OSS下载中文名编码错误

最近工作中有个需求,是将客户支付的银行回执单上按照客户姓名上传到oss,然后将oss地址反显到pc后台,供客户自己查看下载。
开始的时候感觉很简单,设计思路是根据客户支付单单号,查询数据库中是否存在该支付单的回执单,若存在直接返回,若不返回则通过拉卡拉API申请回执单,然后将结果保存到数据库(因不是频繁操作需求所以没有做缓存处理)。
private static LklSOAClient soaClient;
/
* 初始化请求
*/
private static void iniLklSOAClient() {try {soaClient = new LklSOAClient();//应用号,钱账通提供的应用IDsoaClient.setAppId(LaKaLaConstant.appId);//版本号,当前版本为 3.0soaClient.setVersion(LaKaLaConstant.version);//商户DSA私钥,钱账通提供的DSA私钥log.info("privateKeyPwd={}", LaKaLaConstant.privateKeyPwd);soaClient.setPrivateKey(LklDSAUtil.loadPrivateKey(LaKaLaConstant.private KeyUrl, LaKaLaConstant.privateKeyPwd));//钱账通DSA公钥,钱账通提供的DSA公钥soaClient.setPublicKey(LklDSAUtil.loadPublicKey(LaKaLaConstant.publicKey Url));//钱账通接口地址soaClient.setServerUrl(LaKaLaConstant.soaServerUrl);} catch (Exception e) {log.error(e.toString(), e);}
}
/* 根据订单号查询电子回单文件列表* @param orderNo* @return*/ public static JSONObject receiptQuery(String orderNo){JSONObject jsonParam = new JSONObject();jsonParam.put("order_no", orderNo);//订单单号必填JSONObject response = null;String service = "order.receipt.query";try {log.info("拉卡拉回单查询接口请求参数:{}", JSONUtil.format(jsonParam));response = soaClient.request(service, jsonParam);log.info("拉卡拉回单查询接口返回:{}", JSONUtil.format(response));} catch (Exception e) {log.error(e.toString(), e);return null;} finally {//此处保存请求日志信息}//此处返回请求结果 return Objects.requireNonNull(response).getJSONObject("response"); }
以上是关于获取电子回单的请求,截止到这里还没有问题
下面我们进行oss文件上传
/* 上传到oss* @param path* @param fileName* @return*/
public String fileUploadByFileNo(String path,String fileName){log.info("文件在服务器地址:{}",path);File file = new File(path);if (cn.hutool.core.io.FileUtil.isEmpty(file)) {log.error("文件不存在,filePath = {}", path);throw new RuntimeException();}log.info("文件长度:{}",file.length());// 上传到ossFileInputStream fileInputStream = null;String ossPath ;try {fileInputStream = new FileInputStream(file);//上传oss工具类方法ossPath = OSSUtil.uploadFile2OSS(fileInputStream, fileName);if (StringUtils.isEmpty(ossPath)) {log.error("oss文件上传失败,fileName={}",fileName);throw new RuntimeException();}} catch (Exception e) {log.error("oss文件流异常:",e);throw new RuntimeException();} finally {IoUtil.close(fileInputStream);}return ossPath;
}
/* 上传到OSS服务器 如果同名文件会覆盖服务器上的 @param inStream 文件流* @param fileName 文件名称 包括后缀名* @return 出错返回"" ,唯一MD5数字签名*/
public static String uploadFile2OSS(InputStream inStream, String fileName){OSSClient ossClient = OSSUtil.getOSSClient();String ret = "";try {//创建上传Object的MetadataObjectMetadata objectMetadata = new ObjectMetadata();objectMetadata.setContentLength(inStream.available());objectMetadata.setCacheControl("no-cache");objectMetadata.setHeader("Pragma","no-cache");//通过文件名判断并获取文件的contentType
objectMetadata.setContentType(getContentType(fileNam e.substring (fileName.lastIndexOf("."))));objectMetadata.setContentDisposition("inline;filename=" + fileName);//上传文件PutObjectResult putResult = ossClient.putObject(bucketName, filedir + fileName, inStream, objectMetadata);//文件在oss地址ret = getUrl(fileName),StandardCharsets.UTF_8.toString();} catch (IOException e) {logger.error(e.getMessage(), e);} finally {try {if (inStream != null) {inStream.close();}} catch (IOException e) {e.printStackTrace();}}return ret;
}
/* 获取文件URL @Title getUrl* @param @param* key* @param @return* @return URL*/
public static String getUrl(String key) throws UnsupportedEncodingException {if (key.indexOf("http") == -1) {OSSClient server = new OSSClient(endpoint, accessKeyId, accessKeySecret);// 连接oss云存储服务器// 设置URL过期时间为10年 3600l* 1000*24*365*10Date expirations = new Date(new Date().getTime() + 1000 * 60 * 5);// url超时时间// 生成URLURL url = server.generatePresignedUrl(bucketName,filedir + key, expirations);String strUrl = String.valueOf(url);// 关闭clientserver.shutdown();return splitUrl(strUrl);} else {return splitUrl(key);}
}
/* 切割url @param url* @return*/
public static String splitUrl(String url) {if (url.indexOf("?Expires") != -1) {return url.split("Expires")[0].substring(0,url.split("Expires")[0].length() -1 );}return url;
}
根据fileName获取URL时就会发现获取到地址不是这种
https://img-video.oss-cn-beijing.aliyuncs.com/测试中.pdf
而是一下这种
https://img-video.oss-cn-beijing.aliyuncs.com/%E5%BC%A0%E5%AE%81.pdf
开始的时候以为是自己没有指定上传文件编码导致的,但是在oss后台查看发现已经是中文名称路径了,所以就在上传时指定了编码格式为UTF-8
objectMetadata.setContentEncoding(StandardCharsets.UTF_8.toString());
后来发现并没有用,就去翻了一下oss源码,发现他们在上传时就已经指定了编码为UTF-8
源码路径com.aliyun.oss.internal.OSSOperation#createDefaultContext(com.aliyun.oss.HttpMethod, java.lang.String, java.lang.String)
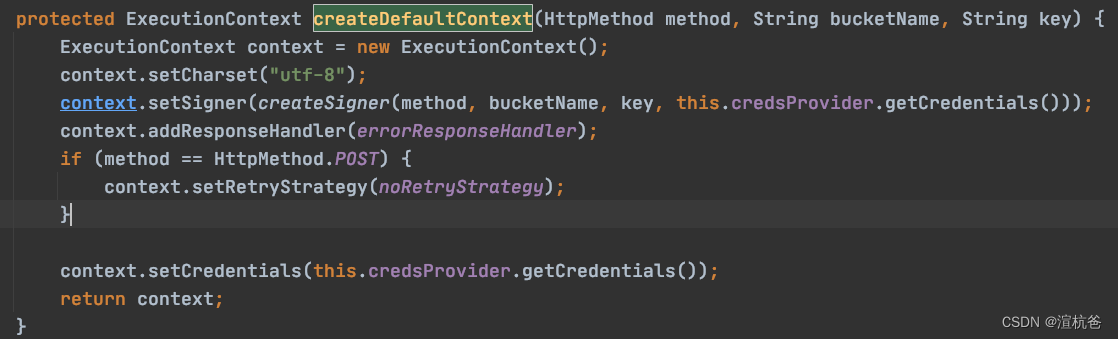
那就只能是下载url时有问题了,继续查看源码发现文件下载时,又用UTF-8进行了编码
源码地址:
com.aliyun.oss.OSSClient#generatePresignedUrl(com.aliyun.oss.model.GeneratePresignedUrlRequest)
方法中在做http请求时
HttpUtil.paramToQueryString(params, "utf-8");
继续查看HttpUtil.paramToQueryString会发现他对url做了处理,如下
public static String urlEncode(String value, String encoding) {if (value == null) {return "";} else {try {String encoded = URLEncoder.encode(value, encoding);return encoded.replace("+", "%20").replace("*", "%2A").replace("~", "%7E").replace("/", "%2F");} catch (UnsupportedEncodingException var3) {throw new IllegalArgumentException(OSSUtils.OSS_RESOURCE_MANAGER.getString("FailedToEncodeUri"), var3);}}
}
截止这里就会明白了,因为在获取文件url时进行了URLEncoder.encode(value, encoding)所以获取的结果地址不是中文名称。
所以我们只需要在获取文件url地址后进行再进行编译即可,如下
ret = URLDecoder.decode(getUrl(fileName),StandardCharsets.UTF_8.toString());
会发现结果ret结果变成了我们想要的中文名称,如下
https://img-video.oss-cn-beijing.aliyuncs.com/测试中.pdf