【基础算法】单链表的OJ练习(3) # 移除链表元素 # 相交链表 #

文章目录
- 前言
- 移除链表元素
- 相交链表
- 写在最后
前言
-
本章的
OJ练习也是相对简单的,只要能够理解解题的思路,并且依照这个思路能够快速的写出代码,我相信,你的链表水平已经足够了。 -
对于
OJ练习(2): ->传送门<-。其中两道题都可运用快慢指针的解题思路,这使得两个题都只需要遍历一次链表即可解答。 -
对于本章,是链表的
OJ练习的最后一篇较为简单的章节,后续的OJ练习将会上难度。
移除链表元素
-
题目链接:-> 传送门 <-。
-
该题目的描述为:给你一个链表的头节点
head和一个整数val,请你删除链表中所有满足Node.val == val的节点,并返回 新的头节点 。
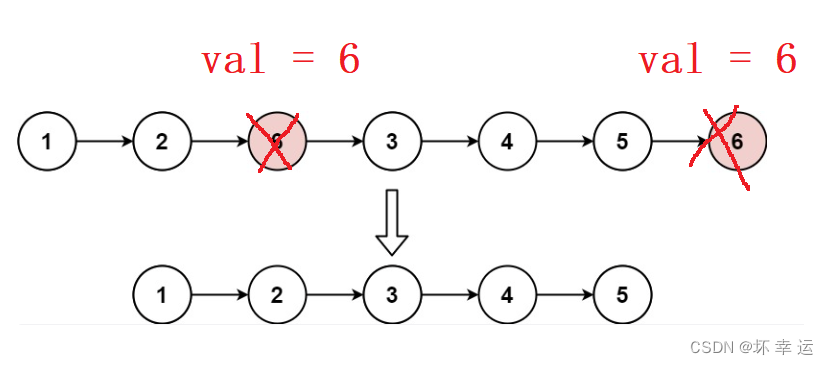
-
这里我们采用的方法是在原链表的基础上重新连接节点,将 Node.val == val 的节点跳过不连接。
-
我们重新定义一个指向新连接的链表的头节点的指针
newhead,然后在定义一个用来连接的指针cur,最终连接好后返回newhead即可。 -
将 Node.val != val 的节点作为新连接的链表的结点 ,如果一开始
head为空或者head链表里全是等于val的结点,(初始化newnode = cur = NULL)此时连接操作就不进行,后面返回newnode(一直为NULL)即可。


下面是代码实现:
struct ListNode* removeElements(struct ListNode* head, int val){// cur为对新连接的链表的连接指针,newhead为新连接的链表的指向头节点的指针struct ListNode* cur = NULL, * newhead = NULL;struct ListNode* tmp = head;while (tmp){if (tmp->val != val) // 如果不等于val就连接{if (newhead == NULL) // 连接时如果新的头为空,就将该节点作为头节点{newhead = cur = tmp;}else // 正常连接{cur->next = tmp;cur = cur->next;}}tmp = tmp->next; // 到下一个节点判断}// 如果head为空或者head链表里面所有节点的val都为所给的val,就说明没有新的头,这里判断是为了防止空指针解引用// 如果是正常情况,需要将新连接的最后一个节点的next指向NULL,如果已经指向NULL,多操作一步也没有问题if (cur) cur->next = NULL;// 最后返回新连接的链表的头return newhead;
}
相交链表
-
题目链接:-> 传送门 <-。
-
该题目描述为:给你两个单链表的头节点
headA和headB,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回null。
也就是:
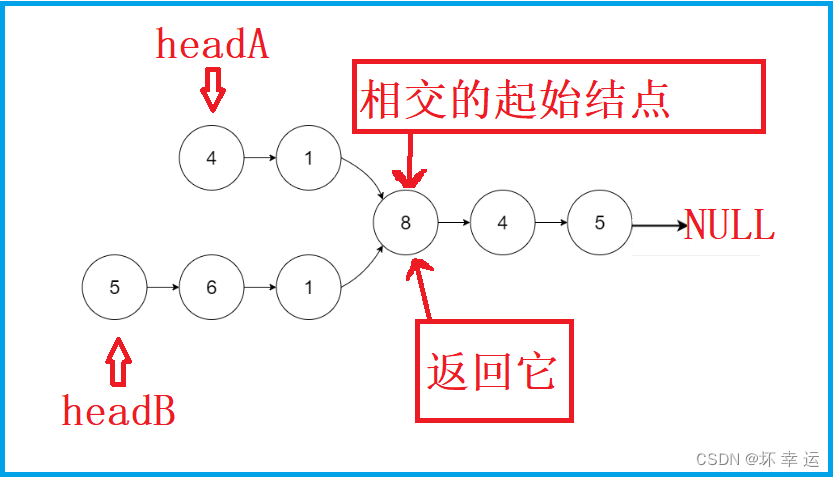
解题思路:【双指针遍历】
-
首先我们可以先判断这两个链表是否有一个为空或者都为空,有空的情况那么一定不相交,此时直接返回
NULL。 -
如果两个链表相交,那么从相交的那个起始节点开始,后面的长度是相同的。由此我们定义两个指针
pa与pb分别指向headA的头节点与headB的头节点并同时向后遍历链表。 -
如果
pa不为NULL,则移到下一个节点,如果pb不为空,也移到下一个节点。如果第一次遍历pa为空,则将pa指向headB的头节点;如果第一次遍历pb为空,则将pb指向headA的头节点。至于到底相不相交,第二遍遍历会见分晓。 -
我们假设两个链表相交,那么设从相交的初始节点开始到
NULL的长度为n,headA的头节点到相交的初始节点的长度为x,headB的头节点到相交的初始节点的长度为y。按照上一条的思路,当pa第一次遍历到达NULL时,pa一共走了x + n的长度,此时将pa指向headB的头节点;当pb第一次遍历到达NULL时,pb一共走了y + n的长度,此时将pb指向headA的头节点。仔细思考就会发现,pa在headB走到相交的初始节点还需走y的长度,此时pa一共走了x + n + y;pb在headA走到相交的初始节点还需走x的长度,此时pb一共走了y + n + x。这时,pa走的长度与pb走的长度恰好相等,且pa与pb都刚好指向相交的初始节点。所以,该方法能够有效的找出那个相交的初始节点。

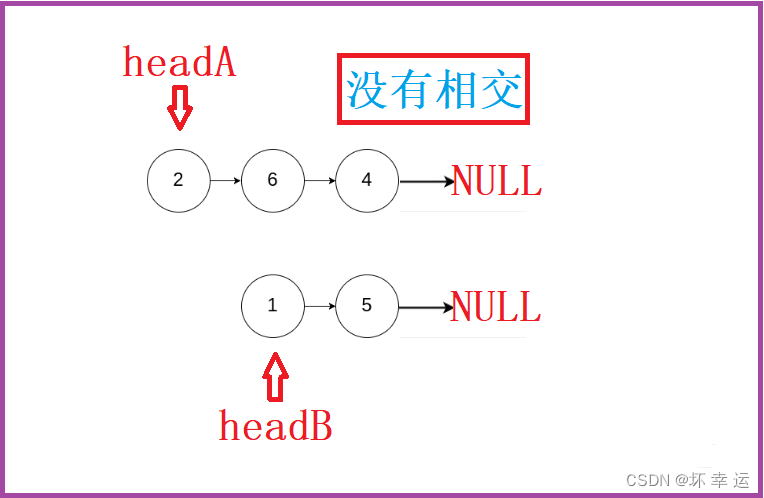
- 如果两个链表不相交,也是一样,通过双指针分别依次向后遍历链表。如果两个链表长度相等,最终
pa与pb在第一次遍历的时候就都会到达NULL,此时返回NULL;如果两个链表长度不相等,同样的,在第一次遍历时,只要pa或者pb指向NULL,就将pa或者pb指向另外一个链表的头节点,然后继续遍历。我们假设headA链表的长度为x,headB链表的长度为y,当pa第一次遍历指向NULL时,走的长度为x,此时将pa指向headB的头节点;当pb第一次遍历指向NULL时,走的长度为y,此时将pb指向headA的头节点。不出所料,两个指针在第二次遍历链表时最后同时指向NULL,这是因为,pa在headB的遍历要走的长度为y,此时pa总共走的长度为x + y;pb在headA的遍历要走的长度为x,此时pb总共走的长度为y + x。可以看到,第二次遍历走完两个指针走的长度是相同的,并且两个指针都是指向NULL。所以,两个链表不相交,遍历的两个指针最终都是同时指向NULL。

下面是代码实现:
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {// 如果其中有一个链表为空或者全为空,说明不可能相交,直接返回NULLif(headA == NULL || headB == NULL) return NULL;struct ListNode* pa = headA, * pb = headB;// 对于headA与headB只有相交与不相交的情况// 相交则跳出循环// 不相交则再循环里面就返回// pa == pb说明找到相交的初始节点了,条件判断为假,跳出循环while (pa != pb){// 同步向后遍历pa = pa->next;pb = pb->next;// 如果两个指针都指向空,说明headA与headB不相交if (pa == NULL && pb == NULL) return NULL;// 如果pa遍历完headA就到headB继续遍历if (pa == NULL) pa = headB;// 如果pb遍历完headB就到headA继续遍历if (pb == NULL) pb = headA;} // 这里返回pa或者pb都是可以的,都指向相交的那个初始节点return pa;
}
写在最后
对于单链表的题目练习,最重要的是思路,我们在数据结构阶段要养成画图的习惯,因为它能帮助我们更好的理解。后续还会有单链表相关的题目练习。
感谢阅读本小白的博客,错误的地方请严厉指出噢!