Regressing Heatmaps for Multiple Landmark Localization Using CNNs阅读笔记

最早在医学landmark detection里用heatmap的
代码:https://github.com/christianpayer/MedicalDataAugmentationTool-HeatmapRegression
这里的代码是他们之后medical image anaylsis的
tf的看着挺难受的
摘要
作者使用了heatmap来进行landmark detection
提出了SpatialConfiguration-Net(SCN),将局部heatmap和全局空间信息结合
引言
为了能解决假阳性问题,最新(2016)的做法是局部特征+全局landmark空间信息
Heatmap Regression Using CNNs
这里用高斯heatmap,每个landmark对应一个heatmap,最后通过取最大值得到landmark坐标
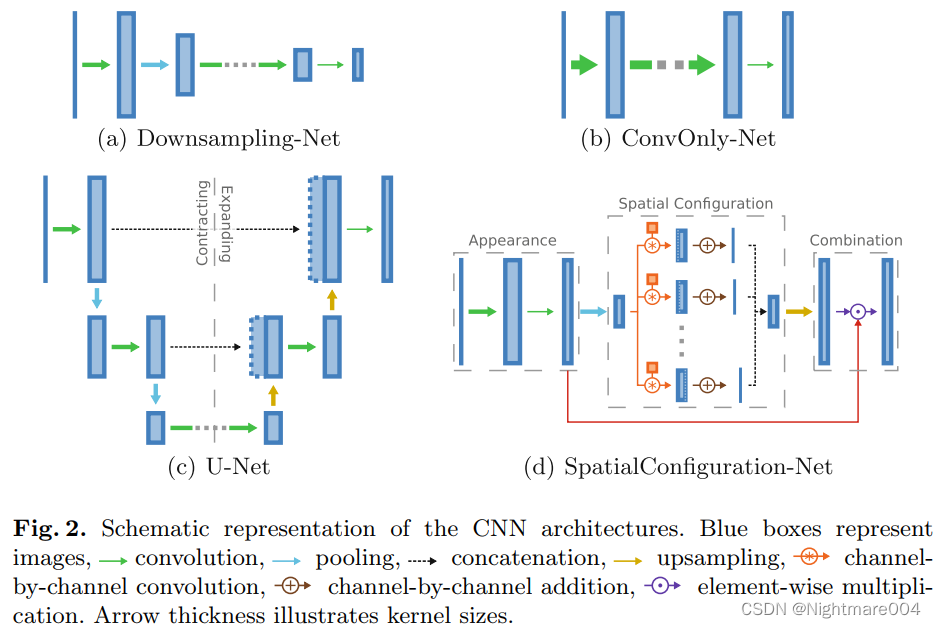
Downsampling-Net
交替使用卷积和下采样
缺点:得到的heatmap分辨率低,因此结果不准确
ConvOnly-Net
只使用卷积
但是这里不用步长>1的卷积,也不用池化,因此可能需要更大的卷积核才能达到前面Downsampling-Net的感受野
Unet
与原版Unet相比,将最大池化换成平均池化,将反卷积换成上采样
SCN
首先通过3层卷积,得到每个landmark LiL_iLi的局部的heatmapHiapp\\mathbf{H}_i^{app}Hiapp
尽管局部的heatmap非常准确,但是他们可能分不出来一些相似的点,例如指尖
(如下图,理想情况肯定是只有一个亮的地方)

作者想要通过结合其他的landmark,来消除这种相似
作用通过较大的卷积核Ki,jK_{i,j}Ki,j来学习LiL_iLi的相对LjL_jLj的位置,将HjappH_j^{app}Hjapp通过Ki,jK_{i,j}Ki,j变成Hi,jtransH_{i,j}^{trans}Hi,jtrans,即
Hi,jtrans=Hjapp∗Ki,jH_{i,j}^{trans} = H_j^{app} *K_{i,j} Hi,jtrans=Hjapp∗Ki,j
其中∗*∗表示卷积
之后将Hi,jtransH_{i,j}^{trans}Hi,jtrans相加
Hiacc=∑j=1nHi,jtransH_i^{acc} = \\sum_{j=1}^{n}H_{i,j}^{trans} Hiacc=j=1∑nHi,jtrans
最后按元素乘,得到最终的heatmap:
Hi=Hiapp⊙HiaccH_i = H_i^{app} \\odot H_i^{acc} Hi=Hiapp⊙Hiacc

spatial configuration block在一个较低的分辨率上进行,因为只需要相对位置信息,不需要太高的分辨率
最后在按元素乘之前会上采样,保证分辨率一样
实验
数据集
作者采用了一个2d的和一个3d的数据集
2d:895张平均尺寸1563×21691563\\times 21691563×2169的图,37个landmark,假设手腕50mm50mm50mm
3d:60张MR T1, 294×512×72294 \\times 512 \\times 72294×512×72,28个landmark, 0.45×0.45×0.9mm30.45 \\times 0.45 \\times 0.9 mm^30.45×0.45×0.9mm3
模型
ConvOnly-Net
6个卷积层,卷积核大小(2d: 11×1111\\times 1111×11, 3d:5×5×55 \\times 5 \\times 55×5×5)
Downsampling-Net
两次卷积+一次池化,最后一个模块后面又两个额外的卷积层
2d:5×55\\times 55×5卷积核,2个下采样模块
3d:3×3×33\\times 3 \\times 33×3×3卷积核,层下采样
UNet
2d:3×33\\times 33×3卷积,4层下采样
3d:3×3×33\\times 3\\times 33×3×3卷积,3层下采样
SCN
2d:前面3层卷积是5×55\\times 55×5的,后面是15×1515\\times 1515×15卷积以及8倍下采样(应该是spatial configuration block之前下采样)
3d:前面3层卷积是3×3×33\\times 3\\times 33×3×3的,后面是9\\times 9\\times 5$卷积以及4倍下采样
实验结果
实验分两部分,一个是完整的数据集,
另一个是再2d数据集上,只使用10张数据
red表示reduce
可以看到再完整数据集上,他们的模型最轻,但是效果其实并不是最好的
再reduce上,他们效果比Unet好
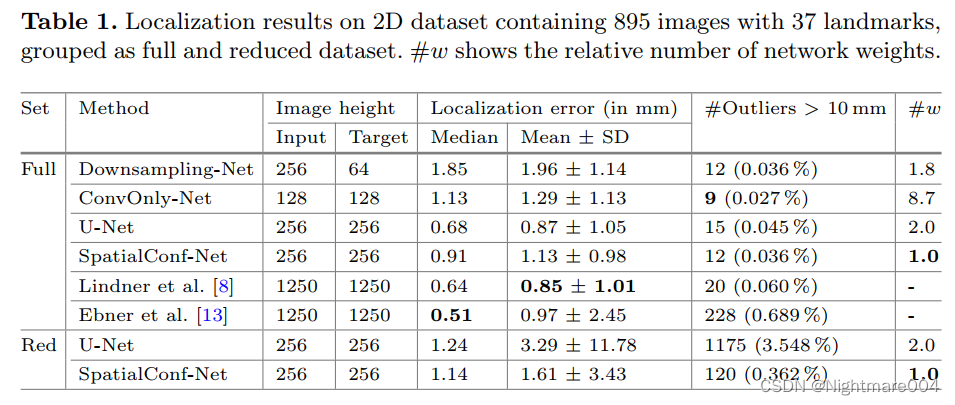
3d数据集上,他们效果最好