【Redis】redis大key和大value的危害,如何处理?

前序
还记得上次和同事一起去面试候选人时,同事提了一个问题:Redis的大key有什么危害?当时候选人主要作答的角度是一个key的value较大时的情况,比如:
- 内存不均:单value较大时,可能会导致节点之间的内存使用不均匀,间接地影响key的部分和负载不均匀;
- 阻塞请求:redis为单线程,单value较大读写需要较长的处理时间,会阻塞后续的请求处理;
- 阻塞网络:单value较大时会占用服务器网卡较多带宽,可能会影响该服务器上的其他Redis实例或者应用。
虽说答的是挺好的,但是我又随之产生了另一个疑惑,如果redis的key较长时,会产生什么样的影响呢?查了很多文章,说的都不是特别清楚。所以我决心探究一下这个问题。
我们需要知道Redis是如何存储key和value的:
根结构为RedisServer,其中包含RedisDB(数据库)。而RedisDB实际上是使用Dict(字典)结构对Redis中的kv进行存储的。这里的key即字符串,value可以是string/hash/list/set/zset这五种对象之一。
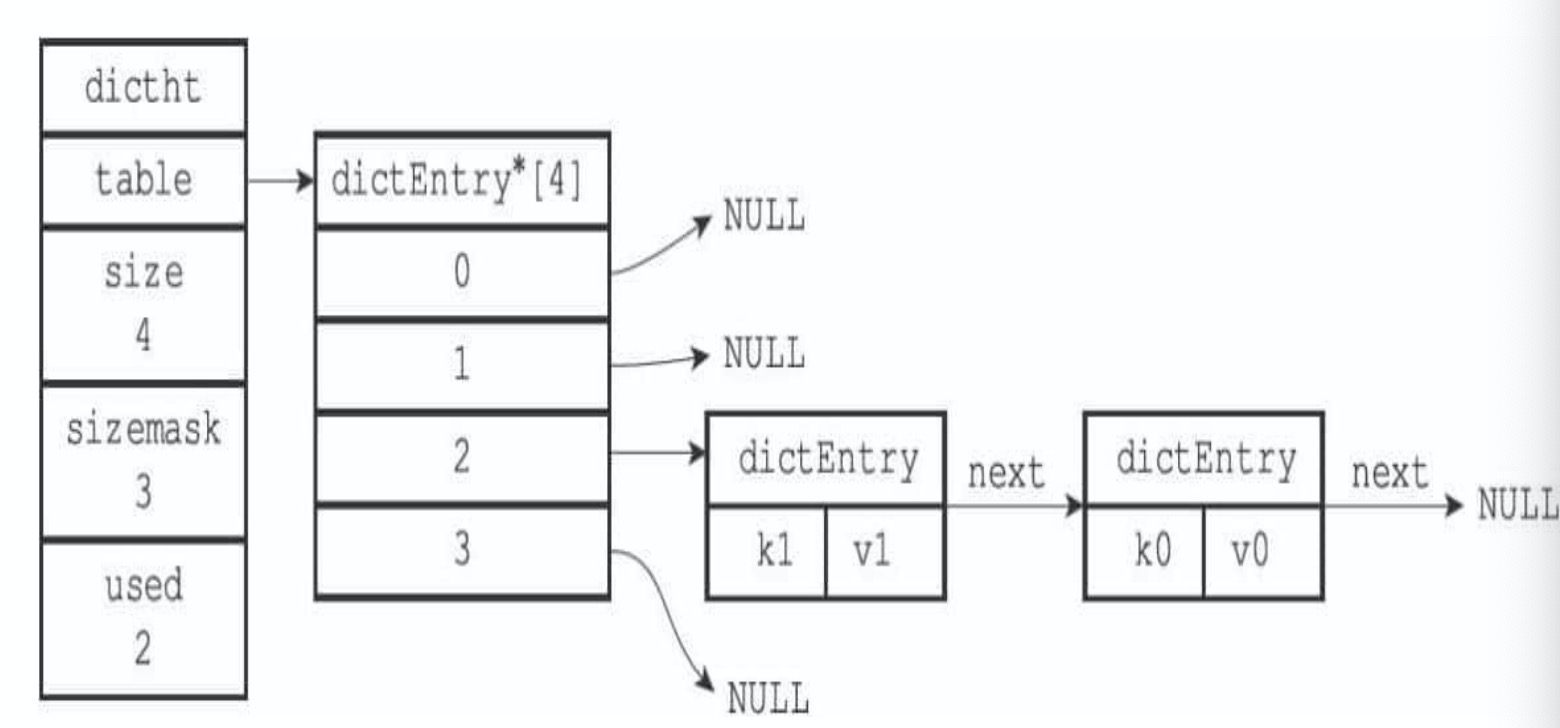
Dict字典结构中,存储数据的主题为DictHt,即哈希表。而哈希表本质上是一个DictEntry(哈希表节点)的数组,并且使用链表法解决哈希冲突问题(关于哈希冲突的解决方法可以参考大佬的文章 解决哈希冲突的常用方法分析)。
所以在这里实际存储时,key和value都是存储在DictEntry中的。所以基本上来说,大key和大value带来的内存不均和网络IO压力都是一致的,只是key相较于value还多一个做hashcode和比较的过程(链表中进行遍历比较key),会有更多的内存相关开销。
结论
- 大key和大value的危害是一致的:内存不均、阻塞请求、阻塞网络。
- key由于比value需要做更多的操作如hashcode、链表中比较等操作,所以会比value更多一些内存相关开销。
我们需要知道Redis是如何存储key和value的:
根结构为RedisServer,其中包含RedisDB(数据库)。而RedisDB实际上是使用Dict(字典)结构对Redis中的kv进行存储的。这里的key即字符串,value可以是string/hash/list/set/zset这五种对象之一。
Redis 大key如何处理?
Redis使用过程中经常会有各种大key的情况, 比如:
单个简单的key存储的value很大
hash, set,zset,list 中存储过多的元素(以万为单位)
由于redis是单线程运行的,如果一次操作的value很大会对整个redis的响应时间造成负面影响,所以,业务上能拆则拆,下面举几个典型的分拆方案。
业务场景:
即通过hash的方式来存储每一天用户订单次数。那么key = order_20200102, field = order_id, value = 10。那么如果一天有百万千万甚至上亿订单的时候,key后面的值是很多,存储空间也很大,造成所谓的大key。
大key的风险:
-
读写大key会导致超时严重,甚至阻塞服务。
-
如果删除大key,DEL命令可能阻塞Redis进程数十秒,使得其他请求阻塞,对应用程序和Redis集群可用性造成严重的影响。
redis使用会出现大key的场景:
- 单个简单key的存储的value过大;
- hash、set、zset、list中存储过多的元素。
解决问题:
- 单个简单key的存储的value过大的解决方案:
将大key拆分成对个key-value,使用multiGet方法获得值,这样的拆分主要是为了减少单台操作的压力,而是将压力平摊到集群各个实例中,降低单台机器的IO操作。
- hash、set、zset、list中存储过多的元素的解决方案:
1).类似于第一种场景,使用第一种方案拆分;
2).以hash为例,将原先的hget、hset方法改成(加入固定一个hash桶的数量为10000),先计算field的hash值模取10000,确定该field在哪一个key上。
将大key进行分割,为了均匀分割,可以对field进行hash并通过质数N取余,将余数加到key上面,我们取质数N为997。
那么新的key则可以设置为:
newKey = order_20200102_String.valueOf( Math.abs(order_id.hashcode() % 997) )
field = order_id
value = 10
hset (newKey, field, value) ;
hget(newKey, field)
大value数据是什么,会有怎样的问题?
当String类型的数据>10K,list、hash、set、sort set中元素个数超过1000时就可以被称为大value,当超过100K,或集合元素个数超过10000时可以被称为是超大value。大value最直接的影响就是有可能造成机器内存不足,就是数据倾斜;同时因为redis数据处理是单线程的,当value过大时,处理起来响应时间也会变慢。 常见的例子有:参与人数很多的盖楼活动或者很活跃的群聊消息列表等
怎么处理Redis大value?
大value的处理方式还是结合业务,对其进行拆分,将其数据分布在各个redis节点中,将操作压力平摊开,防止对单个实例IO或内存影响过大。
简单说一下 热点数据和大value的拆分,如果它是一个list、 set集合类型,比如原来的 为key value,value为list为拆为 list1 、list2、list3,那么新的key为 key+hash(list1)%10000 得到新的key,再对对应数据value进行set或get操作
如果是一个对象的json字符串,可以考虑将该对象的不同属性映射到不同hash槽从而分布在不同redis节点中;或者将不同属性拆分,利用hash结构进行存储,从而每次处理时仅获取一部分数据