【数据库】Redis数据类型详解

目录
- 一、5种基本数据类型
-
- 1. String
- 2. List
- 3. Hash
- 4. Set
- 5. ZSet
- 二、3种特殊类型
-
- 1. Bitmap
- 2. HyperLogLog
- 3. Geospatial index
一、5种基本数据类型
-
Redis 共有 5 种基本数据结构:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)
-
这 5 种数据结构底层实现主要依赖这 8 种数据结构:简单动态字符串(SDS)、LinkedList(双向链表)、Hash Table(哈希表)、SkipList(跳跃表)、Intset(整数集合)、ZipList(压缩列表)、QuickList(快速列表)
Redis 基本数据结构的底层数据结构实现如下:
| String | List | Hash | Set | Zset |
|---|---|---|---|---|
| SDS | LinkedList/ZipList/QuickList | HashTable、ZipList | ZipList、Intset | ZipList、SkipList |
1. String
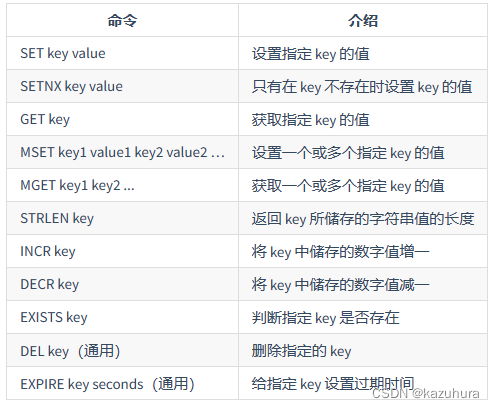
- 常用命令
- 底层实现:SDS 简单动态字符串
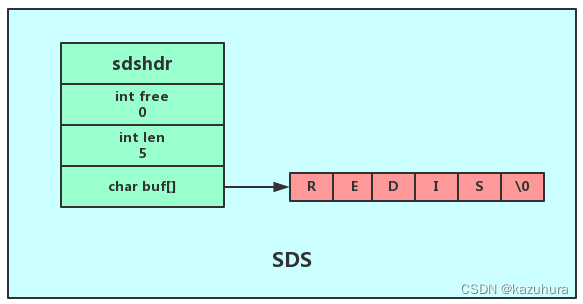
struct sdshdr{//int 记录buf数组中未使用字节的数量 如上图free为0代表未使用字节的数量为0int free;//int 记录buf数组中已使用字节的数量即sds的长度 如上图len为5代表未使用字节的数量为5int len;//字节数组用于保存字符串 sds遵循了c字符串以空字符结尾的惯例目的是为了重用c字符串函数库里的函数char buf[];
}c
- SDS与C字符串的区别(优势)
- 获取字符串的长度只需O(1)
- 不会发生缓冲区溢出的情况
- 减少内存重新分配次数:
- 空间预分配:预先分配比实际请求的还要大的空间
- 惰性空间释放:不是立即使用内存重分配来回收缩短出来的字节,而是使用free属性记录起来,并等待将来使用
- 二进制安全:不会产生错误识别\\0的情况
2. List
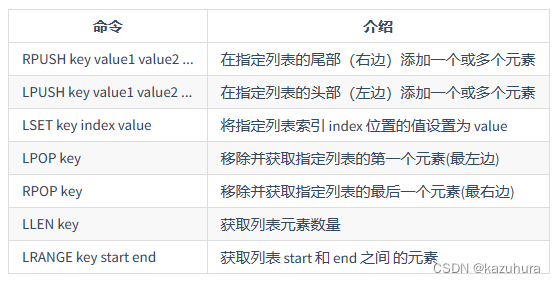
- 常用命令
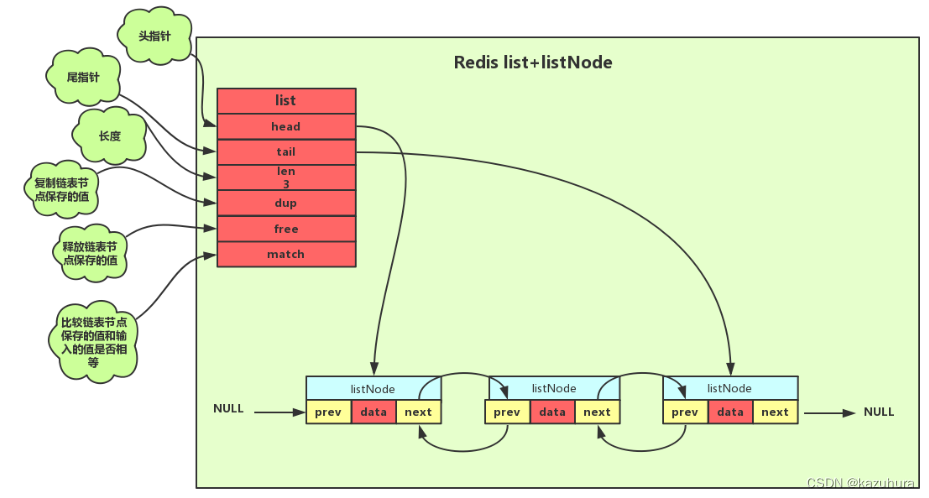
- 底层实现:双向链表
3. Hash
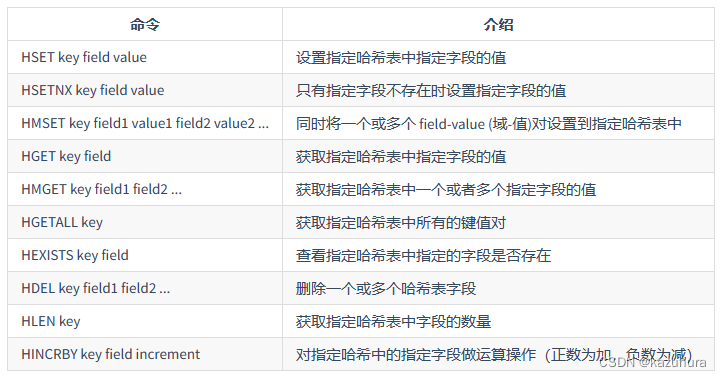
- 常用命令
- 底层实现:散列表,两个
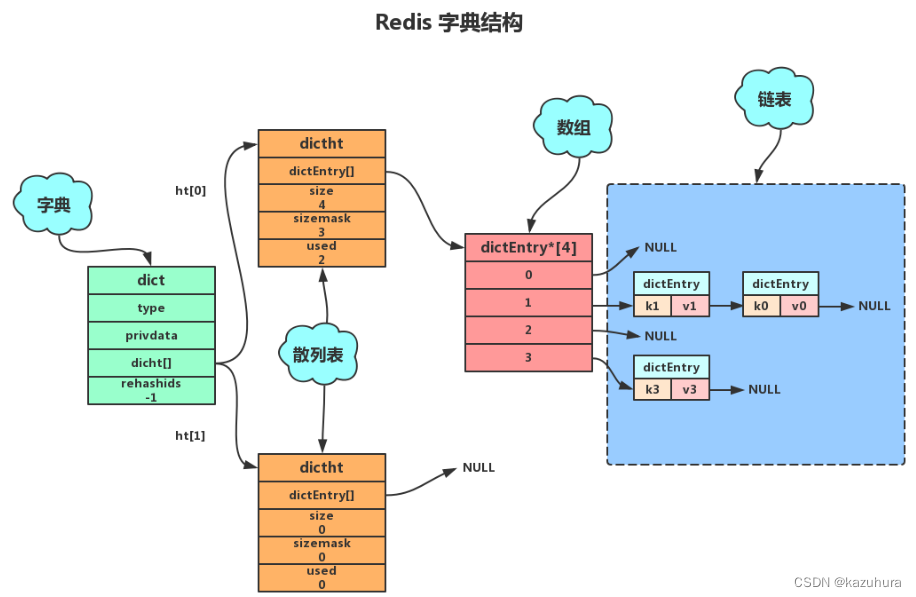
typedef struct dict{//类型特定函数dictYType *type;//私有数据void *privdata;//哈希表-见2.1.2dictht ht[2];//rehash 索引 当rehash不在进行时 值为-1int trehashidx;
}dict;
- rehash
包含两个哈希表 dictht,这是为了方便进行 rehash 操作。在扩容时,将其中一个 dictht 上的键值对 rehash 到另一个 dictht 上面,完成之后释放空间并交换两个 dictht 的角色
typedef struct dict {dictType *type;void *privdata;dictht ht[2];long rehashidx; /* rehashing not in progress if rehashidx == -1 */unsigned long iterators; /* number of iterators currently running */
} dict;
rehash 操作不是一次性完成,而是采用渐进方式,这是为了避免一次性执行过多的 rehash 操作给服务器带来过大的负担。
渐进式 rehash 通过记录 dict 的 rehashidx 完成,它从 0 开始,然后每执行一次 rehash 都会递增。例如在一次 rehash 中,要把 dict[0] rehash 到 dict[1],这一次会把 dict[0] 上 table[rehashidx] 的键值对 rehash 到 dict[1] 上,dict[0] 的 table[rehashidx] 指向 null,并令 rehashidx++。
在 rehash 期间,每次对字典执行添加、删除、查找或者更新操作时,都会执行一次渐进式 rehash。
采用渐进式 rehash 会导致字典中的数据分散在两个 dictht 上,因此对字典的查找操作也需要到对应的 dictht 去执行。
4. Set
- 常用命令

- 底层实现:Intset
当一个集合只包含整数值元素,并且这个集合的元素数量不多时, Redis i就会使用整数集合作为集合键的底层实现
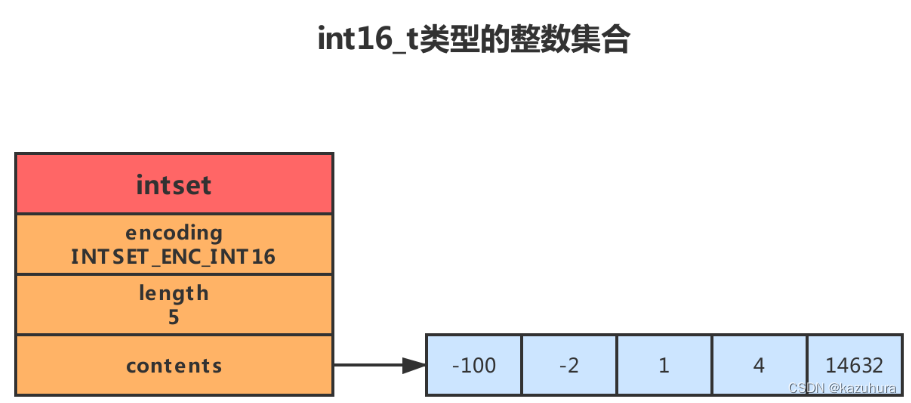
//每个intset结构表示一个整数集合
typedef struct intset{//编码方式uint32_t encoding;//集合中包含的元素数量uint32_t length;//保存元素的数组int8_t contents[];
} intset;
5. ZSet
Sorted Set 类似于 Set,但和 Set 相比,Sorted Set 增加了一个权重参数 score,使得集合中的元素能够按 score 进行有序排列,还可以通过 score 的范围来获取元素的列表。有点像是 Java 中 HashMap 和 TreeSet 的结合体
-
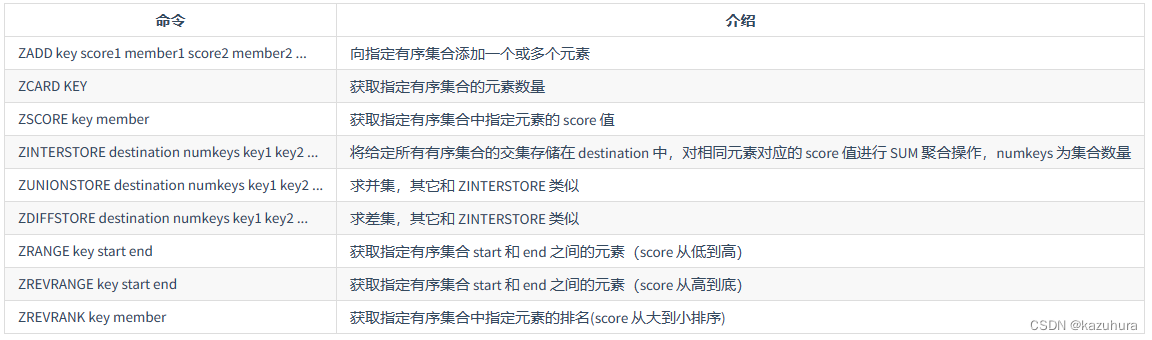
常用命令
-
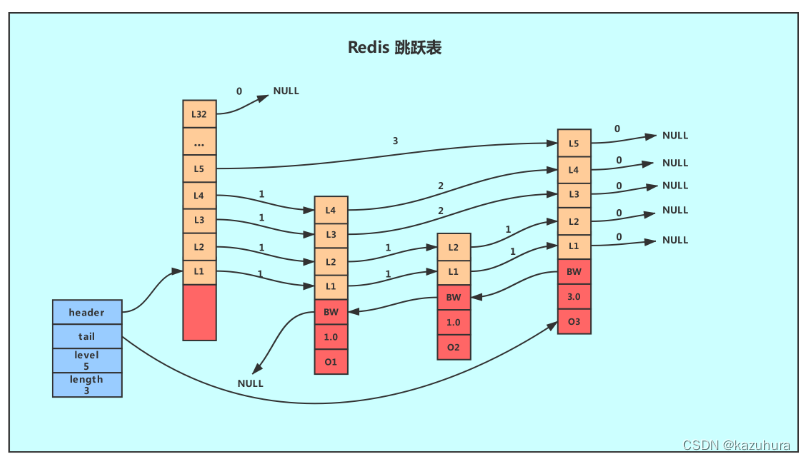
底层结构:跳表skipList
相当于链表的多级索引
-
压缩列表 ZipSet
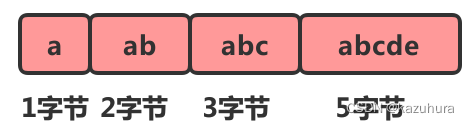
听到“压缩”两个字,直观的反应就是节省内存。之所以说这种存储结构节省内存,是相较于数组的存储思路而言的。我们知道,数组要求每个元素的大小相同,如果我们要存储不同长度的字符串,那我们就需要用最大长度的字符串大小作为元素的大小(假设是20个字节)。存储小于 20 个字节长度的字符串的时候,便会浪费部分存储空间

数组的优势占用一片连续的空间可以很好的利用CPU缓存访问数据。如果我们想要保留这种优势,又想节省存储空间我们可以对数组进行压缩。
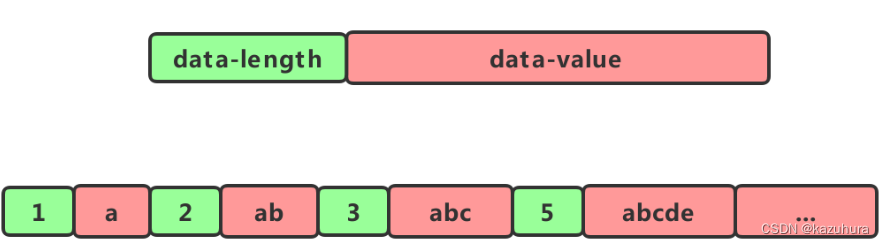
但是这样有一个问题,我们在遍历它的时候由于不知道每个元素的大小是多少,因此也就无法计算出下一个节点的具体位置。这个时候我们可以给每个节点增加一个lenght的属性。
二、3种特殊类型
除了 5 种基本的数据结构之外,Redis 还支持 3 种特殊的数据结构 :Bitmap、HyperLogLog、GEO
1. Bitmap
Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身 。我们知道 8 个 bit 可以组成一个 byte,所以 Bitmap 本身会极大的节省储存空间。
你可以将 Bitmap 看作是一个存储二进制数字(0 和 1)的数组,数组中每个元素的下标叫做 offset(偏移量)
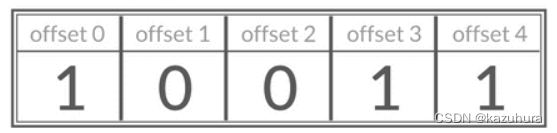
-
常用命令

-
应用场景
需要保存状态信息(0/1 即可表示)的场景
举例 :用户签到情况、活跃用户情况、用户行为统计(比如是否点赞过某个视频)
2. HyperLogLog
用来做基数统计,基数统计:统计一个集合中不重复元素的个数
Redis 提供的 HyperLogLog 占用空间非常非常小,只需要 12k 的空间就能存储接近2^64个不同元素
- 常用命令

-
应用场景
数量量巨大(百万、千万级别以上)的计数场景
举例 :热门网站每日/每周/每月访问 ip 数统计、热门帖子 uv 统计
3. Geospatial index
Geospatial index(地理空间索引,简称 GEO) 主要用于存储地理位置信息,基于 Sorted Set 实现。
通过 GEO 我们可以轻松实现两个位置距离的计算、获取指定位置附近的元素等功能。
- 常用命令

-
应用场景
需要管理使用地理空间数据的场景
举例:附近的人