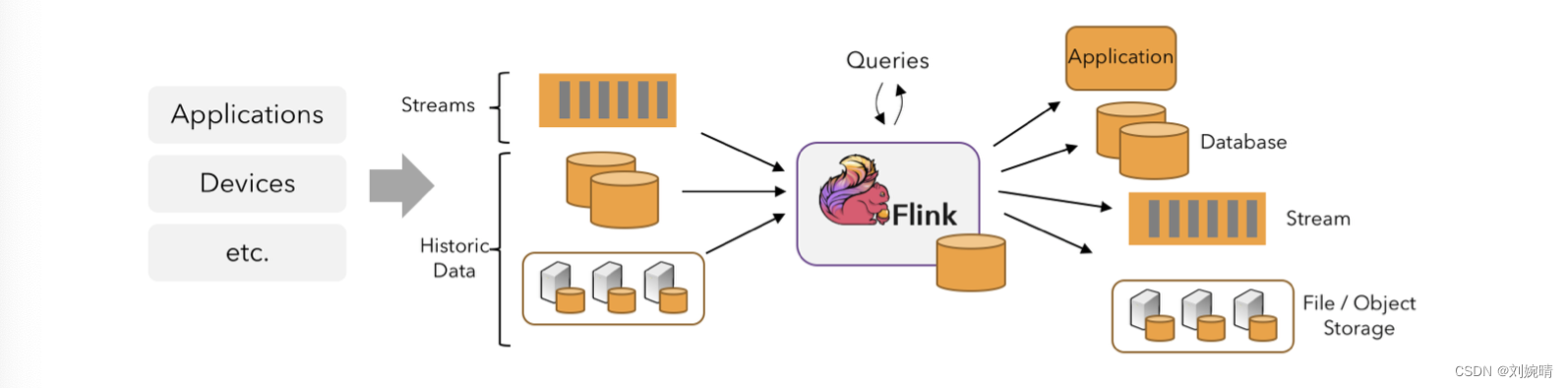
举个小栗子,Flink 应用程序消耗来自 Kafka 的实时日志数据,生成的结果流发送给其他的各种系统使用 。
二、API
流水的技术,铁一般的API调用大师~~
1. 序列化
Flink 可将基本数据类型 和 复合类型 序列化为 Flink 可流式传输的内容 。
- 基本 : 字符串、整数等等
- 复合: 元组Tuple 、 Java 类 POJO 等等
1)元组 Tuple
Flink 支持 Tuple0 到 Tuple25, 使用方式如下 :
// X 为数字, 表示定义了一个 X元组
TupleX<String, Integer, ....> person = Tuple2.of(Value1, Value2, .... , ValueX);
2)POJO
可以被 Flink 序列化的类需要满足以下条件 :
- 类公共且独立
- 有公共的无参构造函数
- 类的非静态字段要么是公共的,要么具有getter和setter方法 (遵循规范的)
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.api.common.functions.FilterFunction;public class Example {public static void main(String[] args) throws Exception {final StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();DataStream<Person> flintstones = env.fromElements(new Person("Fred", 35),new Person("Wilma", 35),new Person("Pebbles", 2));DataStream<Person> adults = flintstones.filter(new FilterFunction<Person>() {@Overridepublic boolean filter(Person person) throws Exception {return person.age >= 18;}});adults.print();env.execute();}public static class Person {public String name;public Integer age;public Person() {}public Person(String name, Integer age) {this.name = name;this.age = age;}public String toString() {return this.name.toString() + ": age " + this.age.toString();}}
}
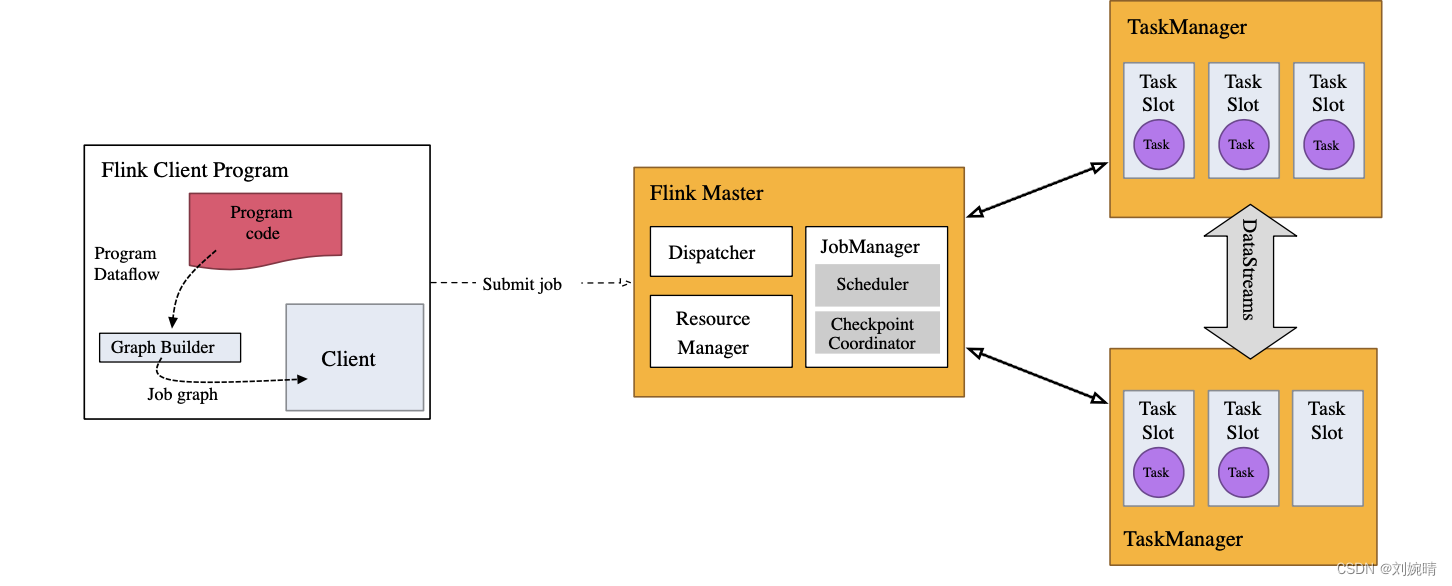
2. 流执行环境 ExecutionEnvironment
Flink 应用程序需要一个执行环境 StreamExecutionEnvironment 。 通过 execute 应用被打包发送到 JobManager 中并行执行。
3. 数据流来源 DataStream
1)用于测试
- env.fromElements
放入一些实例化的元素进去,或者直接放入一个 List, 这是一种简单的用于测试的便捷方法
List<Person> people = new ArrayList<Person>();people.add(new Person("Fred", 35));
people.add(new Person("Wilma", 35));
people.add(new Person("Pebbles", 2));DataStream<Person> flintstones = env.fromCollection(people);
- env.socketTextStream
直接传入一个套接字作为数据流的来源
DataStream<String> lines = env.socketTextStream("localhost", 9999);
- env.readTextFile
传入一个文件作为数据流的来源
DataStream<String> lines = env.readTextFile("file:///path");
2)实际应用
实际应用程序中,数据常来源于 Kafka 等消息系统
4. 接收器 Sink
- 测试环境使用 print() 打印结果到控制台
- 生产中,接收器往往是各种数据库 或者 各个子系统
5. ETL
Flink 可以帮助我们实现大数据处理中的 ETL 过程 (抽取、转换、加载)
极度类型 Java8 后提供的 Stream 函数式编程操作 ✔️
1)map & flatmap
实现类型转换的基本操作 ,map 和 flatmap 的区别如下:
- map
DataStream<TaxiRide> rides = env.addSource(new TaxiRideSource(...));
DataStream<EnrichedRide> enrichedNYCRides = rides.map(new Enrichment());
enrichedNYCRides.print();public static class Enrichment implements MapFunction<TaxiRide, EnrichedRide> {// 重写 map 方法@Overridepublic EnrichedRide map(TaxiRide taxiRide) throws Exception {return new EnrichedRide(taxiRide);}
}
- flatmap
DataStream<TaxiRide> rides = env.addSource(new TaxiRideSource(...));
DataStream<EnrichedRide> enrichedNYCRides = rides.flatMap(new NYCEnrichment());
enrichedNYCRides.print();public static class NYCEnrichment implements FlatMapFunction<TaxiRide, EnrichedRide> {// 重写 flatMap 方法,通过 Collector 发出任意数量的流元素@Overridepublic void flatMap(TaxiRide taxiRide, Collector<EnrichedRide> out) throws Exception {FilterFunction<TaxiRide> valid = new RideCleansing.NYCFilter();if (valid.filter(taxiRide)) { out.collect(new EnrichedRide(taxiRide));}}
}
2)keyBy
相当于 SQL 中的 GROUP BY