d2l 文本预处理textDataset

这一节极其重要,重要到本来是d2l的内容我也要归到pyhon封面,这里面class的操作很多,让我娓娓道来!
目录
1.要实现的函数
2.读取数据集
3.词元化
4.Vocab类
4.1count_corpus(tokens)
4.2class中的各种self
4.2.1 _token_freqs是经过sorted排序后的list
4.2.2 token_to_idx是{token:idx}的字典
4.2.3两大索引to_tokens与原getitem
4.2.4 idx_to_token是所有token按出现次数多到少排列的list
4.2.5其它
5.该函数最终返回的东西:
1.要实现的函数
整文都是围绕以下这个函数来展开的,因为后续就直接用了。包括返回的Vocab类:
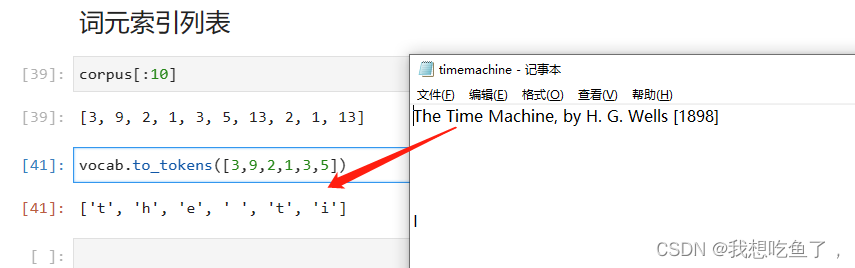
def load_corpus_time_machine(max_tokens=-1): #@save"""返回时光机器数据集的词元索引列表和词表"""lines = read_time_machine()tokens = tokenize(lines, 'char')vocab = Vocab(tokens)# 因为时光机器数据集中的每个⽂本⾏不⼀定是⼀个句⼦或⼀个段落,# 所以将所有⽂本⾏展平到⼀个列表中corpus = [vocab[token] for line in tokens for token in line]if max_tokens > 0:corpus = corpus[:max_tokens]return corpus, vocabcorpus, vocab = d2l.load_corpus_time_machine()
len(corpus), len(vocab)'''
(170580, 28)
'''2.读取数据集
re.sub('[^A-Za-z]+',' ', line).strip().lower()
re.sub表示将字符串中除了A-Z和a-z之外的所有字符用空格替换
.strip()表示去掉每一行首尾的换行符、空格、缩进等。注意只有首尾!!
.lower()表示结果转换为小写
def read_time_machine(): #@save"""将时间机器数据集加载到⽂本⾏的列表中"""with open(d2l.download('time_machine'), 'r') as f:lines = f.readlines()return [re.sub('[^A-Za-z]+', ' ', line).strip().lower() for line in lines]
lines = read_time_machine()
print(f'# ⽂本总⾏数: {len(lines)}')
print(lines[0])
print(lines[10])'''
# ⽂本总⾏数: 3221
the time machine by h g wells
twinkled and his usually pale face was flushed and animated the
'''3.词元化
输入的是原txt中,每一行为元素组成的list(['1','2',...])

将每个文本序列拆分成词元列表,看下处理代码:
def tokenize(lines, token='word'): #@save"""将⽂本⾏拆分为单词或字符词元"""if token == 'word':return [line.split() for line in lines]elif token == 'char':return [list(line) for line in lines]else:print('错误:未知词元类型:' + token)tokens = tokenize(lines)
for i in range(11):print(tokens[i])看一下最终得到的词元列表是什么:

以word,输入的是文本所有的行列表,得到的是二维列表,每一行为元素,该元素中包含该行中的每个单词为元素。
其中注意在char中,有一个list(line)操作:

对一个字符串使用list('zifuchuan')的时候,会把里面每个字母拆开返回,因为字符串是可迭代对象。
4.Vocab类
先上代码,再逐个讲解:
class Vocab:"""Vocabulary for text."""def __init__(self, tokens=None, min_freq=0, reserved_tokens=None):"""Defined in :numref:`sec_text_preprocessing`"""if tokens is None:tokens = []if reserved_tokens is None:reserved_tokens = []# Sort according to frequenciescounter = count_corpus(tokens)self._token_freqs = sorted(counter.items(), key=lambda x: x[1],reverse=True)# The index for the unknown token is 0self.idx_to_token = ['<unk>'] + reserved_tokensself.token_to_idx = {token: idx for idx, token in enumerate(self.idx_to_token)}for token, freq in self._token_freqs:if freq < min_freq:breakif token not in self.token_to_idx:self.idx_to_token.append(token)self.token_to_idx[token] = len(self.idx_to_token) - 1def __len__(self):return len(self.idx_to_token)def __getitem__(self, tokens):if not isinstance(tokens, (list, tuple)):return self.token_to_idx.get(tokens, self.unk)return [self.__getitem__(token) for token in tokens]def to_tokens(self, indices):if not isinstance(indices, (list, tuple)):return self.idx_to_token[indices]return [self.idx_to_token[index] for index in indices]@propertydef unk(self): # Index for the unknown tokenreturn 0@propertydef token_freqs(self): # Index for the unknown tokenreturn self._token_freqsdef count_corpus(tokens): # @save"""统计词元的频率"""# 这⾥的tokens是1D列表或2D列表if len(tokens) == 0 or isinstance(tokens[0], list):# 将词元列表展平成⼀个列表tokens = [token for line in tokens for token in line]return collections.Counter(tokens)4.1count_corpus(tokens)
这里面tokens魔法函数:tokens = [token for line in tokens for token in line],等价于如下命令:
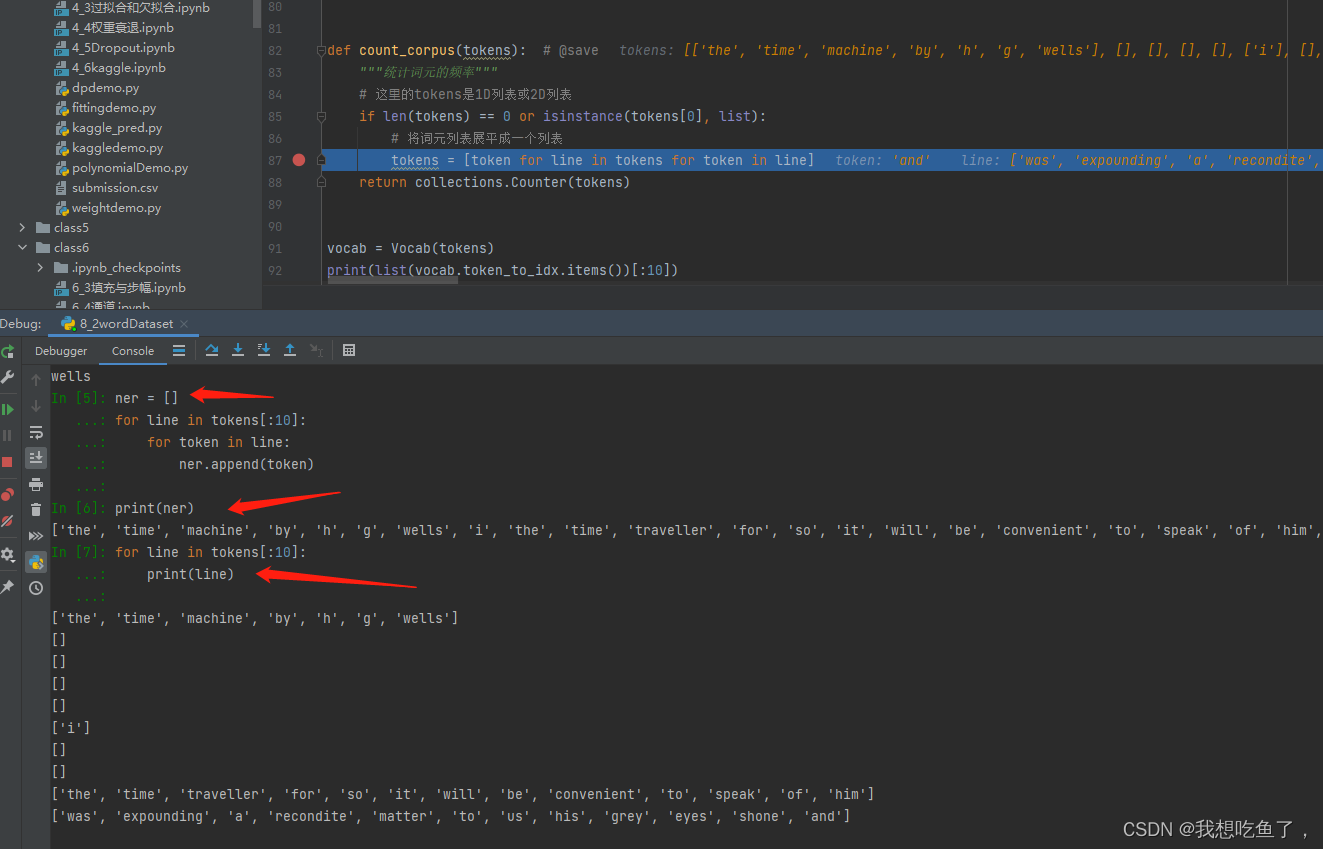
在外面套一个list相当于先创建一个空list,然后依次将返回的最终元素append到这个空list中
其中第一个for loop读取2Dlist中的每个元素,即为每一行;第二个for读取的是每一行中的每一个字符,此时这个token表示的是2Dlist中每个元素list里的每一个字符元素,再通过append添加到新创的list中
对于之后的Counter用处:
举例来说,如果 tokens = ['apple', 'banana', 'apple', 'orange'],则 collections.Counter(tokens) 的结果为 Counter({'apple': 2, 'banana': 1, 'orange': 1}),表示列表中有 2 个 'apple'、1 个 'banana' 和 1 个 'orange'。在自然语言处理中,collections.Counter() 经常被用于统计单词的出现次数。
也就是传入所有词的列表(拉成了一维),然后返回一个dict,key为上个list的元素名,对应value为该key的出现次数。
4.2class中的各种self
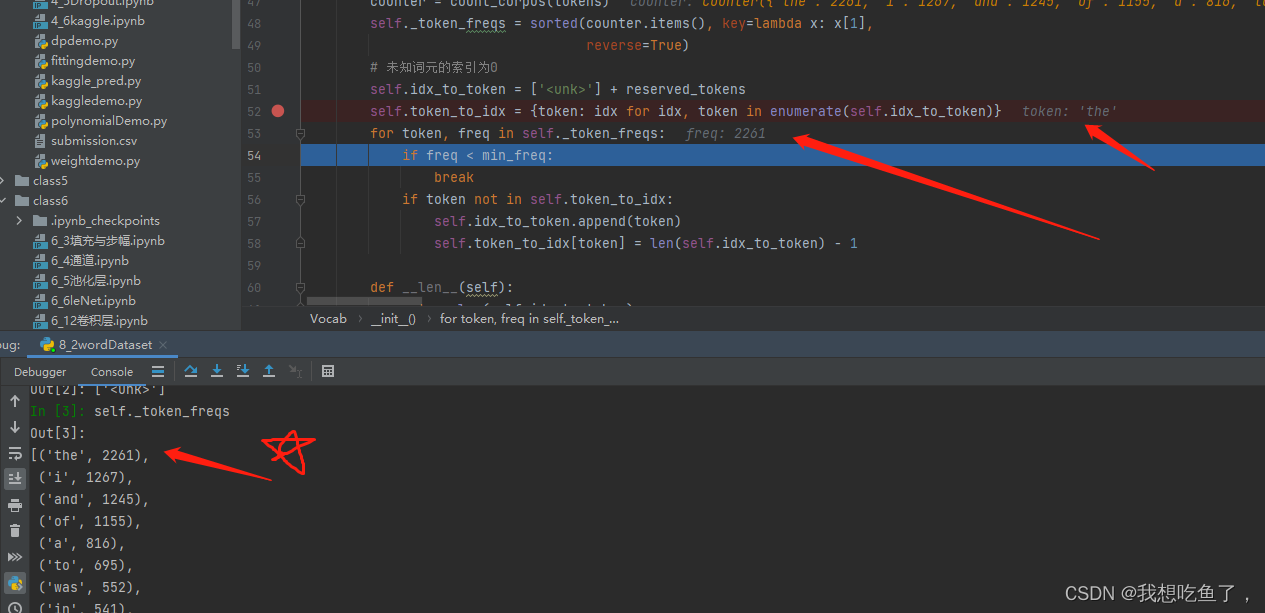
4.2.1 _token_freqs是经过sorted排序后的list
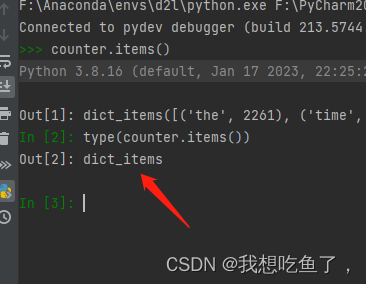
注意传入sorted是要传入dict,所以源码中对counter进行了.item()处理:
在此可得: .items()是将字典返回一个包含所有(key-value)元组为元素的列表,可用于sorted!
vocab.token_freqs'''
[(' ', 29927),('e', 17838),('t', 13515),('a', 11704),('i', 10138),...]
'''4.2.2 token_to_idx是{token:idx}的字典
vocab.token_to_idx'''
{'<unk>': 0,' ': 1,'e': 2,'t': 3,'a': 4,...]
'''对应4.2.1说的.item()处理:
items()是将字典返回一个包含所有(key-value)元组为元素的列表

4.2.3两大索引to_tokens与原getitem
to_tokens是传入idx返回token
vocab.to_tokens((0,1,2,3))'''
['<unk>', ' ', 'e', 't']
'''getitem是传入token返回idx
vocab[('a','b','d')]'''
[4, 21, 11]
'''4.2.4 idx_to_token是所有token按出现次数多到少排列的list
vocab.idx_to_token[:10]'''
['<unk>', ' ', 'e', 't', 'a', 'i', 'n', 'o', 's', 'h']
'''4.2.5其它
list里面套两个元素的元组,用两个元素遍历,则会返回元组里面的两个元素!!
5.该函数最终返回的东西:
返回的是词元索引(将原txt按顺序依次返回索引对应原文内容的idx),还有语料库,可以用to_tokens返回对应索引的token。