大数据应用——hbase shell操作

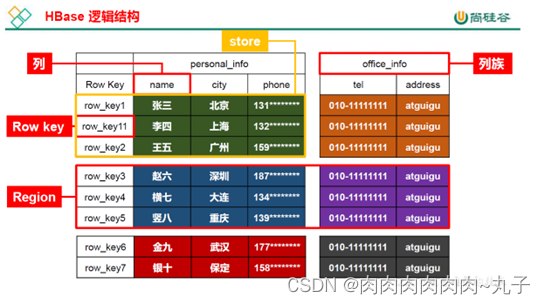
HBase 逻辑结构
HBase 物理存储结构

数据模型
1)Name Space
命名空间,类似于关系型数据库的 DatabBase概念,每个命名空间下有多个表。HBase
有两个自带的命名空间,分别是 hbase 和 default
hbase 中存放的是 HBase 内置的表,
default表是用户默认使用的命名空间。
2)Region
类似于关系型数据库的表概念。不同的是,HBase定义表时只需要声明列族即可,不需
要声明具体的列。这意味着,往 HBase写入数据时,字段可以动态、按需指定。因此,和关
系型数据库相比,HBase能够轻松应对字段变更的场景。
3)Row
HBase表中的每行数据都由一个 RowKey和多个 Column(列)组成,数据是按照 RowKey
的字典顺序存储的,并且查询数据时只能根据 RowKey进行检索,所以 RowKey的设计十分重
要。
4)Column
HBase中的每个列都由 Column Family(列族)和 Column Qualifier(列限定符)进行限
定,例如 info:name,info:age。建表时,只需指明列族,而列限定符无需预先定义。
5)Time Stamp
用于标识数据的不同版本(version),每条数据写入时,如果不指定时间戳,系统会
自动为其加上该字段,其值为写入 HBase的时间。
6)Cell
由{rowkey, column Family:column Qualifier, time Stamp} 唯一确定的单元。cell 中的数
据是没有类型的,全部是字节码形式存贮。
自带的命名空间:
- hbase 存放的是HBase内置的表
- default 表是用户默认使用的命名空间
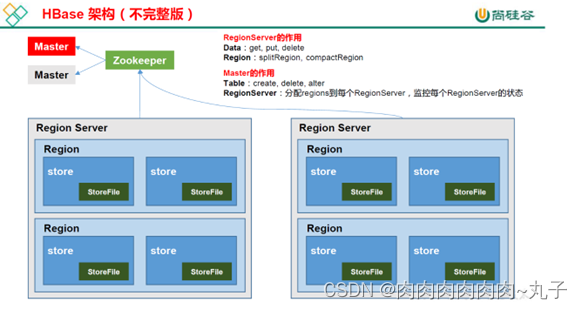
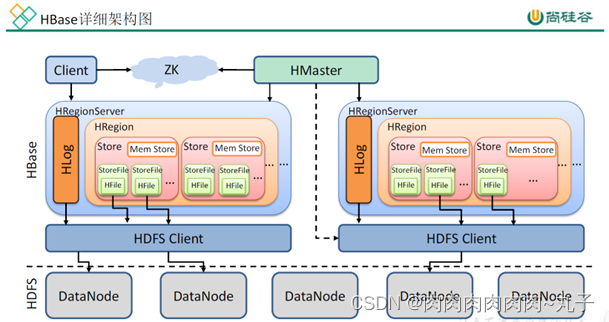
- HBase 基本架构
架构角色:
1)Region Server
Region Server为 Region的管理者,其实现类为 HRegionServer,主要作用如下:
对于数据的操作:get, put, delete;
对于 Region的操作:splitRegion、compactRegion。
2)Master
Master是所有 Region Server的管理者,其实现类为 HMaster,主要作用如下:
对于表的操作:create, delete, alter
对于 RegionServer的操作:分配 regions到每个 RegionServer,监控每个 RegionServer
的状态,负载均衡和故障转移。
3)Zookeeper
HBase 通过 Zookeeper 来做 Master 的高可用、RegionServer 的监控、元数据的入口以及
集群配置的维护等工作。
4)HDFS
HDFS 为 HBase 提供最终的底层数据存储服务,同时为 HBase 提供高可用的支持。
DML(data manipulation language) create alter drop delte
DDL(data definition language)put del scan/get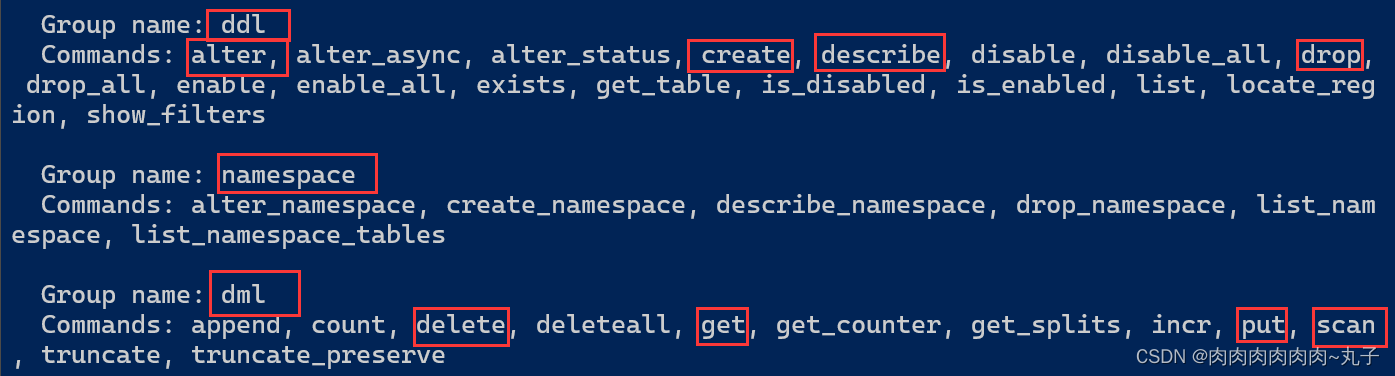
用户命名空间:list_
默认命名空间:bigdata

1.scan
scan命令可以按照rowkey的字典顺序来遍历指定的表的数据。
scan ‘表名’:默认当前表的所有列族。
scan ‘表名’,{COLUMNS=> [‘列族:列名’],…} : 遍历表的指定列
scan '表名', { STARTROW => '起始行键', ENDROW => '结束行键' }:指定rowkey范围。
如果不指定,则会从表的开头一直显示到表的结尾。区间为左闭右开。
scan '表名', { LIMIT => 行数量}: 指定返回的行的数量
scan '表名', {VERSIONS => 版本数}:返回cell的多个版本
scan '表名', { TIMERANGE => [最小时间戳, 最大时间戳]}:指定时间戳范围
注意:此区间是一个左闭右开的区间,因此返回的结果包含最小时间戳的记录,但是不包含最大时间戳记录
scan '表名', { RAW => true, VERSIONS => 版本数}
显示原始单元格记录,在Hbase中,被删掉的记录在HBase被删除掉的记录并不会立即从磁盘上清除,而是先被打上墓碑标记,然后等待下次major compaction的时候再被删除掉。
注意RAW参数必须和VERSIONS一起使用,但是不能和COLUMNS参数一起使用。

scan '表名', { FILTER => "过滤器"} and|or { FILTER => "过滤器"}: 使用过滤器扫描
HBase(main):008:0> scan 'bigdata:stu1'

HBase(main):009:0> scan 'bigdata:stu1',{STARTROW => '1000', STOPROW => '1001'}

HBase(main):010:0> scan 'bigdata:stu1',{STARTROW => '1001'}

2.put
put可以新增记录还可以为记录设置属性。
put '表名', '行键', '列名', '值'
put '表名', '行键', '列名', '值',时间戳
put '表名', '行键', '列名', '值', { '属性名' => '属性值'}
put '表名', '行键', '列名', '值',时间戳, { '属性名' =>'属性值'}
HBase(main):012:0> put 'bigdata:stu1','1000','info:name','xm'

HBase(main):003:0> put 'bigdata:stu1','1000','info:name','xh'

HBase(main):004:0> put 'bigdata:stu1','1000','info:name','xl'

HBase(main):005:0> put 'bigdata:stu1','1000','info:name','xb'

HBase(main):006:0> put 'bigdata:stu1','1000','info:name','xt'

3.get
get支持scan所支持的大部分属性,如COLUMNS,TIMERANGE,VERSIONS,FILTER
HBase(main):014:0> get 'stu1','1001'
HBase(main):015:0> get 'stu1','1001','info:name'
4.describe
HBase(main):016:0> describe ‘bigdata:stu1’