Doris(6):数据导入(Load)之Stream Load

Broker load是一个同步的导入方式,用户通过发送HTTP协议将本地文件或者数据流导入到Doris中,Stream Load同步执行导入并返回结果,用户可以通过返回判断导入是否成功。
1 适用场景
Stream load 主要适用于导入本地文件,或通过程序导入数据流中的数据。
2 基本原理
下图展示了 Stream load 的主要流程,省略了一些导入细节。
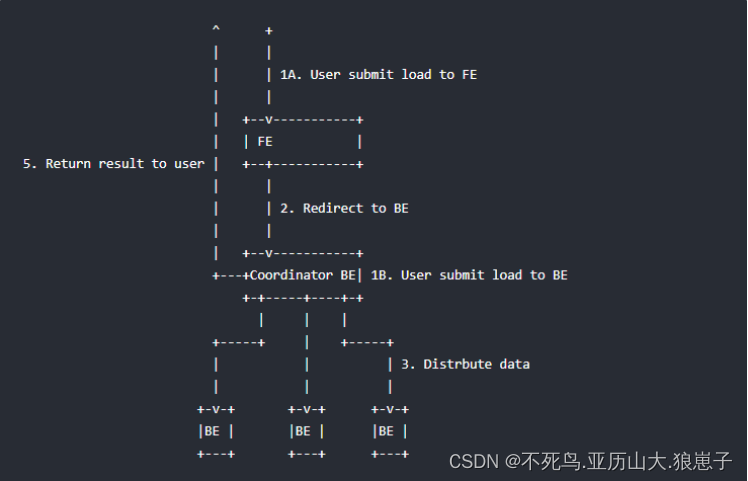
Stream load 中,Doris 会选定一个节点作为 Coordinator 节点。该节点负责接数据并分发数据到其他数据节点。
用户通过 HTTP 协议提交导入命令。如果提交到 FE,则 FE 会通过 HTTP redirect 指令将请求转发给某一个 BE。用户也可以直接提交导入命令给某一指定 BE。
导入的最终结果由 Coordinator BE 返回给用户。
3 语法
具体帮助使用help stream load查看
Name: 'STREAM LOAD'
Description:NAME:stream-load: load data to table in streamingSYNOPSIScurl --location-trusted -u user:passwd [-H ""...] -T data.file -XPUT http://fe_host:http_port/api/{db}/{table}/_stream_loadDESCRIPTION该语句用于向指定的 table 导入数据,与普通Load区别是,这种导入方式是同步导入。这种导入方式仍然能够保证一批导入任务的原子性,要么全部数据导入成功,要么全部失败。该操作会同时更新和此 base table 相关的 rollup table 的数据。这是一个同步操作,整个数据导入工作完成后返回给用户导入结果。当前支持HTTP chunked与非chunked上传两种方式,对于非chunked方式,必须要有Content-Length来标示上传内容长度,这样能够保证数据的完整性。另外,用户最好设置Expect Header字段内容100-continue,这样可以在某些出错场景下避免不必要的数据传输。OPTIONS用户可以通过HTTP的Header部分来传入导入参数label: 一次导入的标签,相同标签的数据无法多次导入。用户可以通过指定Label的方式来避免一份数据重复导入的问题。当前Palo内部保留30分钟内最近成功的label。column_separator:用于指定导入文件中的列分隔符,默认为\\t。如果是不可见字符,则需要加\\x作为前缀,使用十六进制来表示分隔符。如hive文件的分隔符\\x01,需要指定为-H "column_separator:\\x01"。可以使用多个字符的组合作为列分隔符。line_delimiter:用于指定导入文件中的换行符,默认为\\n。可以使用做多个字符的组合作为换行符。columns:用于指定导入文件中的列和 table 中的列的对应关系。如果源文件中的列正好对应表中的内容,那么是不需要指定这个字段的内容的。如果源文件与表schema不对应,那么需要这个字段进行一些数据转换。这里有两种形式column,一种是直接对应导入文件中的字段,直接使用字段名表示;一种是衍生列,语法为 `column_name` = expression。举几个例子帮助理解。例1: 表中有3个列“c1, c2, c3”,源文件中的三个列一次对应的是"c3,c2,c1"; 那么需要指定-H "columns: c3, c2, c1"例2: 表中有3个列“c1, c2, c3", 源文件中前三列依次对应,但是有多余1列;那么需要指定-H "columns: c1, c2, c3, xxx";最后一个列随意指定个名称占位即可例3: 表中有3个列“year, month, day"三个列,源文件中只有一个时间列,为”2018-06-01 01:02:03“格式;那么可以指定-H "columns: col, year = year(col), month=month(col), day=day(col)"完成导入where: 用于抽取部分数据。用户如果有需要将不需要的数据过滤掉,那么可以通过设定这个选项来达到。例1: 只导入大于k1列等于20180601的数据,那么可以在导入时候指定-H "where: k1 = 20180601"max_filter_ratio:最大容忍可过滤(数据不规范等原因)的数据比例。默认零容忍。数据不规范不包括通过 where 条件过滤掉的行。partitions: 用于指定这次导入所设计的partition。如果用户能够确定数据对应的partition,推荐指定该项。不满足这些分区的数据将被过滤掉。比如指定导入到p1, p2分区,-H "partitions: p1, p2"timeout: 指定导入的超时时间。单位秒。默认是 600 秒。可设置范围为 1 秒 ~ 259200 秒。strict_mode: 用户指定此次导入是否开启严格模式,默认为关闭。开启方式为 -H "strict_mode: true"。timezone: 指定本次导入所使用的时区。默认为东八区。该参数会影响所有导入涉及的和时区有关的函数结果。exec_mem_limit: 导入内存限制。默认为 2GB。单位为字节。format: 指定导入数据格式,默认是csv,支持json格式。jsonpaths: 导入json方式分为:简单模式和匹配模式。简单模式:没有设置jsonpaths参数即为简单模式,这种模式下要求json数据是对象类型,例如:{"k1":1, "k2":2, "k3":"hello"},其中k1,k2,k3是列名字。匹配模式:用于json数据相对复杂,需要通过jsonpaths参数匹配对应的value。strip_outer_array: 布尔类型,为true表示json数据以数组对象开始且将数组对象中进行展平,默认值是false。例如:[{"k1" : 1, "v1" : 2},{"k1" : 3, "v1" : 4}]当strip_outer_array为true,最后导入到doris中会生成两行数据。json_root: json_root为合法的jsonpath字符串,用于指定json document的根节点,默认值为""。merge_type: 数据的合并类型,一共支持三种类型APPEND、DELETE、MERGE 其中,APPEND是默认值,表示这批数据全部需要追加到现有数据中,DELETE 表示删除与这批数据key相同的所有行,MERGE 语义 需要与delete 条件联合使用,表示满足delete 条件的数据按照DELETE 语义处理其余的按照APPEND 语义处理, 示例:`-H "merge_type: MERGE" -H "delete: flag=1"`delete: 仅在 MERGE下有意义, 表示数据的删除条件function_column.sequence_col: 只适用于UNIQUE_KEYS,相同key列下,保证value列按照source_sequence列进行REPLACE, source_sequence可以是数据源中的列,也可以是表结构中的一列。fuzzy_parse: 布尔类型,为true表示json将以第一行为schema 进行解析,开启这个选项可以提高json 导入效率,但是要求所有json 对象的key的顺序和第一行一致, 默认为false,仅用于json 格式num_as_string: 布尔类型,为true表示在解析json数据时会将数字类型转为字符串,然后在确保不会出现精度丢失的情况下进行导入。read_json_by_line: 布尔类型,为true表示支持每行读取一个json对象,默认值为false。send_batch_parallelism: 整型,用于设置发送批处理数据的并行度,如果并行度的值超过 BE 配置中的 `max_send_batch_parallelism_per_job`,那么作为协调点的 BE 将使用 `max_send_batch_parallelism_per_job` 的值。 RETURN VALUES导入完成后,会以Json格式返回这次导入的相关内容。当前包括以下字段Status: 导入最后的状态。Success:表示导入成功,数据已经可见;Publish Timeout:表述导入作业已经成功Commit,但是由于某种原因并不能立即可见。用户可以视作已经成功不必重试导入Label Already Exists: 表明该Label已经被其他作业占用,可能是导入成功,也可能是正在导入。用户需要通过get label state命令来确定后续的操作其他:此次导入失败,用户可以指定Label重试此次作业Message: 导入状态详细的说明。失败时会返回具体的失败原因。NumberTotalRows: 从数据流中读取到的总行数NumberLoadedRows: 此次导入的数据行数,只有在Success时有效NumberFilteredRows: 此次导入过滤掉的行数,即数据质量不合格的行数NumberUnselectedRows: 此次导入,通过 where 条件被过滤掉的行数LoadBytes: 此次导入的源文件数据量大小LoadTimeMs: 此次导入所用的时间BeginTxnTimeMs: 向Fe请求开始一个事务所花费的时间,单位毫秒。StreamLoadPutTimeMs: 向Fe请求获取导入数据执行计划所花费的时间,单位毫秒。ReadDataTimeMs: 读取数据所花费的时间,单位毫秒。WriteDataTimeMs: 执行写入数据操作所花费的时间,单位毫秒。CommitAndPublishTimeMs: 向Fe请求提交并且发布事务所花费的时间,单位毫秒。ErrorURL: 被过滤数据的具体内容,仅保留前1000条ERRORS可以通过以下语句查看导入错误详细信息:SHOW LOAD WARNINGS ON 'url'其中 url 为 ErrorURL 给出的 url。
Examples:1. 将本地文件'testData'中的数据导入到数据库'testDb'中'testTbl'的表,使用Label用于去重。指定超时时间为 100 秒curl --location-trusted -u root -H "label:123" -H "timeout:100" -T testData http://host:port/api/testDb/testTbl/_stream_load2. 将本地文件'testData'中的数据导入到数据库'testDb'中'testTbl'的表,使用Label用于去重, 并且只导入k1等于20180601的数据curl --location-trusted -u root -H "label:123" -H "where: k1=20180601" -T testData http://host:port/api/testDb/testTbl/_stream_load3. 将本地文件'testData'中的数据导入到数据库'testDb'中'testTbl'的表, 允许20%的错误率(用户是defalut_cluster中的)curl --location-trusted -u root -H "label:123" -H "max_filter_ratio:0.2" -T testData http://host:port/api/testDb/testTbl/_stream_load4. 将本地文件'testData'中的数据导入到数据库'testDb'中'testTbl'的表, 允许20%的错误率,并且指定文件的列名(用户是defalut_cluster中的)curl --location-trusted -u root -H "label:123" -H "max_filter_ratio:0.2" -H "columns: k2, k1, v1" -T testData http://host:port/api/testDb/testTbl/_stream_load5. 将本地文件'testData'中的数据导入到数据库'testDb'中'testTbl'的表中的p1, p2分区, 允许20%的错误率。curl --location-trusted -u root -H "label:123" -H "max_filter_ratio:0.2" -H "partitions: p1, p2" -T testData http://host:port/api/testDb/testTbl/_stream_load6. 使用streaming方式导入(用户是defalut_cluster中的)seq 1 10 | awk '{OFS="\\t"}{print $1, $1 * 10}' | curl --location-trusted -u root -T - http://host:port/api/testDb/testTbl/_stream_load7. 导入含有HLL列的表,可以是表中的列或者数据中的列用于生成HLL列,也可使用hll_empty补充数据中没有的列curl --location-trusted -u root -H "columns: k1, k2, v1=hll_hash(k1), v2=hll_empty()" -T testData http://host:port/api/testDb/testTbl/_stream_load8. 导入数据进行严格模式过滤,并设置时区为 Africa/Abidjancurl --location-trusted -u root -H "strict_mode: true" -H "timezone: Africa/Abidjan" -T testData http://host:port/api/testDb/testTbl/_stream_load9. 导入含有BITMAP列的表,可以是表中的列或者数据中的列用于生成BITMAP列,也可以使用bitmap_empty填充空的Bitmapcurl --location-trusted -u root -H "columns: k1, k2, v1=to_bitmap(k1), v2=bitmap_empty()" -T testData http://host:port/api/testDb/testTbl/_stream_load10. 简单模式,导入json数据表结构: `category` varchar(512) NULL COMMENT "",`author` varchar(512) NULL COMMENT "",`title` varchar(512) NULL COMMENT "",`price` double NULL COMMENT ""json数据格式:{"category":"C++","author":"avc","title":"C++ primer","price":895}导入命令:curl --location-trusted -u root -H "label:123" -H "format: json" -T testData http://host:port/api/testDb/testTbl/_stream_load为了提升吞吐量,支持一次性导入多条json数据,每行为一个json对象,默认使用\\n作为换行符,需要将read_json_by_line设置为true,json数据格式如下: {"category":"C++","author":"avc","title":"C++ primer","price":89.5}{"category":"Java","author":"avc","title":"Effective Java","price":95}{"category":"Linux","author":"avc","title":"Linux kernel","price":195} 11. 匹配模式,导入json数据json数据格式:[{"category":"xuxb111","author":"1avc","title":"SayingsoftheCentury","price":895},{"category":"xuxb222","author":"2avc","title":"SayingsoftheCentury","price":895},{"category":"xuxb333","author":"3avc","title":"SayingsoftheCentury","price":895}]通过指定jsonpath进行精准导入,例如只导入category、author、price三个属性 curl --location-trusted -u root -H "columns: category, price, author" -H "label:123" -H "format: json" -H "jsonpaths: [\\"$.category\\",\\"$.price\\",\\"$.author\\"]" -H "strip_outer_array: true" -T testData http://host:port/api/testDb/testTbl/_stream_load说明:1)如果json数据是以数组开始,并且数组中每个对象是一条记录,则需要将strip_outer_array设置成true,表示展平数组。2)如果json数据是以数组开始,并且数组中每个对象是一条记录,在设置jsonpath时,我们的ROOT节点实际上是数组中对象。12. 用户指定json根节点json数据格式:{"RECORDS":[{"category":"11","title":"SayingsoftheCentury","price":895,"timestamp":1589191587},{"category":"22","author":"2avc","price":895,"timestamp":1589191487},{"category":"33","author":"3avc","title":"SayingsoftheCentury","timestamp":1589191387}]}通过指定jsonpath进行精准导入,例如只导入category、author、price三个属性 curl --location-trusted -u root -H "columns: category, price, author" -H "label:123" -H "format: json" -H "jsonpaths: [\\"$.category\\",\\"$.price\\",\\"$.author\\"]" -H "strip_outer_array: true" -H "json_root: $.RECORDS" -T testData http://host:port/api/testDb/testTbl/_stream_load13. 删除与这批导入key 相同的数据curl --location-trusted -u root -H "merge_type: DELETE" -T testData http://host:port/api/testDb/testTbl/_stream_load14. 将这批数据中与flag 列为ture 的数据相匹配的列删除,其他行正常追加curl --location-trusted -u root: -H "column_separator:," -H "columns: siteid, citycode, username, pv, flag" -H "merge_type: MERGE" -H "delete: flag=1" -T testData http://host:port/api/testDb/testTbl/_stream_load15. 导入数据到含有sequence列的UNIQUE_KEYS表中curl --location-trusted -u root -H "columns: k1,k2,source_sequence,v1,v2" -H "function_column.sequence_col: source_sequence" -T testData http://host:port/api/testDb/testTbl/_stream_load
4 数据导入演示
进入mysqlclient,清空上次导入到user_result表的数据
truncate table user_result;通过命令将csv将数据导入到doris,-H指定参数,column_seqarator指定分割符,-T指定数据源文件(在csv文件目录下执行)
curl --location-trusted -u root -H "label:123" -H "column_separator:," -T user.csv -X PUT http://192.168.222.143:8030/api/test_db/user_result/_stream_load5 其他导入案例参考
将本地文件'testData'中的数据导入到数据库'testDb'中'testTbl'的表,使用Label用于去重
curl --location-trusted -u root -H "label:123" -T testData http://host:port/api/testDb/testTbl/_stream_load将本地文件'testData'中的数据导入到数据库'testDb'中'testTbl'的表,使用Label用于去重, 并且只导入k1等于20180601的数据
curl --location-trusted -u root -H "label:123" -H "where: k1=20180601" -T testData http://host:port/api/testDb/testTbl/_stream_load将本地文件'testData'中的数据导入到数据库'testDb'中'testTbl'的表, 允许20%的错误率(用户是defalut_cluster中的)
curl --location-trusted -u root -H "label:123" -H "max_filter_ratio:0.2" -T testData http://host:port/api/testDb/testTbl/_stream_load将本地文件'testData'中的数据导入到数据库'testDb'中'testTbl'的表, 允许20%的错误率,并且指定文件的列名(用户是defalut_cluster中的)
curl --location-trusted -u root -H "label:123" -H "max_filter_ratio:0.2" -H "columns: k2, k1, v1" -T testData http://host:port/api/testDb/testTbl/_stream_load将本地文件'testData'中的数据导入到数据库'testDb'中'testTbl'的表中的p1, p2分区, 允许20%的错误率。
curl --location-trusted -u root -H "label:123" -H "max_filter_ratio:0.2" -H "partitions: p1, p2" -T testData http://host:port/api/testDb/testTbl/_stream_load使用streaming方式导入(用户是defalut_cluster中的)
seq 1 10 | awk '{OFS="\\t"}{print $1, $1 * 10}' | curl --location-trusted -u root -T - http://host:port/api/testDb/testTbl/_stream_load导入含有HLL列的表,可以是表中的列或者数据中的列用于生成HLL列
curl --location-trusted -u root -H "columns: k1, k2, v1=hll_hash(k1)" -T testData http://host:port/api/testDb/testTbl/_stream_load