185-二35

Java185-二35
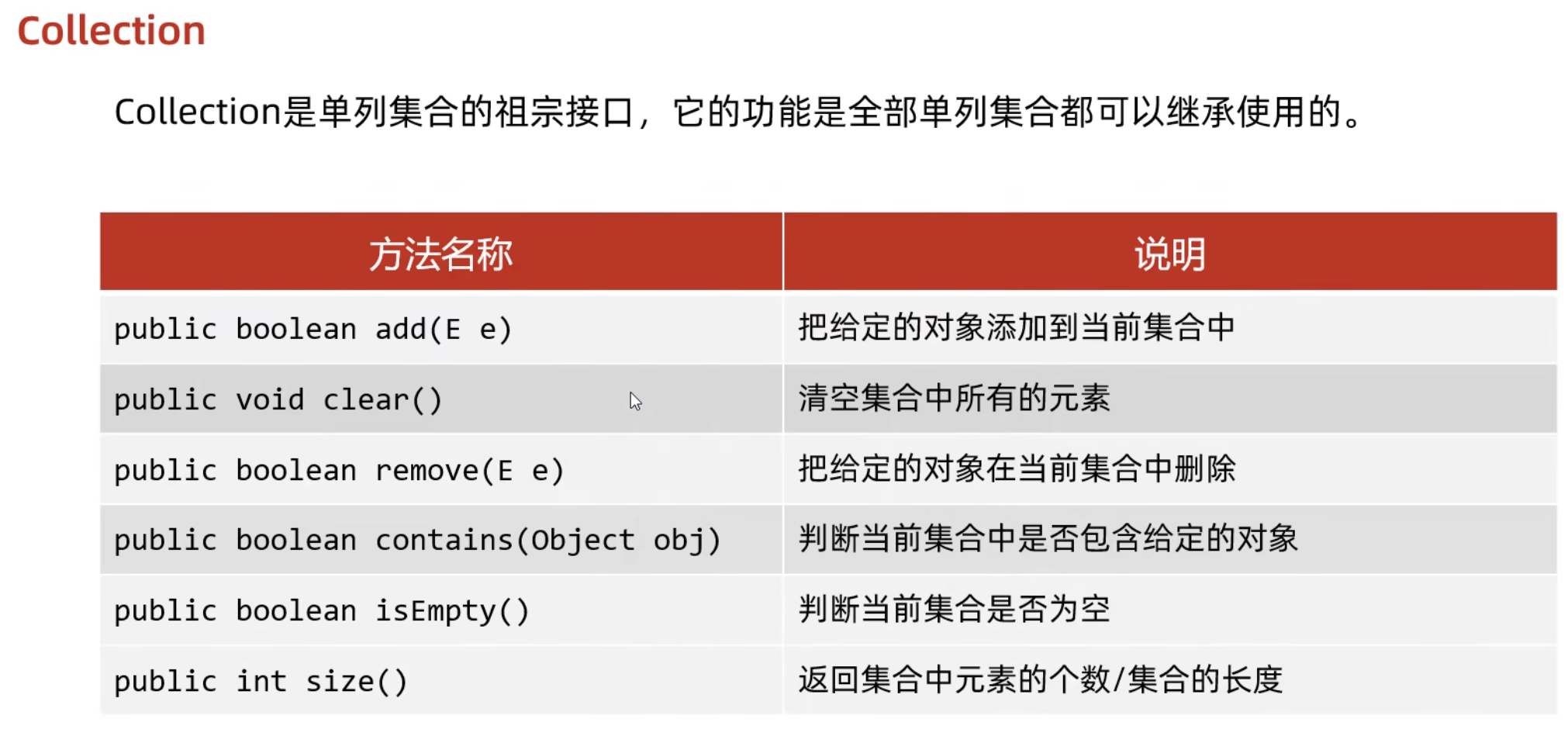
单列集合顶层接口collection
迭代器

//1.创建集合并添加元素
Collection<String> coll = new ArrayList<>();
col1.add("aaa");
col1.add("bbb");
col1.add("ccc");
col1.add("ddd");|
//2.获取迭代器对象
//迭代器就好比是一个箭头,默认指向集合的0索引处
Iterator<String> it = coll.iterator();
//3.利用循环不断的去获取集合中的每一个元素
while(it.hasNext()){
//4.next方法的两件事情:获取元素并移动指针
String str = it.next();
System.out.println(str);
}
迭代器的细节注意点:
1.报错NoSuchElementException
2.迭代器遍历完毕,指针不会复位
3.循环中只能用一次next方法
4.迭代器遍历时,不能用集合的方法进行增加或者删除
增强for
lambda表达式
//1.创建集合并添加元素
Collection<String> coll = new ArrayList<>();
coll.add("zhangsan");
coll.add("lisi");
co11.add("wangwu");
//2.利用匿名内部类的形式
/底层原理:
/其实也会自己遍历集合,依次得到每一个元素
//把得到的每一个元素,传递给下面的accept方法
//s依次表示集合中的每一个数据
/* col1.forEach(new Consumer<String>(){
@Override
public void accept(String s){
System.out.println(s);
3
});*/
//lambda表达式
coll.forEach(s -> System.out.println(s));
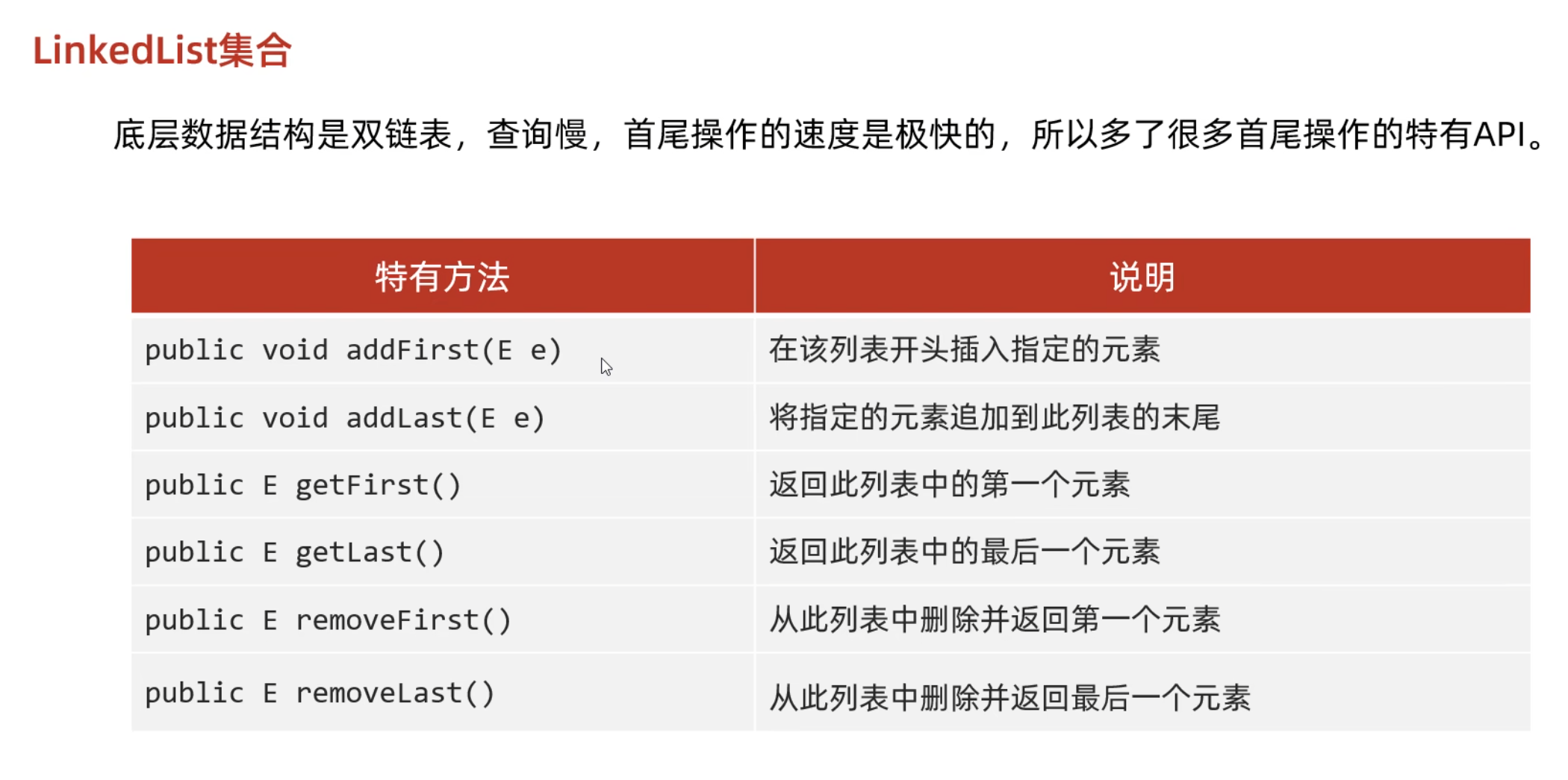
list特有方法

遍历
//1.迭代器
/*Iterator<String> it = list.iterator();
while(it.hasNext()){
String str = it.next();
System.out.println(str);
}*/
//2.增强for
//下面的变量s,其实就是一个第三方的变量而已。
/在循环的过程中,依次表示集合中的每一个元素
/* for (String s : list) {
System.out.println(s);
}*/
//3.Lambda表达式
//forEach方法的底层其实就是一个循环遍历,依次得到集合中的每一个元素
//并把每一个元素传递给下面的accept方法
//accept方法的形参s,依次表示集合中的每一个元素
//list.forEach(s->System.out.println(s) );
//4.普通for循环
//size方法跟get方法还有循环结合的方式,利用索引获取到集合中的每一个元素
/*for (int i = 0; i < list.size(); i++) {
//i:依次表示集合中的每一个索引
String s = list.get(i);
System.out.println(s);
}*///5.列表迭代器
//获取一个列表迭代器的对象,里面的指针默认也是指向e索引的
//额外添加了一个方法:在遍历的过程中,可以添加元素
ListIterator<String> it = list.listIterator();
while(it.hasNext()){
String str = it.next();
if("bbb".equals(str)){
//qqq
it.add("qqq");System.out.println(list);
}
}
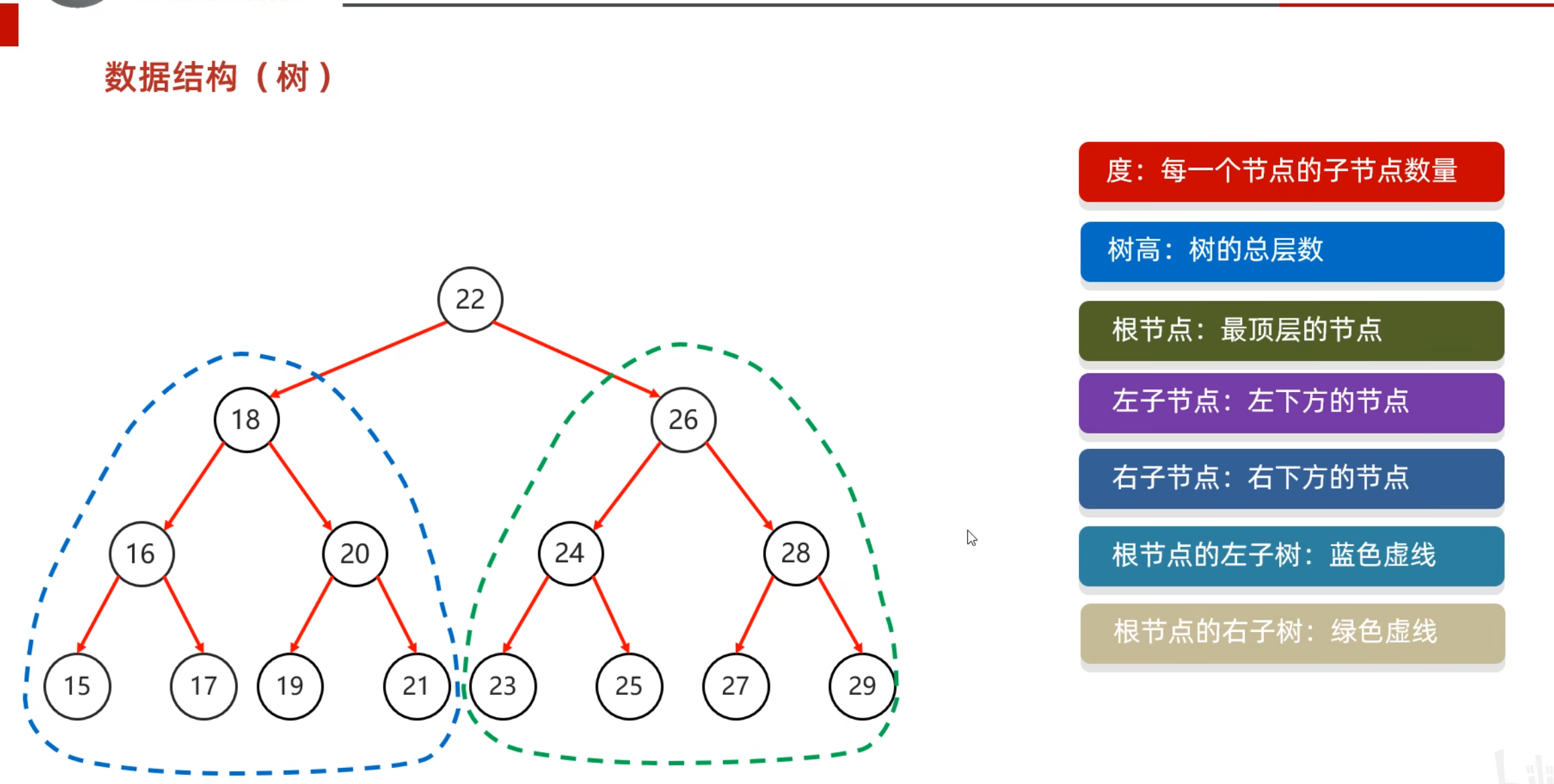
数据结构
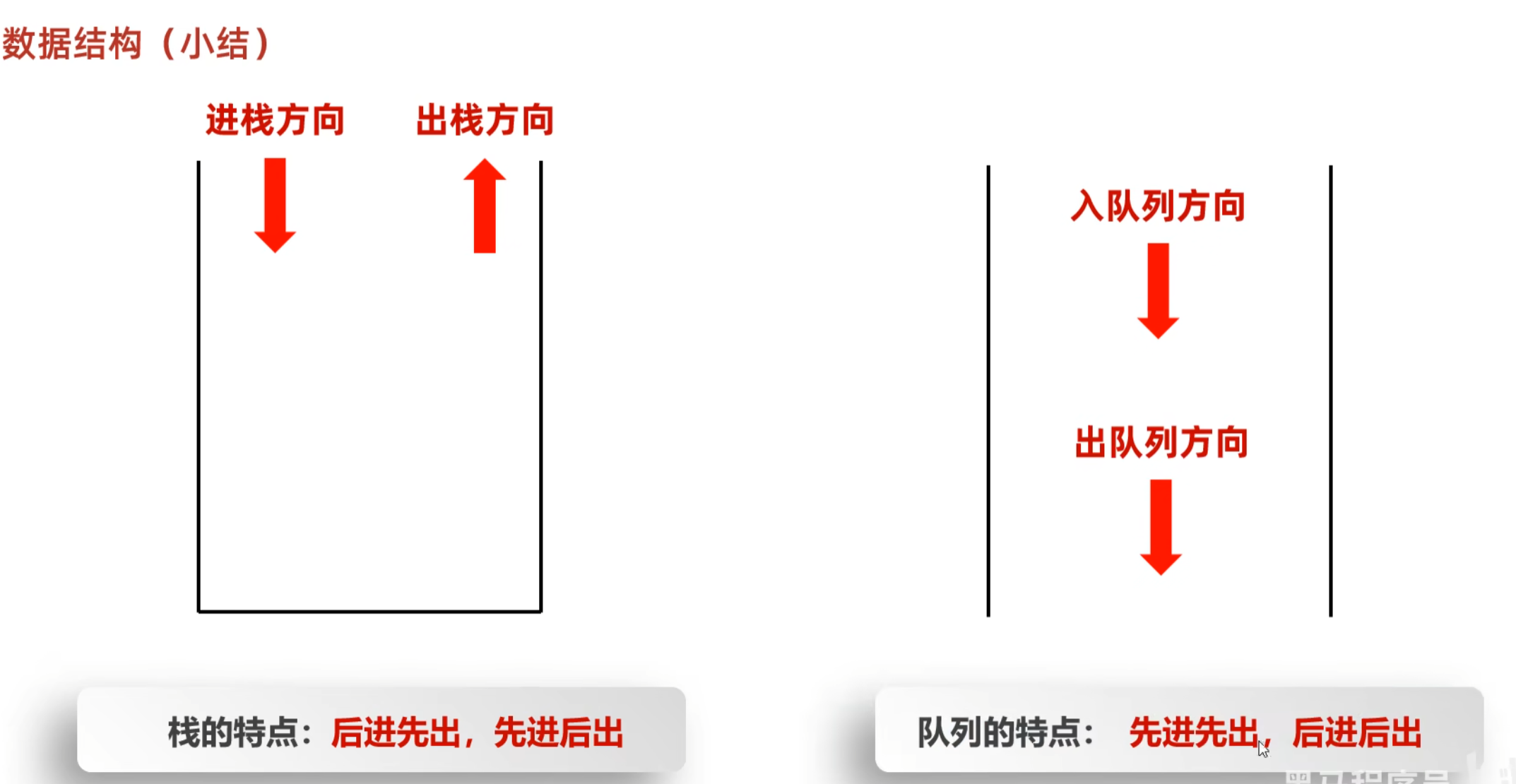
数组
查询快,增删慢
Linkedlist集合
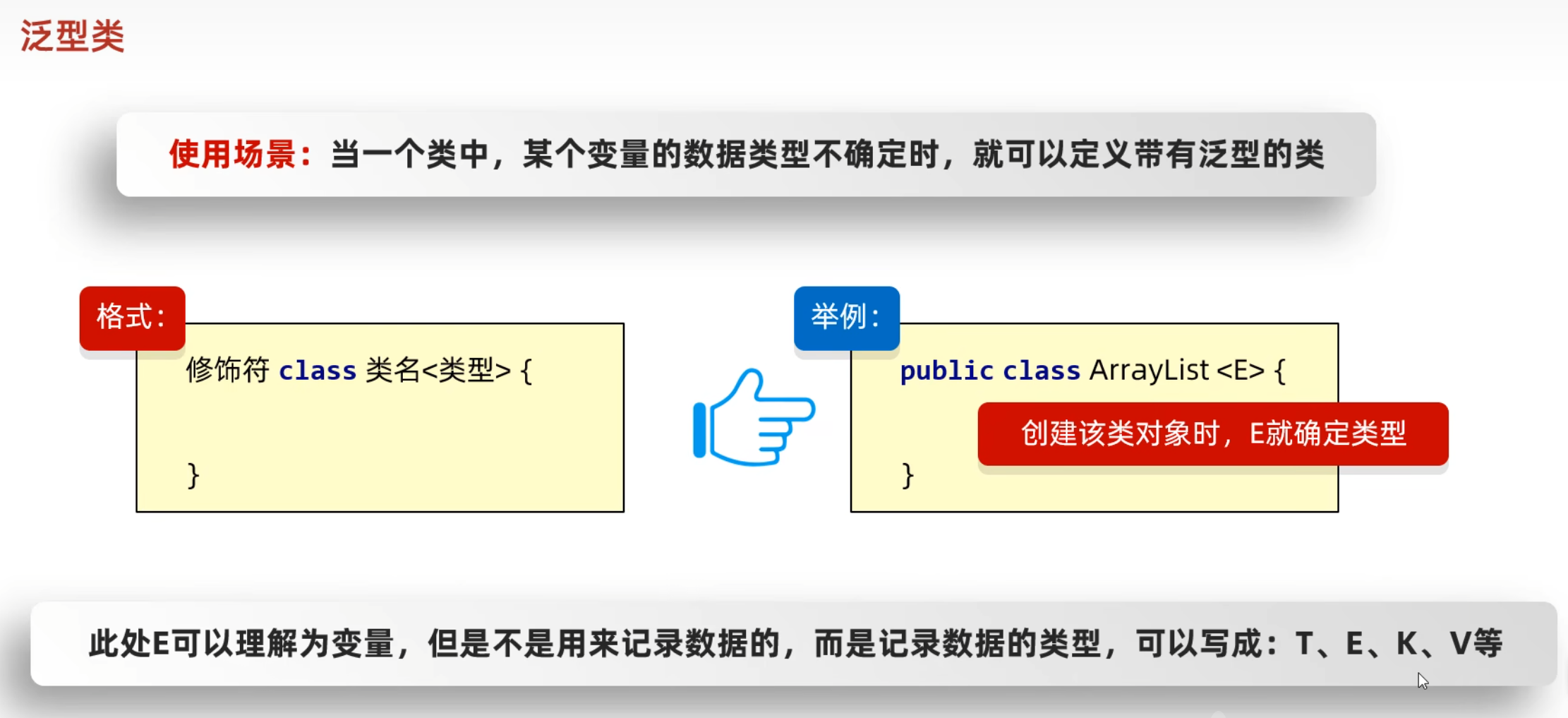
泛型类,泛型方法,泛型结构
//没有泛型的时候,集合如何存储数据
//1.创建集合的对象
ArrayList list = new ArrayList();
//2.添加数据
list.add(123);
list.add("aaa");|
list.add(new Student( name: "zhangsan", age: 123));
//3.遍历集合获取里面的每一个元素
Iterator it = list.iterator();
while(it.hasNext()){
String str = (String) it.next();
/多态的弊端是不能访问子类的特有功能
//obj.length();
str.length();
System.out.println(str);
}
泛型的细节
泛型中不能写基本数据类型
指定泛型的具体类型后,传递数据时,可以传入该类类型或者其子类类型
如果不写泛型,类型默认是Object
public class MyArrayList<E> {
0bject[] obj = new Object[10];
int size;
/*
E:表示是不确定的类型。该类型在类名后面已经定义过了。
e:形参的名字,变量名
/
public boolean add(E e){
obj[size] = e;
size++;
return true;
}
public E get(int index) { return (E)obj[index]; }
@Override
public String toString() {
return Arrays.tostring(obj);
}
}
泛型方法
方法中形参类型不确定时
方案①:使用类名后面定义的泛型 所有方法都能用
方案②:在方法申明上定义自己的泛型 只有本方法能用

泛型的通配符
此时,泛型里面写的是什么类型,那么只能传递什么类型的数据。
弊端:
A
利用泛型方法有一个小弊端,此时他可以接受任意的数据类型
Ye Fu Zi
Student
希望:本方法虽然不确定类型,但是以后我希望只能传递Ye Fu Zi
此时我们就可以使用泛型的通配符:
?也表示不确定的类型
他可以进行类型的限定
?extends E:表示可以传递E或者E所有的子类类型
?super E:表示可以传递E或者E所有的父类类型
应用场景:
1.如果我们在定义类、方法、接口的时候,如果类型不确定,就可以定义泛型类、泛型方法、泛型接口。
2.如果类型不确定,但是能知道以后只能传递某个继承体系中的,就可以泛型的通配符
泛型的通配符:
关键点:可以限定类型的范围。
public static void method(ArrayList<? super Fu> list) {
}
泛型总结
1.什么是泛型?
JDK5引入的特性,可以在编译阶段约束操作的数据类型,并进行检查
2.泛型的好处?
统一数据类型
把运行时期的问题提前到了编译期间,避免了强制
类型转换可能出现的异常,因为在编译阶段类型就能确定下来。
3.泛型的细节?
泛型中不能写基本数据类型
指定泛型的具体类型后,传递数据时,可以传入该类型和他的子类类型
如果不写泛型,类型默认是object
4.哪里定义泛型?
泛型类:在类名后面定义泛型,创建该类对象的时候,确定类型
泛型方法:在修饰符后面定义方法,调用该方法的时候,确定类型
泛型接口:在接口名后面定义泛型,实现类确定类型,实现类延续泛型
5.泛型的继承和通配符
泛型不具备继承性,但是数据具备继承性
泛型的通配符:?
? extend E
? super E
6.使用场景
定义类、方法、接口的时候,如果类型不确定,就可以定义泛型
如果类型不确定,但是能知道是哪个继承体系中的,可以使用泛型的通配符
数据结构
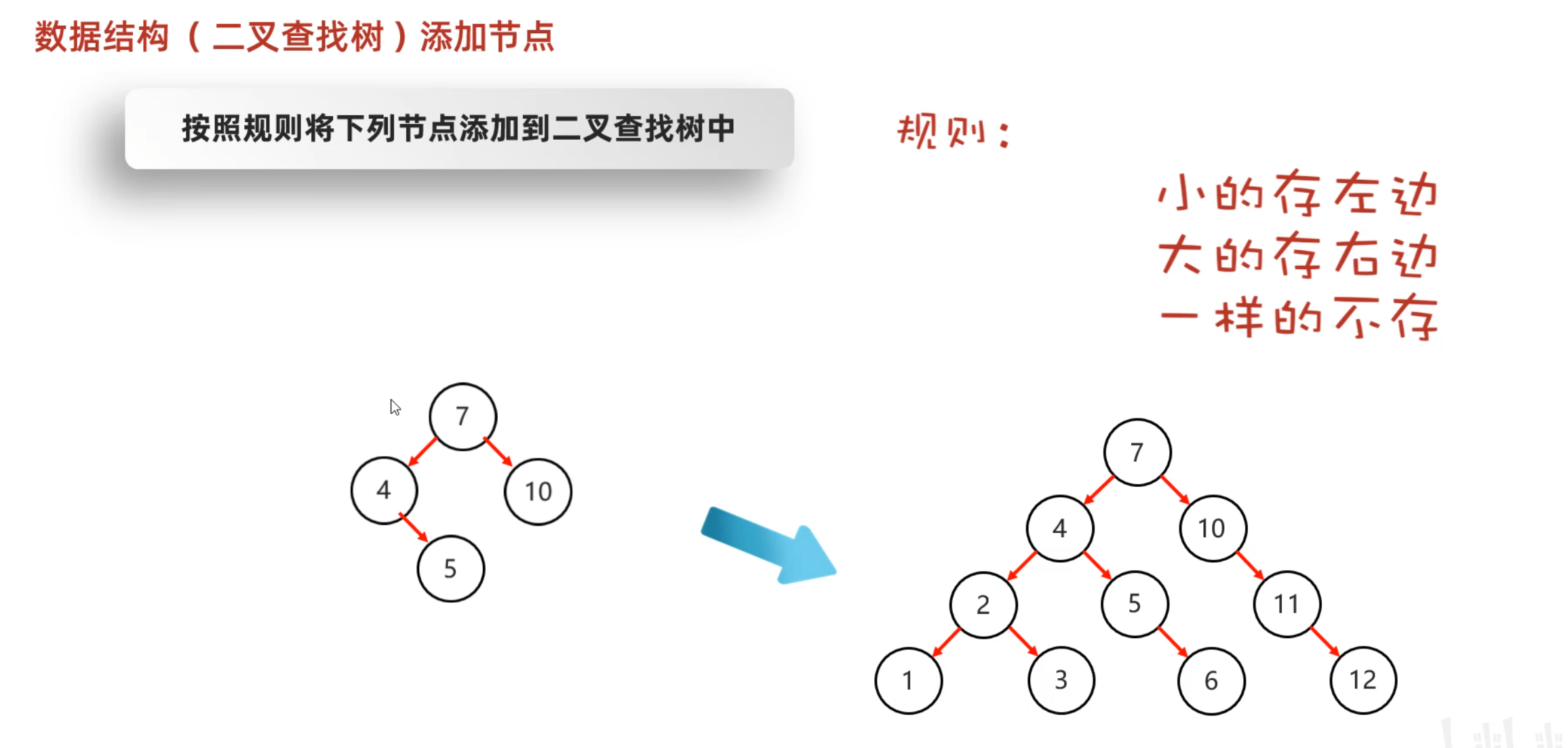
数据结构(二叉树)前序遍历
从根结点开始,然后按照当前结点,左子结点,右子结点的顺序遍历
数据结构(二叉树)中序遍历
从最左边的子节点开始,然后按照左子结点,当前结点,右子结点的顺序遍历
数据结构(二叉树)后序遍历
从最左边的子节点开始,然后按照左子结点,右子结点,当前结点的顺序遍历
平衡二叉树:任意节点左右子树高度差不超过1

红黑树
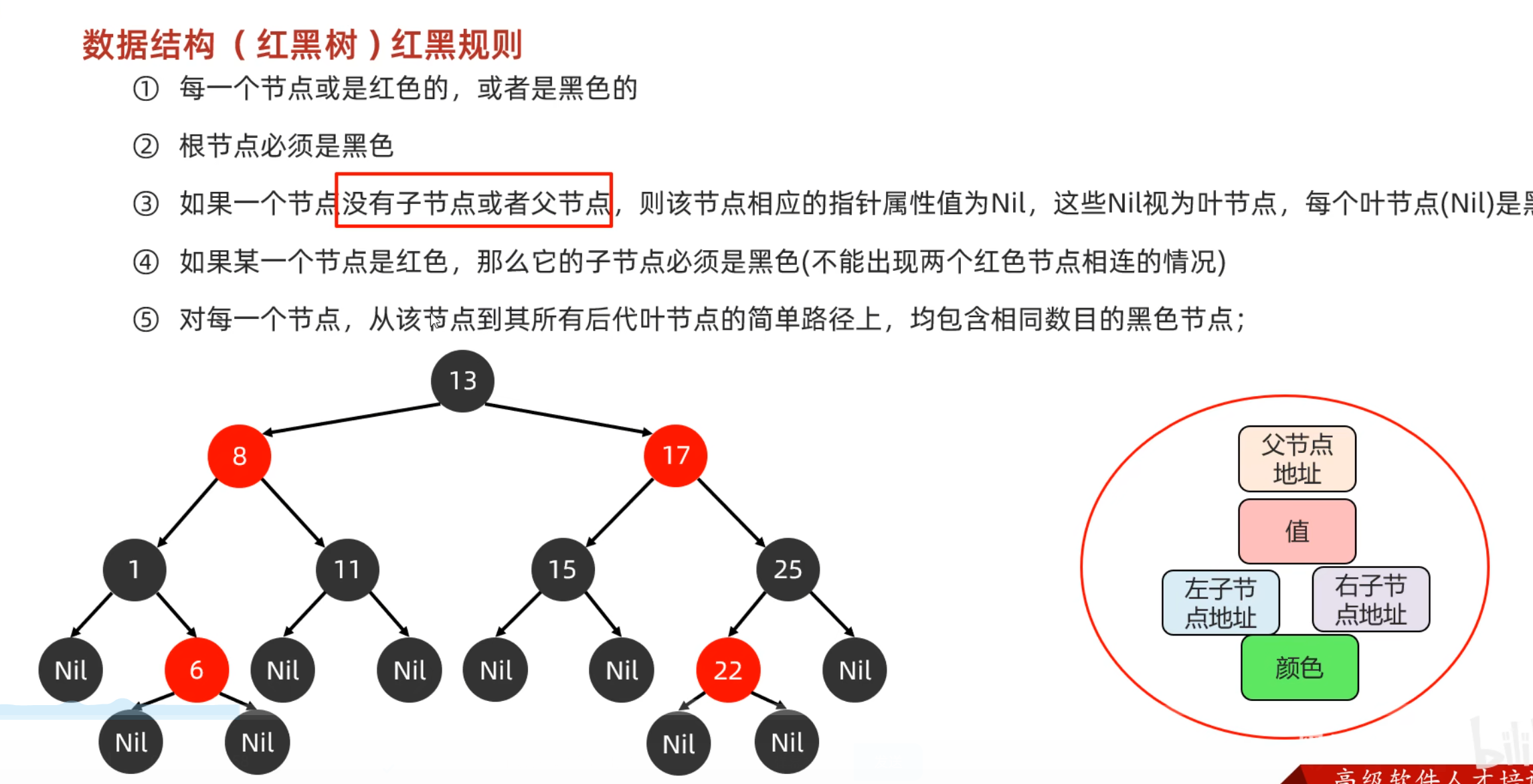
集合进阶
Map集合

//1.创建Map集合的对象
Map<String, String> m = new HashMap<>();
//2.添加元素
//put方法的细节:
/∥添加/覆盖
//在添加数据的时候,如果键不存在,那么直接把键值对对象添加到map集合当中,方法返回nu11
//在添加数据的时候,如果键是存在的,那么会把原有的键值对对象覆盖,会把被覆盖的值进行返回。
String value1=m.put("郭靖","黄蓉");
System.out.println(value1);
m.put(“韦小宝“,“沐剑屏“);
m.put(“尹志平“,“小龙女“);
String value2=m.put("韦小宝","双儿");
System.out.println(value2);
//3.打印集合
System.out.println(m);//???

MAP集合遍历
//三个课堂练习:
//
//练习一:
利用键找值的方式遍历map集合,要求:装着键的单列集合使用增强for的形式进行遍历
利用键找值的方式遍历map集合,要求:装着键的单列集合使用迭代器的形式进行遍历
//练习二:
//练习三:
利用键找值的方式遍历map集合,要求:装着键的单列集合使用1ambda表达式的形式进行遍历
1
//1.创建Map集合的对象
Map<String,String> map = new HashMap<>();
//2.添加元素
map.put("尹志平","小龙女");
map.put("郭靖",“穆念慈");
map.put("欧阳克","黄蓉");
//3.通过键找值
//3.1获取所有的键,把这些键放到一个单列集合当中
Set<String> keys = map.keySet();
//3.2遍历单列集合,得到每一个键
for(String key :keys){
//System.out.println(key);
//3.3利用map集合中的键获取对应的值 get
String value = map.get(key);
System.out.println(key + " =" + value);
3
第二种遍历
/1.创建Map集合的对象
Map<String,String> map = new HashMap<>();
//2.添加元素
//键:人物的外号
∥/值:人物的名字
map.put("标枪选手",“马超");
map.put("人物挂件","明世隐");
map.put("御龙骑士",“尹志平");
//3.Map集合的第二种遍历方式
/通过键值对对象进行遍历
//3.1通过一个方法获取所有的键值对对象,返回一个Set集合
Set<Map.Entry<String, String>> entries = map.entrySet();
//3.2遍历entries这个集合,去得到里面的每一个键值对对象
for (Map.Entry<String, String> entry : entries) {//entry --->
}
“人物挂件”,”明世隐”
//3.3利用entry调用get方法获取键和值
String key = entry.getkey();
String value = entry.getValue();
System.out.println(key + "=" + value);
}
第三种lambda表达式

//3.利用lambda表达式进行遍历
∥/底层:
//forEach其实就是利用第二种方式进行遍历,依次得到每一个键和值
//再调用accept方法
map.forEach(new BiConsumer<String, String>() {
@Override
public void accept(String key, String value) {
System.out.println(key + "=" + value);
3
});
System.out.println(".
");
map.forEach((String key, String value)->{
System.out.println(key + "=" + value);
3
);
System.out.println(".
");
I
map.forEach((key, value)-> System.out.println(key + "=" + value));
HashMap
HashMap的特点
①HashMap是Map里面的一个实现类。
②没有额外需要学习的特有方法,直接使用Map里面的方法就可以了。
③特点都是由键决定的:无序、不重复、无索引
④ HashMap跟HashSet底层原理是一模一样的,都是哈希表结构
LinkedHashMap

TreeMap
TreeMap跟TreeSet底层原理一样,都是红黑树结构的。
由键决定特性:不重复、无索引、可排序
可排序:对键进行排序。
注意:默认按照键的从小到大进行排序,也可以自己规定键的排序规则
代码书写两种排序规则
·实现Comparable接口,指定比较规则。
创建集合时传递Comparator比较器对象,
指定比较规则。
@0verride
public int compareTo(Student o) {
//按照学生年龄的升序排列,年龄一样按照姓名的字母排列,同姓名年龄视为同一个人。
//this:表示当前要添加的元素
//o:表示已经在红黑树中存在的元素
//返回值:
//负数:表示当前要添加的元素是小的,存左边
//正数:表示当前要添加的元素是大的,存右边
//0:表示当前要添加的元素已经存在,舍弃
int i = this.getAge() - o.getAge();
i = i == e? this.getName().compareTo(o.getName()) : i;
return i;|
}
}
/*需求:
字符串“aababcabcdabcde”
请统计字符串中每一个字符出现的次数,并按照以下格式输出
输出结果:
a (5) b (4) c (3) d (2) e (1)
新的统计思想:利用map集合进行统计
如果题目中没有要求对结果进行排序,默认使用HashMap
如果题目中要求对结果进行排序,请使用TreeMap
键:表示要统计的内容
值:表示次数
*///1.定义字符串
String s = "aababcabcdabcde";
//2.创建集合
TreeMap<Character,Integer> tm = new TreeMap<>();
//3.遍历字符串得到里面的每一个字符
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
//拿着c到集合中判断是否存在
/存在,表示当前字符又出现了一次
//不存在,表示当前字符是第一次出现
if(tm.containsKey(c)){
//存在
//先把已经出现的次数拿出来
int count = tm.get(c);
//当前字符又出现了一次
count++;
//把自增之后的结果再添加到集合当中
tm.put(c,count);
}else{
∥/不存在
tm.put(c,1);
}
}
//4.遍历集合,并按照指定的格式进行拼接
// a (5) b (4) c (3) d (2) e (1)
StringBuilder sb = new StringBuilder();
tm.forEach(new BiConsumer<Character,Integer>(){
@Override
public void accept(Character key, Integer value) {
sb.append(key).append("(").append(value).append(")");
}
});
System.out.println(sb);可变参数
JDK5
可变参数
方法形参的个数是可以发生变化的,e123...
格式:属性类型...名字
int...args
可变参数的小细节:
1.在方法的形参中最多只能写一个可变参数
可变参数,理解为一个大胖子,有多少吃多少
2.在方法的形参当中,如果出了可变参数以外,还有其他的形参,那么可变参数要写在最后
集合工具类Collections

带有概率的随机点名
//1.创建集合
ArrayList<Integer> list = new ArrayList<>();
//2.添加数据
Collections.addAll(list, ...elements: 1,1,1,1,1,1,1);
Collections.addAll(list, ...elements: 0,0,0);//3.打乱集合中的数据
Collections.shuffle(list);
//4.从1ist集合中随机抽取e或者1
Random r = new Random();
int index = r.nextInt(list.size());
int number = list.get(index);
System.out.println(number);
//5.创建两个集合分别存储男生和女生的名字
ArrayList<String> boyList = new ArrayList<>();
ArrayList<String> girlList = new ArrayList<>();
Collections.addALl(boyList,….elements:"范闲",“范建","范统",“杜子腾","宋合泛","侯笼藤","朱益群","朱穆朗玛峰");
Collections.addALL(girlList,…elements:"杜琦燕","袁明媛","李猜","田蜜蜜");
//6.判断此时是从boyList里面抽取还是从girlList里面抽取
if(number == 1){
//boyList
int boyIndex = r.nextInt(boyList.size());
String name = boyList.get(boyIndex);
System.out.println(name);
}else{
//girlList
int girlIndex = r.nextInt(girlList.size());
String name = girlList.get(girlIndex);
System.out.println(name);
}
shift+f6快捷更改
不可变集合

创建Map的不可变集合
细节1:
键是不能重复的
细节2:
Map里面的of方法,参数是有上限的,最多只能传递20个参数,10个键值对
//1.创建一个普通的Map集合
HashMap<String, String> hm = new HashMap<>();
hm.put("张三",“南京");
hm.put(“李四",“北京");
hm.put("王五","上海");
hm.put("赵六","北京");
hm.put(“孙七“,“深圳“);
hm.put("周八","杭州");
hm.put("吴九","宁波");
hm.put("郑十","苏州");
hm.put(“刘一",“无锡“);
hm.put(“陈二",“嘉兴“);
hm.put("aaa","111");
//2.利用上面的数据来获取一个不可变的集合
//获取到所有的键值对对象(Entry对象)
Set<Map.Entry<String, String>> entries = hm.entrySet();
//把entries变成一个数组
Map.Entry[] arr =new Map.Entry[20];|
//toArray方法在底层会比较集合的长度跟数组的长度两者的大小
//如果集合的长度>数组的长度:数据在数组中放不下,此时会根据实际数据的个数,重新创建数组
//如果集合的长度<=数组的长度:数据在数组中放的下,此时不会创建新的数组,而是直接用