rnn、lstm、cnn、transformer

rnn不能并行的原因:不同时间步的隐藏层之间有关联。
rnn中batch的含义
如何理解RNN中的Batch_size?_batch rnn_Forizon的博客-CSDN博客
rnn解决的问题
- 不定长输入
- 带有顺序的序列输入
1 rnn前向传播

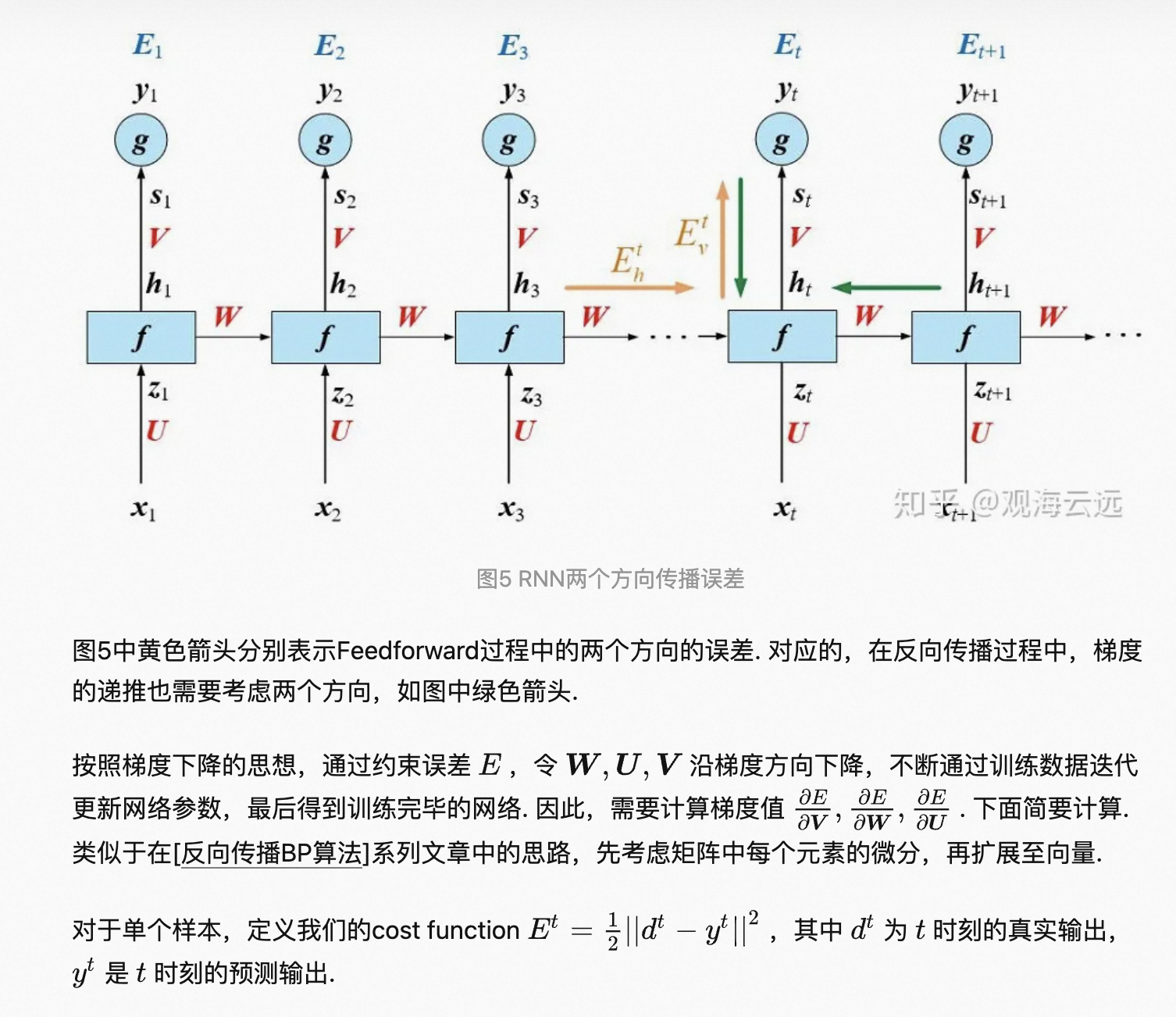
2 rnn中的反向传播

还有loss对其他参数的求导,较为复杂。
rnn容易出现梯度消失的问题,因为经过反向传播后,较远时间步的梯度趋近于0,导致模型难以学到远距离的信息。
2 lstm
优点:通过门控机制,来记忆一些长期信息,相应也就保留了更多的梯度,缓解rnn梯度消失的问题。
缺点:
- 无法并行,耗时
- 对于特别长的序列,梯度消失问题依然存在
- 参数多,计算耗时
3 cnn
cnn和rnn都是权值共享
cnn的特点:
- 1 局部连接,可以捕捉局部特征
- 2 参数共享,大大减小参数量,防止过拟合,提高模型的泛化性能
- 3 池化,减少特征数量,防止过拟合,使每个像素点的感受野被放大,更能捕获全局信息
卷积层虽然可以显著减少网络中连接的数量,但特征映射组中的神经元个数并没有显著减少。如果后面接一个分类器,分类器的输入维数依然很高,很容易过拟合。为了解决这个问题,可以再卷积层之后加上一个pooling layer,从而降低特征维数,避免过拟合。
优点:可以并行
缺点:1单个卷积层难以捕获全局信息(改善方法有使用更大的卷积核、使用池化层、使用多层卷积层、空洞卷积tcn用了因果空洞卷积来处理时间序列问题。
2卷积核从左往右滑动的时候捕获了相对位置关系,但是如果接池化层的话就会损失掉这些信息(所以一般不用池化层)
1x1卷积核的作用
- 1 改变通道数
- 2 增加一层非线性映射,使得网络提取更有判别信息的特征
cnn参数
- 卷积核尺寸
- stride:太小导致计算量大,效率低;太大可能会遗漏某些重要信息
- 空洞尺寸:提升感受野,但是也容易遗漏某些信息
- padding:让后续的特征图不至于太小,便于继续增加层数,提升模型的拟合能力;缓解最边缘的数据只被用了一次的问题,充分利用数据,从而提取有用特征。
4 transformer
优点:
- 可以提取全局信息(处理时间序列时可以捕捉长时间依赖)
- 可以并行计算
- 引入位置编码提取帮助提取位置信息
- 可以处理不定长的输入(rnn、cnn(不带全连接层)、transformer都有参数共享,有参数共享的一般都可以接受不定长的输入)。在一个batch中将所有序列padding到同一长度,方便对一个batch的数据进行矩阵的并行运算。其中的fnn是共享参数的point-wise,对一个序列的每个token都处理。因此transformer也可以处理不定长输入,只是为了方便并行计算而对每一个batch的数据进行padding