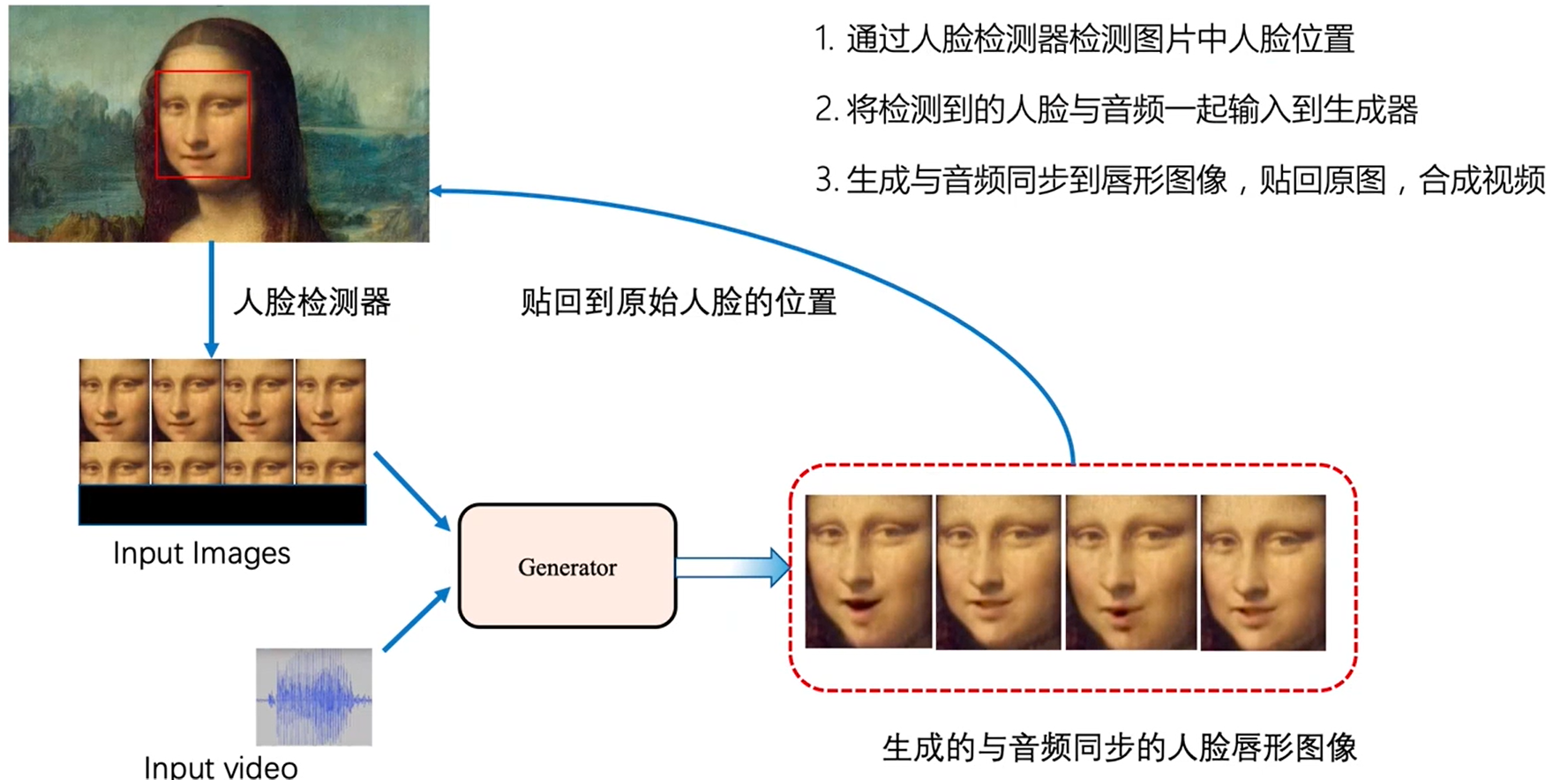
wav2lip:Accurately Lip-syncing Videos In The Wild

飞桨AI Studio - 人工智能学习与实训社区集开放数据、开源算法、免费算力三位一体,为开发者提供高效学习和开发环境、高价值高奖金竞赛项目,支撑高校老师轻松实现AI教学,并助力开发者学习交流,加速落地AI业务场景 https://aistudio.baidu.com/aistudio/education/group/info/16651
https://aistudio.baidu.com/aistudio/education/group/info/16651
wav2lip,主要是通过音频以及和音频同步的图片以及不同步的图片作为输入,构造了encoder-deocder结构,其中损失模块包括了三个部分,第一是重建损失,第二是同步损失,其中提前预训练了一个同步模型,第三增加了gan架构,用来提升生成的质量。但是wav2lip开源版本不够高清,生成出来的唇形仍然比较模糊,有两种做法,一个是训练高清版本的,另一个就是接fpgan这种增强的方式,但是后者速度很慢。
1.安装
python37 cuda 10.1
sudo yum install libsndfile
pip install -r requirements
在face_detection/detection/sfd/sfd_detector.py中把s3fd.pth的路径换一下就好。
2.推理
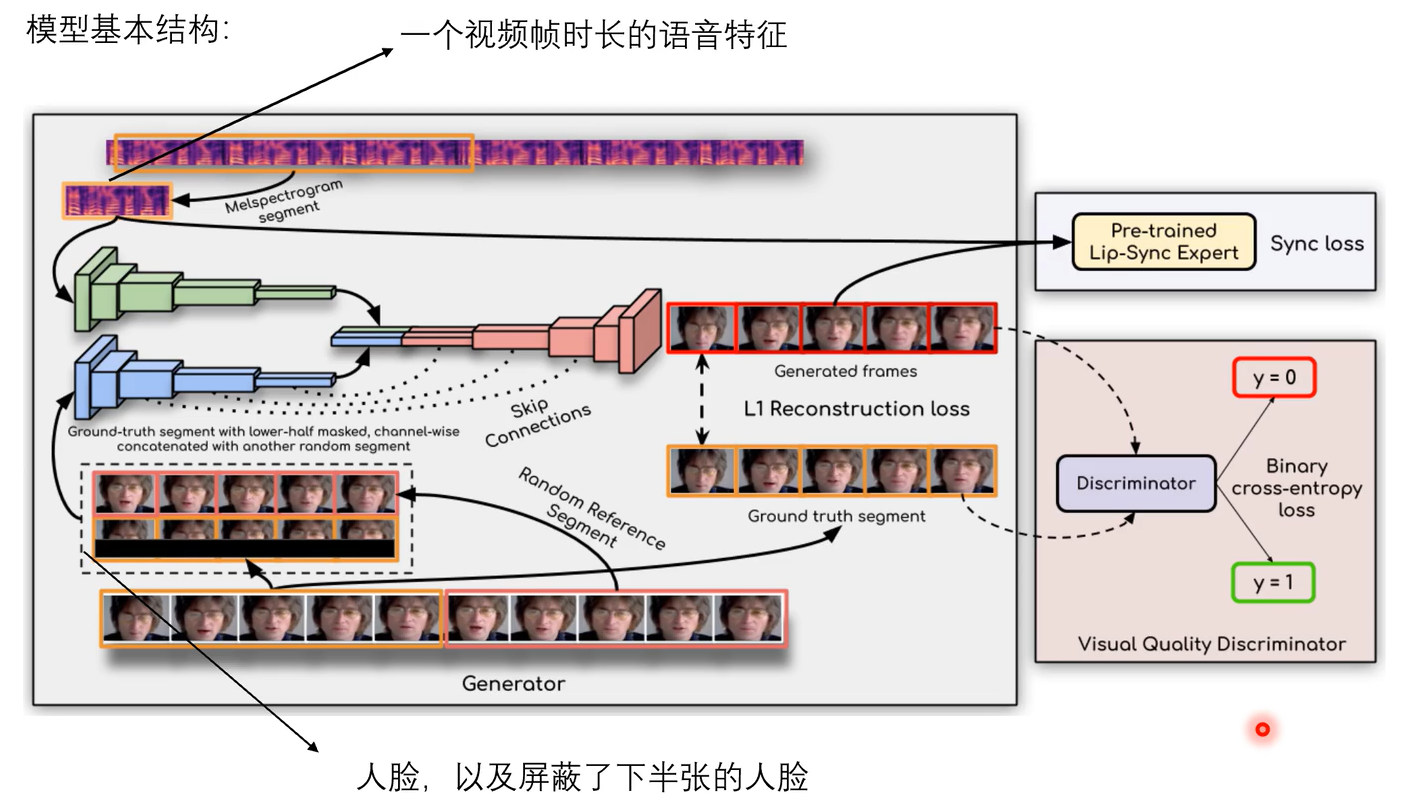
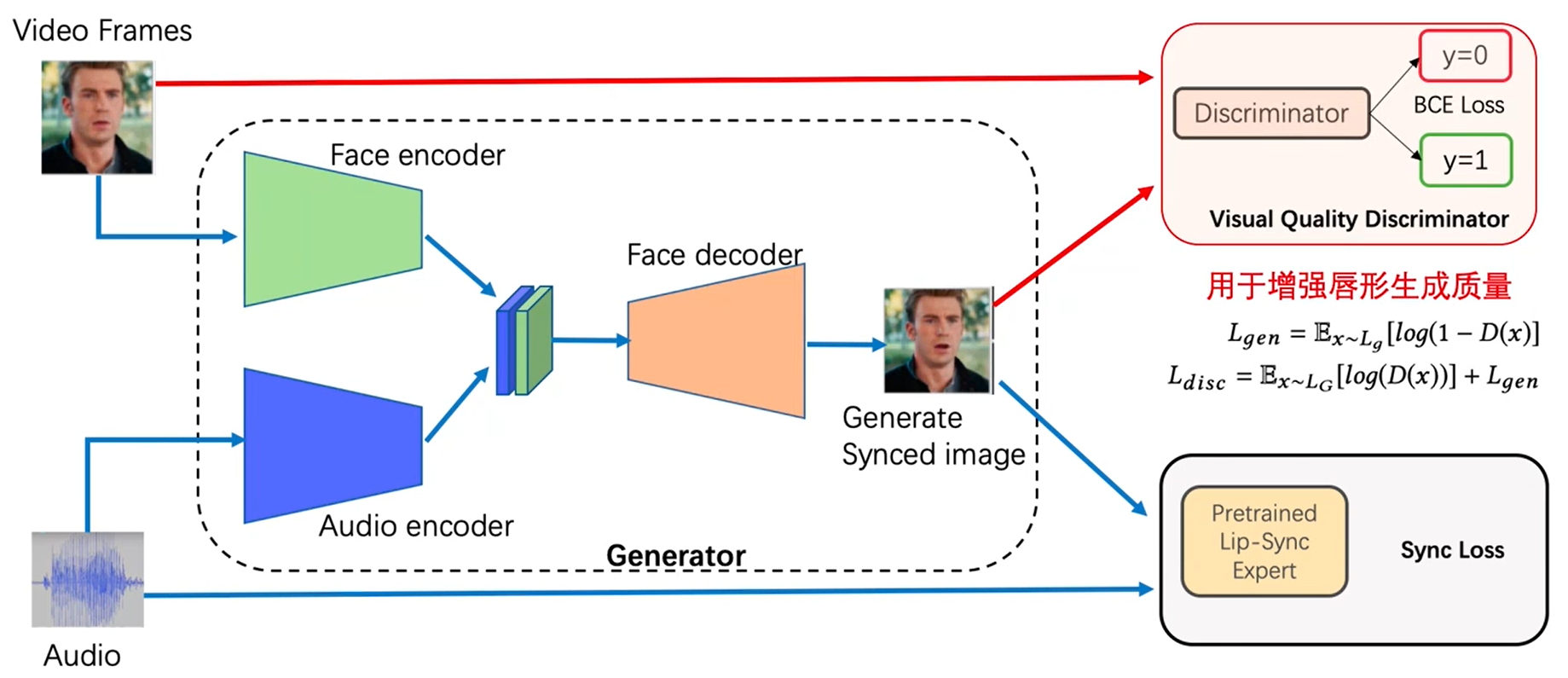
实际上还是一个跨模态的模型,输入是一段音频特征和图像对,其中音频特征以及处理成mel频谱,这也是很常见音频处理,图像特征是一段长视频进行随机的切割,产生的两段,其中第一段橙色和第二段粉色的,将两段图像进行拼接之后,将橙色段的唇形部位全部mask掉,输入一个encoder和decode的结构,在解码时,产生了音频对应的唇形图,将唇形图和gt进行loss计算,gt即是被mask掉的橙色块,这里输入mask橙色块的时候拼了粉色块,我觉得主要还是让模型只学习唇形这一块,因为是基于gan的模型,不然很容易学飞了,粉色图片序列其实就是减少模型的复杂度,给了一块先验,要学的只是mask掉区域。

原作者开源出来的不是高清版本的,人脸是96x96的。
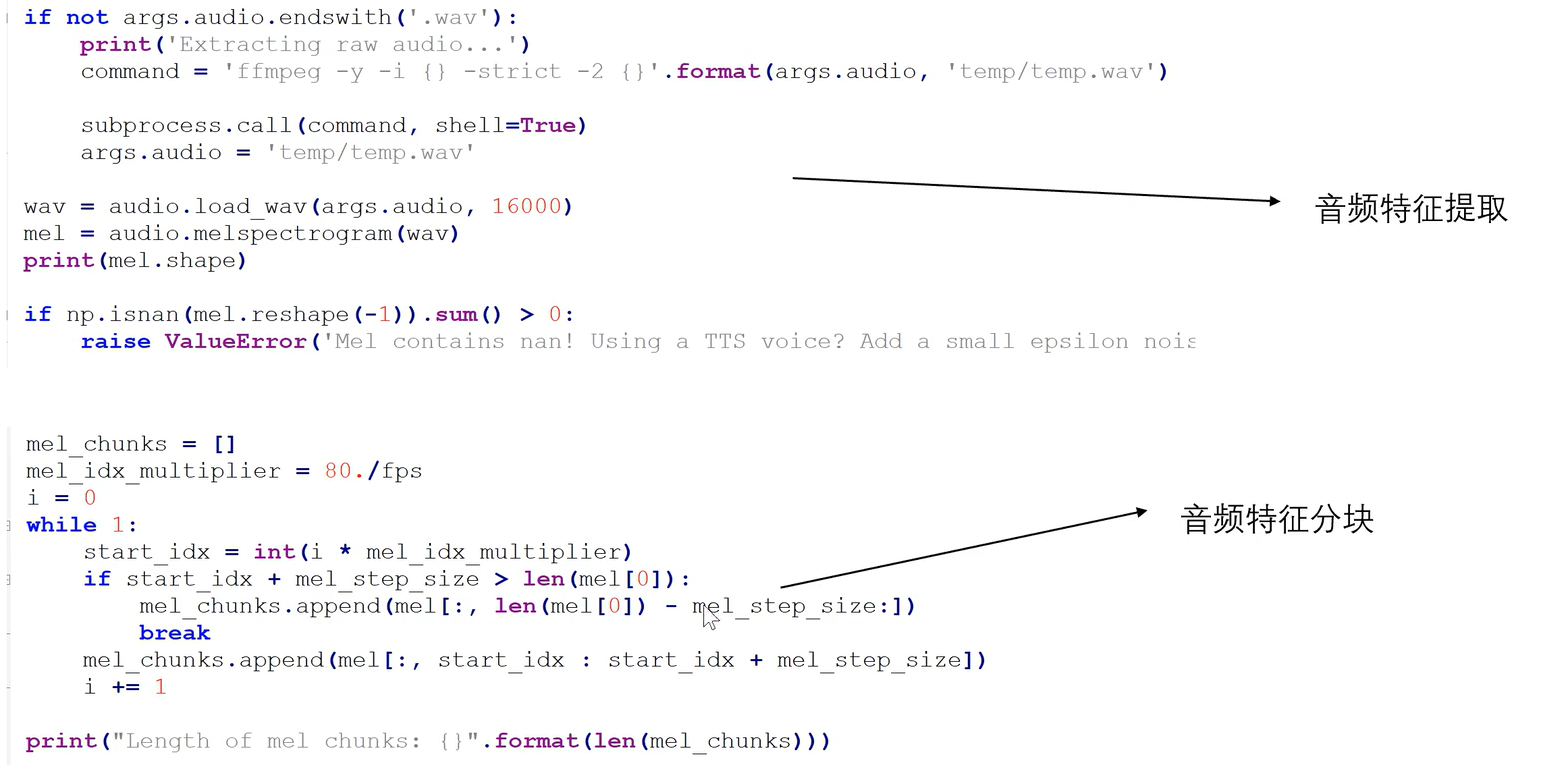
音频每块是16,一个视频对应的音频,偏移量是80/fps,fps=25,每次偏移大概3。

3.训练
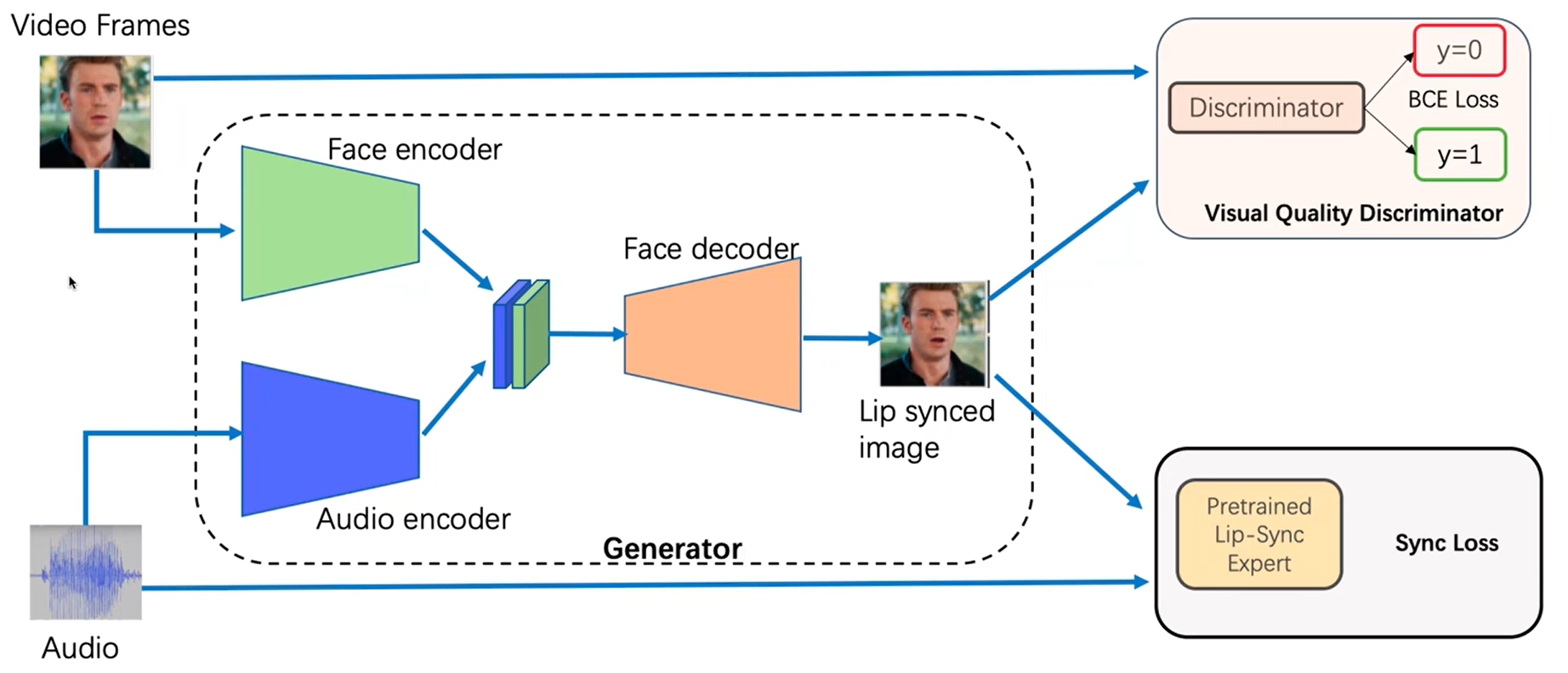 音频和视频同步判断器要提前训练好,即右下角模块,右上角是标准的gan结构,不用gan结构就是l2损失。
音频和视频同步判断器要提前训练好,即右下角模块,右上角是标准的gan结构,不用gan结构就是l2损失。
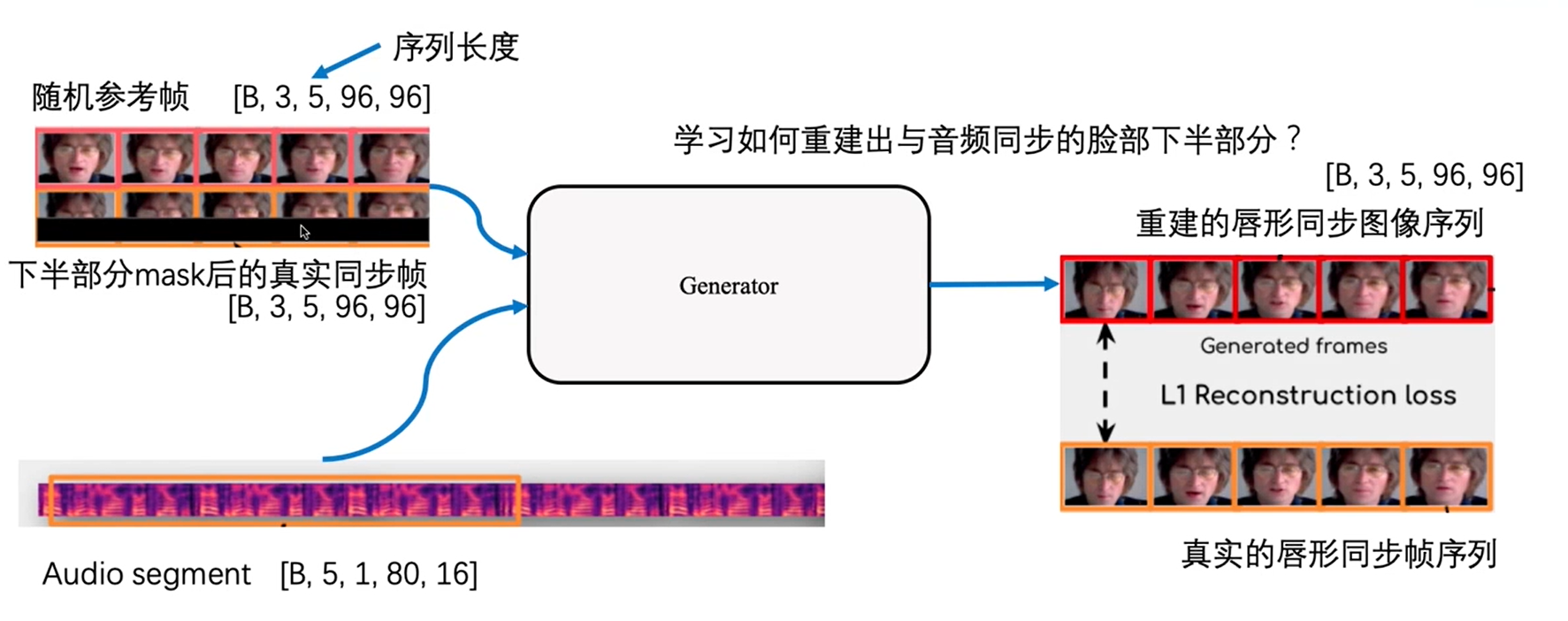
随机帧是和音频不同步,是根据音频和mask的图形生成真实的唇形,参考帧的意义我自己感觉是减少模型复杂度,但是也有解释,在前向推理时,其实输入的一定是和音频不同步的视频帧,此时不仅对唇形区域做mask,也会把原始的图像拼接起来concat,这样其实训练和推理时就保持一致了。上面的loss是重建损失,后面还有同步损失。
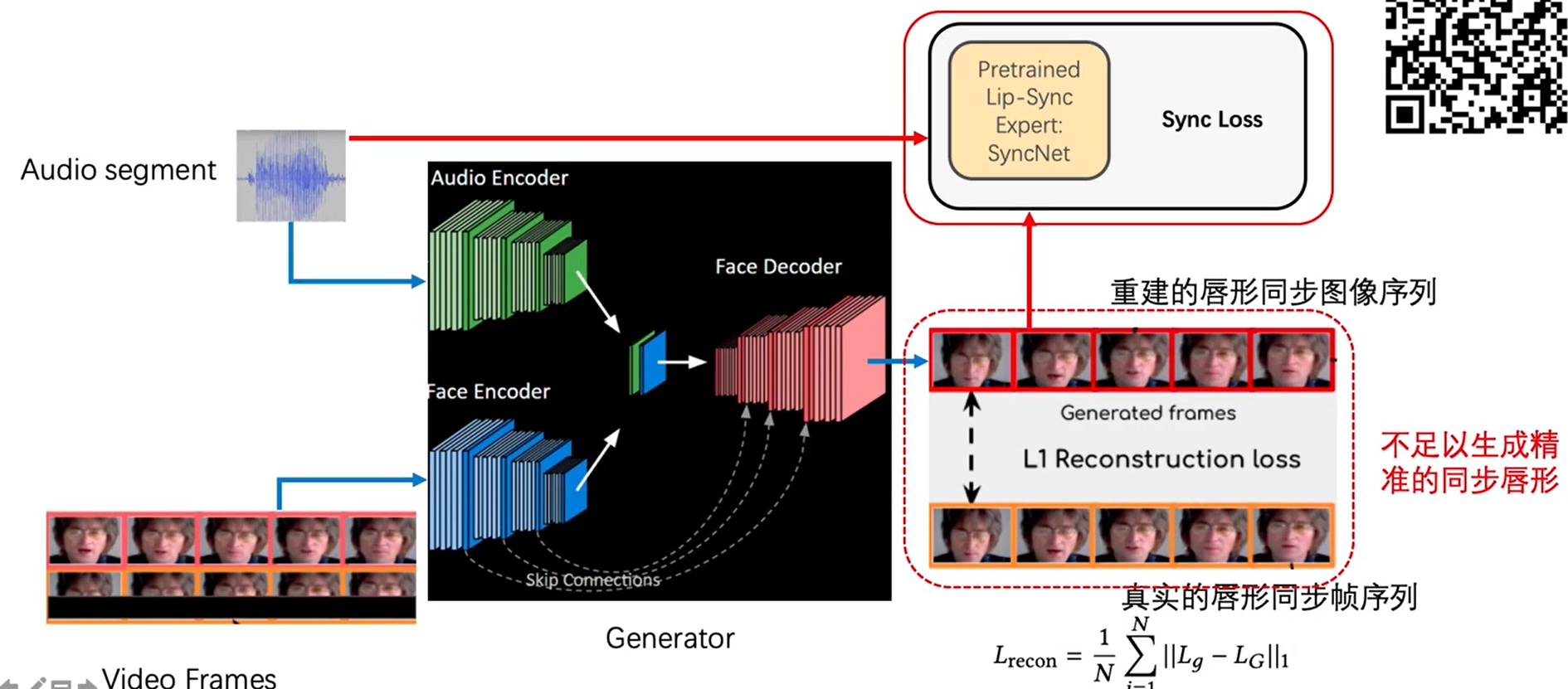
l1主要是重建损失,虽然生成了唇形,但是不足以保证同步,提前训练好一个sync判别器。 下面是syncnet网络。
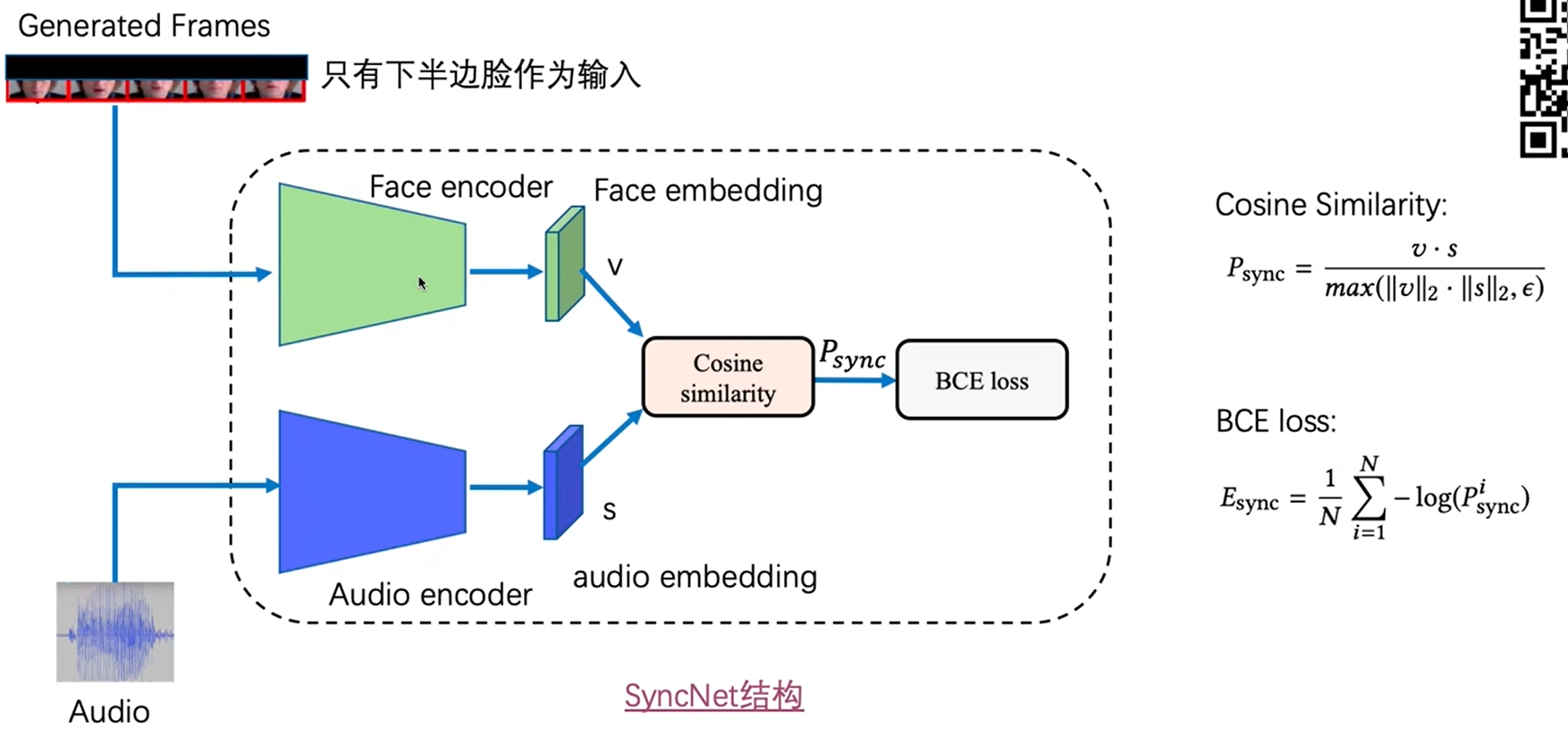
上面两部分主要考虑的是唇形生成和同步的监督,但是还要考虑唇形生成质量问题,为了提升质量,在生成器后面加了一个gan结构,主要是判别器。
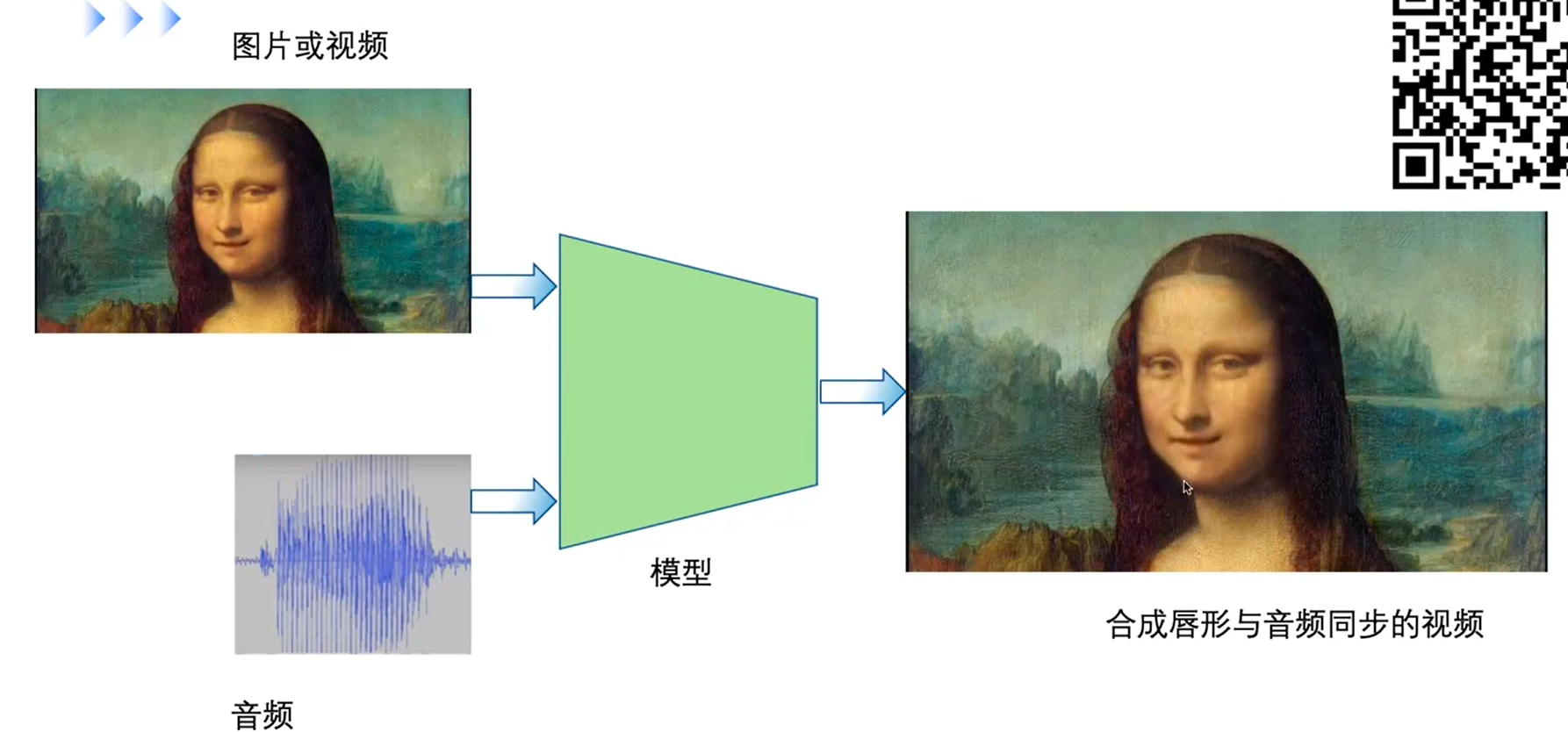
预测: