6搜索与推荐

文章目录
- init
-
- background
- summary
- Content
-
- search basic knowledge
- 大数据处理与分析
- workflow
-
- reference()
- version log()
init
background
这个部分主要介绍的就是搜索和推荐相关的内容, 这也是和工作非常相关的, 需要好好梳理一下。
summary
Content
search basic knowledge
| theme |ref | note|note|
| – | – | – | – | – | – | – |
|---|---|---|---|---|---|---|
| 主题 | 参照连接 | 备注 | 备注 | 备注 | ||
| 什么是搜索引擎? 是怎么演化的? | d | 搜索引擎主要就是通过用户的词搜索出对应匹配的全文文档。从最开始的分类开始,虽然保证了质量但是搜索出来的内容只限于自己收录的,而互联网每天产生那么多内容,这样根本不行。之后出来了检索一派的,大致就是根据自己的内容去匹配相关内容,但是质量难以保证。之后基于pagerank算法,对引用较多的网站提升排名,从而实现了质量的提升,但是不少人通过这种方式进行作弊,所以质量还是有待提升。而目前也就是第三代搜索引擎通过分析用户过去的信息,形成千人千面的搜索引擎。 | d | |||
| 搜索引擎的架构是怎样的? | 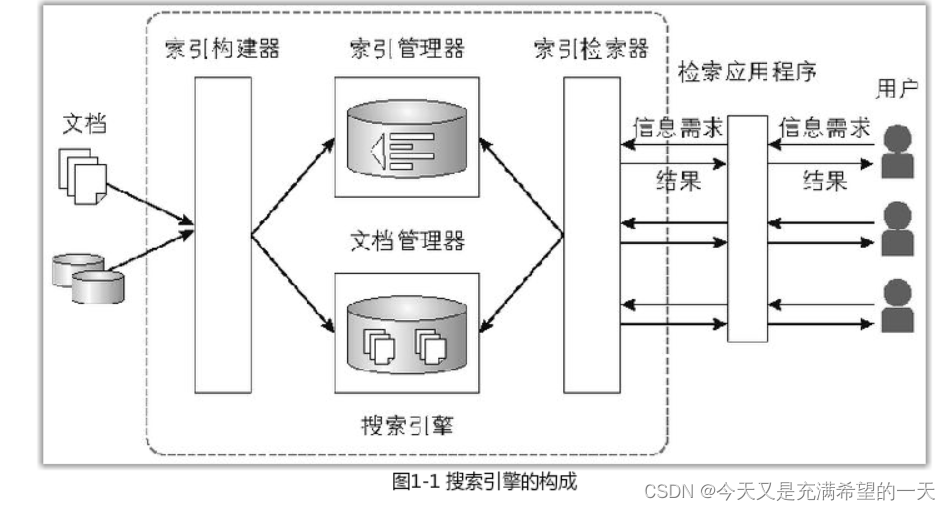 |
如图一般是四个组件, 索引检索器根据搜的词进行全文搜索,并进行排序;索引管理器是将索引这种申诉局结构管理起来; 索引构建是将文档分解成单词序列, 然后将单词序列转换成索引结构。 文档管理器就是文档编号和对应的文档数据 ; 此外还有一些爬虫和搜索排序结构。 这几个部分构成了网页搜索。 | 观点2 : 一般就是网络爬虫从网络中将数据爬到,解析相关的数据进行去重后存储,将数据内容按照倒排索引存储好,还有网络的相关性也要存储,而这些都是存储到hadoop等存储引擎上的。当用户发送请求过来,需要对查询词查询其真正的意图,然后根据用户的意图命中缓存,如果命中不了就要从排序模块中获得最相关的内容,再去存储引擎中的详情接口中去取数据。 | |||
| 索引的结构,为什么要用倒排索引? | 正排索引和倒排索引的区别 - 蝙蝠侠IT的文章 - 知乎https://zhuanlan.zhihu.com/p/141256400 | 搜索本意是全文搜索, 有两种搜索方式, 一种是grep的,适合文件少的。 一种是提前建立索引的, 适合文件多的,而这中间, 倒排索引适合小找大。 而正排索引适合大找小。 一般都是先对网页或者商品正排 出文档与关键词, 再倒排出关键词与文档。 | 索引就是提供快速搜索内容的关键字。正排索引是类似b+树,根据内容快速的检索到内容。而对于文档这种用户根据关键字进行搜索,匹配文档的需求,需要进行倒排索引也就是以关键字为核心去表示文档。例如我们几句话,用单词作为倒排索引的话:文档id、单词出现次数、和位置共同组合倒排索引而这个倒排索引所采用的具体存储结构有很多。 | 倒排索引就是索引倒过来。 | 倒排索引中有doc就是你建立倒排的单位, 有的是网页, 有的是文章, 有的是商品。 | |
| 倒排索引的原理, 怎么查找出短语? 中文的倒排索引怎么搞的? 怎么实现倒排索引? 倒排索引怎么构建的? | 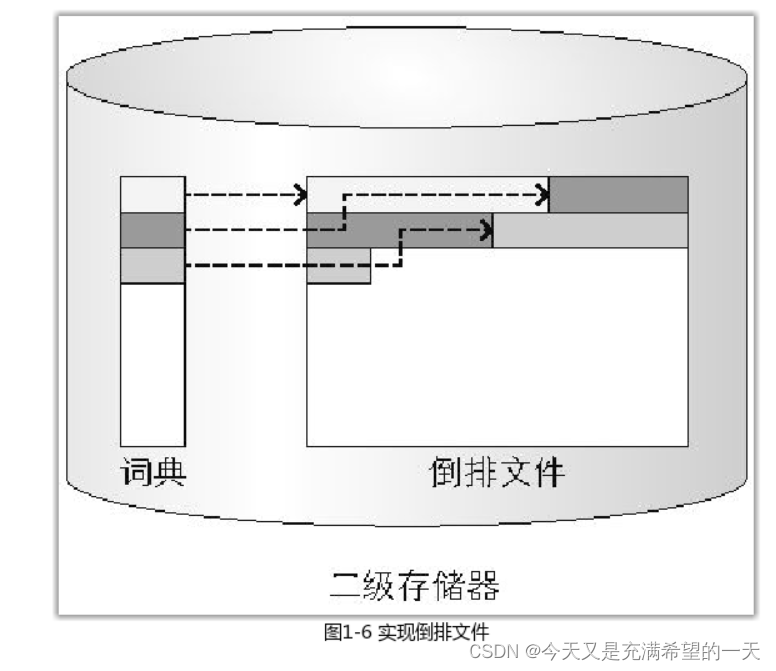 |
本质上就是词典 + 倒排索引文件。 当用户搜 短语的时候, 就将多个单词的倒排求交集, 然后漏出。 但是这样效果不好, 因为有些词要相邻出现才好。 因此现在的单词级别倒排会有单词的顺序, 在求交集的时候要保证这俩单词是相邻的。 | 中文的倒排索引因为文字是不用空格分开的, 需要对句子进行分词, 书中介绍了两种, 词素解析法(比较少, 容易漏), n-gram分割法, (比较多, 容易多出用户不想要的)。因此最好不依赖句子, 构建原则。 | 3 一般词典就是用b+树或者字典树构建了, 里面按照单词顺序排列单词, 然后数据放单词的倒排地址。 文档就是先排序, 搞成偏移量id + 词频 + 出现位置, 然后还会进行压缩。 | 单词词典就是所有文档出现的单词统计,一般词典要非常的全。一般词典存储的结构就是哈希冲突链表、b+树,倒排列表就是一个单词,后面存储单词对应文档的索引项,非常多,一般采用差值排列,可以更好的对数据进行压缩。 - 建立索引是通过好几种方式,一种是两遍文档迪历方法、第一一遍统计一个单词出现的文档数量,从而获取最终约内存大小),、第二遍统计每个文档中出现的次数,“这样最终落地到磁盘当中就是建立索的过程,此外这样做的内存占用比较大,一股还有归并的方式,此外还有一个问题就是如何建立动态索引,前面我们建立的都是静态的存储在顶盘,我们需要额外创建一个实时索引存储在内存,还有一个删除表的文档表、这样一次用户的查询过来、我们先去的索引和临时索引中合并,结果然后去删除表中过滤, 就可以做到实时的检索。 | 前面我们说了 怎么管理存储这个倒排索引。 但是怎么构建这些倒排呢? 一般分为离线和实时的,基本上就是对文档进行索引生成, 然后放到硬盘, 然后合并等。 |
| 一般怎么检索呢? 还有什么需要注意的? | 布尔检索 :需要用户提供与或非的数值,直接对文档进行匹配,但是这种只要找到内容或者找不到内容,不能得到一些分数排序,只能命中或者不命中。 - 向量空间 :主要就是将单词和文档弄成向量矩阵,然后将自己的搜索词也弄成单饲纬度的矩阵,取点积最大的。至于向量矩阵中具体特征值的权重特征值取多少有很多算法,最简单的就是词频单词在所有文档区分程度得到就是权重。 -概率模型:- 通过贝叶斯公式, BM2.5 做。 -语言模型 :- HMM等这些基础的语言检索模型。 -机器学习模型 - 像之前的概率模型和语言模型都是算法工程师精心调整的, 参数比较少, 可解释性强。 但是机器学习算法是让算法填充数据, 模型来进行学习的。 一般就是给文档设置特征和结果, 让算法进行训练。 但是这种不可控性还是有点的。 |
以bool检索为例子, 就是先对短语进行单词切分, 然后对对应的单词按照倒排长度排序, 避免交集计算复杂度。 然后计算, 然后根据过滤属性(也就是正排字段)过滤, 然后(或者可以并行进关联度排序, 只取包含一个词以上的)根据关联度排序(bm25和余弦计算等)。 | 还需要注意怎么爬取数据加入自己的索引?怎么规范数据等等。 | |||
| 构建倒排索引的流程 ? 压缩的流程 | 参照wiser代码 | 首先从文档中取出来词, 为每个词创造倒排列表并添加到内存中的倒排索引, 当到了一定程度开始合并之前的文档, 合并到数据库中。 | 对于词典数据和索引列表一般都是会进行压缩的。对于词典数据我们可以存储地址而不是具体内容,因为很多单词的大小不一致,我们只存地址,额外用一个地方单独存储数据。对于索引列表中的数据,我们可以使用一元编码加二元编码组合的方式对词频率进行压缩,因为词频率差距非常大。 | |||
| 检索的流程 | 将查询词分为词元, 加载词元的倒排索引, 从多个倒排中找到文档,计算分数返回。 | |||||
| 检索可以优化的点 | wiser代码中只是最基本的检索, 还有一些优化的地方。 1. 分词时候bgram只需要分成无重复的词元。2.禁用短语有时候速度更快 3. 排序时候可以用google page rank策略, 不简单的是tf/df. 3. 增加一个字的检索 4.压缩数据。 5. 优化索引结构 6. 加缓存加载经常搜索的索引 7.优化召回和准确率的平衡 7. 属性提前过滤 8.加入意图识别等等复杂东西。 |
大数据处理与分析
workflow
reference()
- 这就是搜索引擎
- 自制搜索引擎
- 笔记:https://editor.csdn.net/md/?articleId=127740942 读书笔记: 这就是搜索引擎
- 笔记:搜索系统入门加es中间件
- 笔记: java项目: ElasticSearch+Spark构建高相关性搜索服务&千人千面推荐系统