Java初识泛型


目录
一、包装类
1、基本数据类型和对应的包装类
2、装箱和拆箱
3、自动装箱和自动拆箱
二、什么是泛型
三、引出泛型
1、泛型的语法
四、泛型类的使用
1、语法
2、示例
3、类型推导(Type Inference)
六、泛型如何编译的
1、擦除机制
2、为什么不能实例化泛型类型数组
七、泛型的上界
1、语法
2、示例
八、泛型方法
1、定义语法
2、示例
一、包装类
1、基本数据类型和对应的包装类
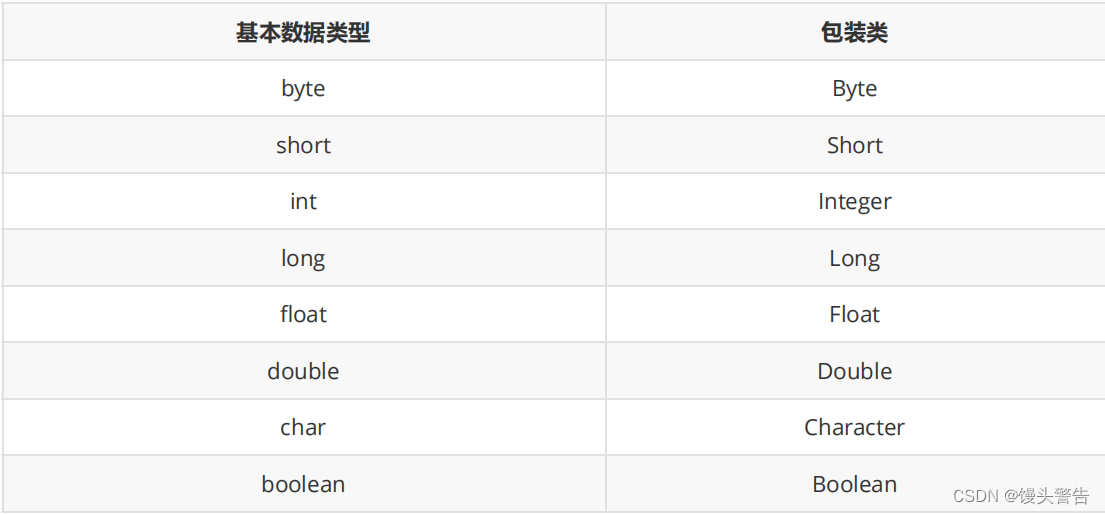
除了 Integer 和 Character, 其余基本类型的包装类都是首字母大写。
2、装箱和拆箱
简单的说,装箱就是:自动将基本数据类型转换为包装器类型;拆箱就是:自动将包装器类型转换为基本数据类型。
int i = 10;
// 装箱操作,新建一个 Integer 类型对象,将 i 的值放入对象的某个属性中
Integer ii = Integer.valueOf(i);
Integer ij = new Integer(i);
// 拆箱操作,将 Integer 对象中的值取出,放到一个基本数据类型中
int j = ii.intValue();3、自动装箱和自动拆箱
int i = 10;
Integer ii = i; // 自动装箱
Integer ij = (Integer)i; // 自动装箱
int j = ii; // 自动拆箱
int k = (int)ii; // 自动拆箱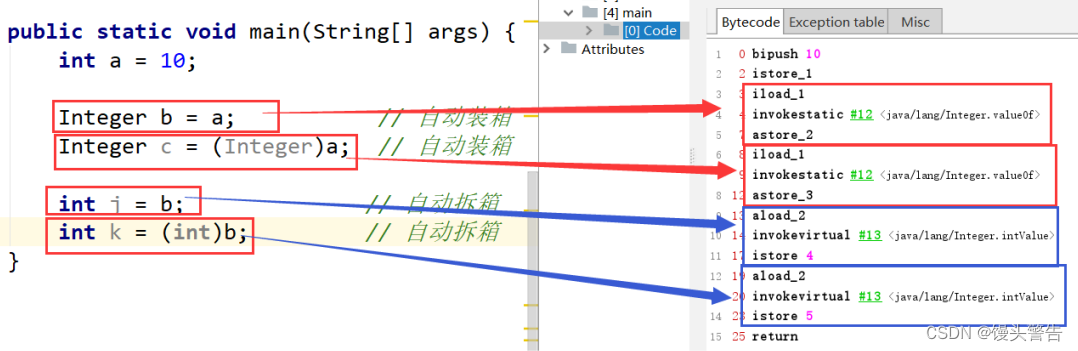
从字节码内容可以看出,在装箱的时候自动调用的是Integer的valueOf(int)方法,而在拆箱的时候自动调用的是Integer的intValue方法。
其他的比如Double、Character等也是类似的,大家可以自己动手尝试一下。
因此可以用一句话总结装箱和拆箱的实现过程:
装箱过程是通过调用包装器的valueOf( )方法实现的,而拆箱过程是通过调用包装器的 xxxValue方法实现的。(xxx代表对应的基本数据类型)。
现在,我们来看一道题,试着思考下列代码的输出结果是什么:
public static void main(String[] args) {Integer a = 127;Integer b = 127;Integer c = 128;Integer d = 128;System.out.println(a == b);System.out.println(c == d);}答案是:true false
这是因为,在Integer这个包装类中,它所能存储的数值的范围是在 -128~127 之间的,而 a、b 均在这个范围内,因此比较a和b的时候比较的是数值的大小,此时a == b,因此输出true。
但是 c 和 d 均超出了Integer所能的范围,因此此时为了存储 c 和 d ,会自动new对象来分别存储它们,此时也就相当于我们比较的是引用类型, 因此在c == d 这个比较中比较的是它们的地址,从而导致输出结果为false
二、什么是泛型
三、引出泛型
1. 我们以前学过的数组,只能存放指定类型的元素,例如:int[] array = new int[10]; String[] strs = new String[10];2. 所有类的父类,默认为Object类。数组是否可以创建为Object?
那么此时,便会有这么一段代码:
class MyArray {public Object[] array = new Object[10];public Object getPos(int pos) {return this.array[pos];}public void setVal(int pos,Object val) {this.array[pos] = val;}
}
public class TestDemo {public static void main(String[] args) {MyArray myArray = new MyArray();myArray.setVal(0,10);myArray.setVal(1,"hello");//字符串也可以存放String ret = myArray.getPos(1);//编译报错System.out.println(ret);}
}通过以上代码实现后我们会发现一下几个问题:
1、泛型的语法
class 泛型类名称<类型形参列表> {
// 这里可以使用类型参数
}
class ClassName<T1, T2, ..., Tn> {}
class 泛型类名称<类型形参列表> extends 继承类/* 这里可以使用类型参数 */ {
// 这里可以使用类型参数
}
class ClassName<T1, T2, ..., Tn> extends ParentClass<T1> {
// 可以只使用部分类型参数}那么此时,我们利用泛型就可以将之前的那段代码改成这个样子:
class MyArray<T> {public T[] array = (T[])new Object[10];//1public T getPos(int pos) {return this.array[pos];}public void setVal(int pos,T val) {this.array[pos] = val;}
}
public class TestDemo {public static void main(String[] args) {MyArray<Integer> myArray = new MyArray<>();//2myArray.setVal(0,10);myArray.setVal(1,12);int ret = myArray.getPos(1);//3System.out.println(ret);myArray.setVal(2,"Hello");//4}
}现在,我们对代码进行一下分析:

2. 不能new泛型类型的数组
那么这也就意味着:
T[] ts = new T[5];//是不对的四、泛型类的使用
1、语法
泛型类<类型实参> 变量名; // 定义一个泛型类引用
new 泛型类<类型实参>(构造方法实参); // 实例化一个泛型类对象2、示例
MyArray<Integer> list = new MyArray<Integer>();MyArray<Integer> list = new MyArray<>();注意:泛型只能接受类,所有的基本数据类型必须使用包装类!
3、类型推导(Type Inference)
MyArray<Integer> list = new MyArray<>(); // 可以推导出实例化需要的类型实参为 Integer1. 泛型是将数据类型参数化,进行传递2. 使用 <T> 表示当前类是一个泛型类。3. 泛型目前为止的优点:数据类型参数化,编译时自动进行类型检查和转换。
六、泛型如何编译的
1、擦除机制
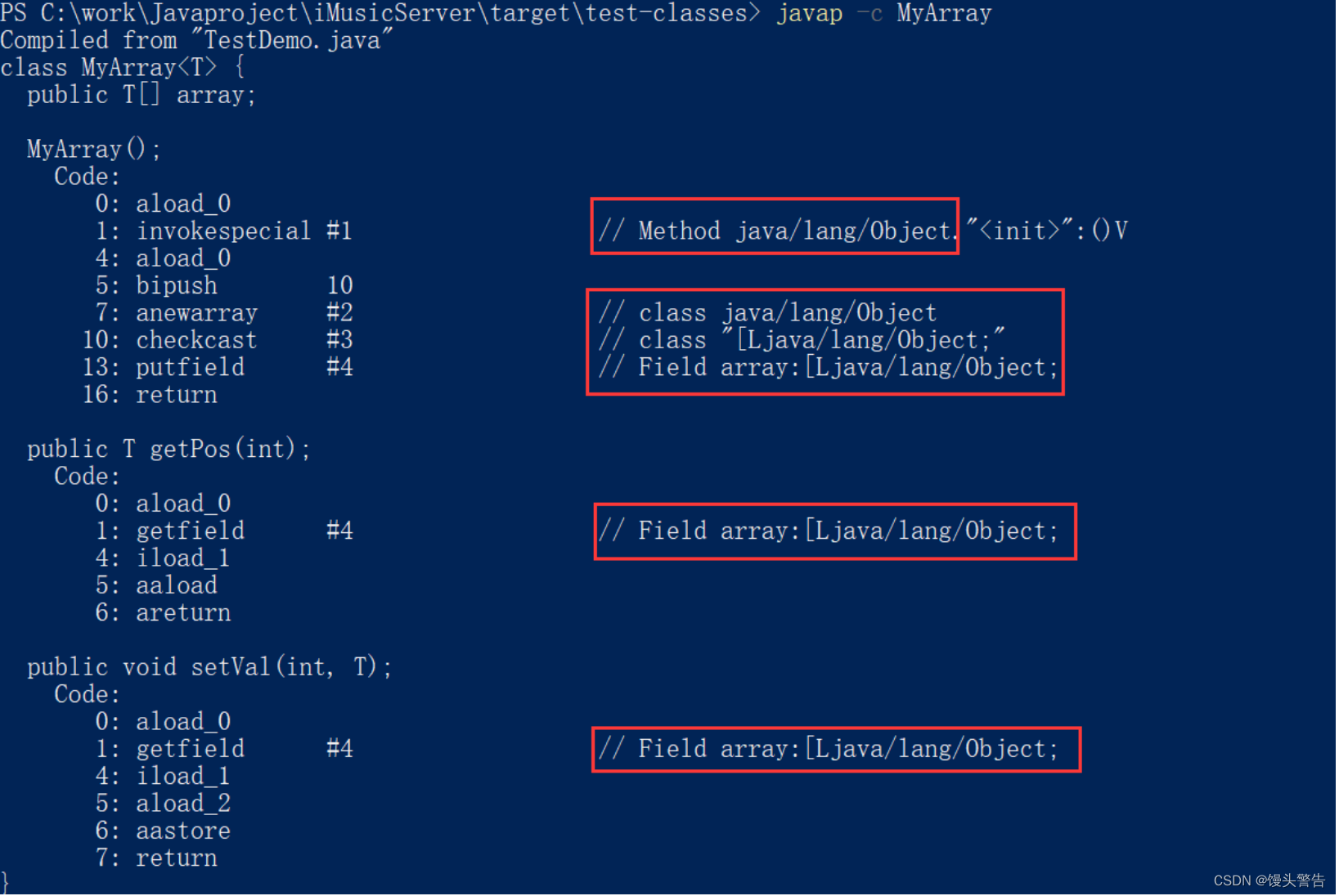
在编译的过程当中,将所有的T替换为Object这种机制,我们称为:擦除机制。
2、为什么不能实例化泛型类型数组
我们先来看这么一段代码:
class MyArray<T> {public T[] array = (T[]) new Object[10];public T getPos(int pos) {return this.array[pos];}public void setVal(int pos, T val) {this.array[pos] = val;}public T[] getArray() {return array;}public static void main(String[] args) {MyArray<Integer> myArray1 = new MyArray<>();Integer[] strings = myArray1.getArray();}
}
此时代码会进行报错:
现在,我们来看一下正确的方法:【了解即可】
class MyArray<T> {public T[] array;public MyArray() {}/* 通过反射创建,指定类型的数组* @param clazz* @param capacity*/public MyArray(Class<T> clazz, int capacity) {array = (T[])Array.newInstance(clazz, capacity);}public T getPos(int pos) {return this.array[pos];}public void setVal(int pos,T val) {this.array[pos] = val;}public T[] getArray() {return array;}
}
public static void main(String[] args) {MyArray<Integer> myArray1 = new MyArray<>(Integer.class,10);Integer[] integers = myArray1.getArray();}七、泛型的上界
1、语法
class 泛型类名称<类型形参 extends 类型边界> {
...
}2、示例
public class MyArray<E extends Number> {
...
}这段代码表示只接受 Number 的子类型作为 E 的类型实参
MyArray<Integer> l1; // 正常,因为 Integer 是 Number 的子类型
MyArray<String> l2; // 编译错误,因为 String 不是 Number 的子类型那么当我们没有指定E的边界的时候,又该怎么判断范围呢?
八、泛型方法
1、定义语法
方法限定符 <类型形参列表> 返回值类型 方法名称(形参列表) { ... }2、示例
public class Util {//静态的泛型方法 需要在static后用<>声明泛型类型参数public static <E> void swap(E[] array, int i, int j) {E t = array[i];array[i] = array[j];array[j] = t;}
}