聚类标签选定

动作标签选定
动作标签对错误图有辅助提高精确度的作用,通过提取caption的动词然后统计个数
以下代码就是对训练集和测试集的数据进行action的动作的选取,我将统计好的每个动作统计个数
#导入数据
import json
# 数据路径
path = "./captionwithid_train(64115).json"
# 读取文件数据
with open(path, "r") as f:row_data = json.load(f)
# 读取每一条json数据
for d in row_data:print(d)desktop_path = "./" # 新创建的txt文件的存放路径
full_path = desktop_path + 'count_66' + '.txt'
file = open(full_path, 'w')
# file.close(),关闭文档#将action内容写进count_v.txt文件中
for i in range(len(row_data)):try:file.write(row_data[i]['action']+' ') except :i+=1
file.close()
#统计各个动词的个数
# -*- coding: utf-8 -*-
test = open('./count_66.txt')
# 利用open()函数将txt文件中的内容导入到txt列表中.
words_td = []for word in test:words_td.append((word.strip()).split(' '))
# split()函数将单词以空格为界切割
# print(words_td) # 打印二维列表words_od = []
for i in range(len(words_td)):for j in range(len(words_td[i])):words_od.append(words_td[i][j])
print(f'test文件中的所有单词:\\n{words_od}')
# 二位列表转一维列表# 将一维列表中的单词去重 set()去重函数
diff_words = list(set(words_od))
print(diff_words)counts = [] # 创建统计单词个数列表
for c in range(len(diff_words)):counts.append(0)
print(counts)
for w_o in range(len(words_od)):for d_w in range(len(diff_words)):if diff_words[d_w] == words_od[w_o]:counts[d_w] = counts[d_w] + 1
print(f'{diff_words}\\n{counts}')
# 输出统计结果# for i in range(len(diff_words)):
# for j in range(len(counts)):
# if i == j:
# print(f'count_v.txt文件中有单词{diff_words[i]}:{counts[j]}个')
# # {f'内容{输出内容}'}这种写法相当于{'内容'.format(输出内容)}
# break#将输出的文件写到excel文件中
import pandas as pd
count_x=pd.DataFrame({'veb':diff_words[1:],'count':counts[1:]})#排序并输出为excel
count_xx=(count_x.sort_values(by='count',ascending=False))
#count_xx.to_excel("./count_v6.xlsx")
#print(f'count_v.txt文件中共有{sum(counts)}个单词。')
输出

排序:
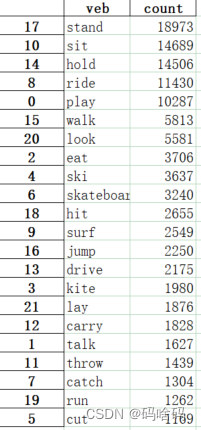
从以上从输出结合动词本身的特性来看(例如look,这个动词没有为之后的聚类预测提供有效的信息;ski,滑雪的动作会有动作的提示,进而对管节点的位置有一定预判作用),统计了以上单词,
选定:‘drive’,‘jump’,‘surf’,‘skateboard’,‘ski’,‘walk’,‘play’,‘ride’,‘hold’,‘sit’,'stand’作为动作标签。
选好的参与模型的动作标签后就对将动作标签赋值到元数据的json文件中
#提取标签,给图片新的label
#标签列,加一个标志位用于判断数组是否遍历完
l=['drive','jump','surf','skateboard','ski','walk','play','ride','hold','sit','stand','flag']#读入数据
with open("captionwithid_val(2693).json", "r", encoding="utf-8") as f:content = json.load(f)#对标签的更改
for i in range(len(content)):try:for v in l:if(v in content[i]['action']):if(v in ['surf','skateboard','ski']):content[i]['action'] = "ski"else:content[i]['action'] = vbreakif(v=='flag') : content[i]['action']="others"except:content[i]['action']="others"#保存为json文件
json_file_path = 'new_captionwithid_val(2693).json'
json_file = open(json_file_path, mode='w')
json.dump(content, json_file, indent=4)
json_file.close()
# json.dump(save_json_content, json_file, ensure_ascii=False, indent=4) # 保存中文
选定好的动作标签标注到coco数据集中的annotations中