MapReduce

MapReduce设计理念
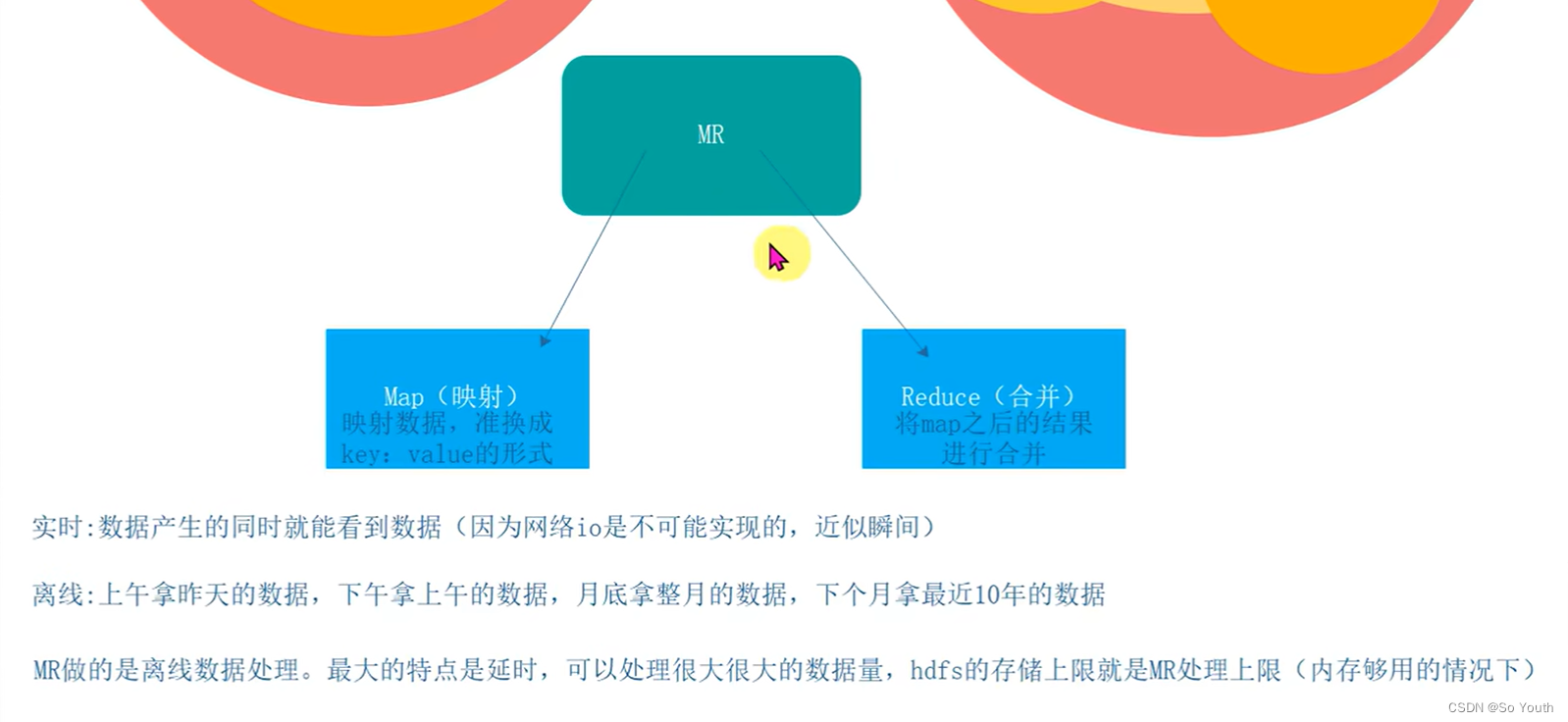
map-->映射(key value)
reduce-->归纳
mapreduce必须构建在hdfs之上一种大数据离线计算框架在线:实时数据处理离线:数据处理时效性没有在线那么强,但是相对也需要很快得到结果
mapreduce不会马上得到结果,他会有一定的延时如果数据量小,使用mapreduce反而不合适
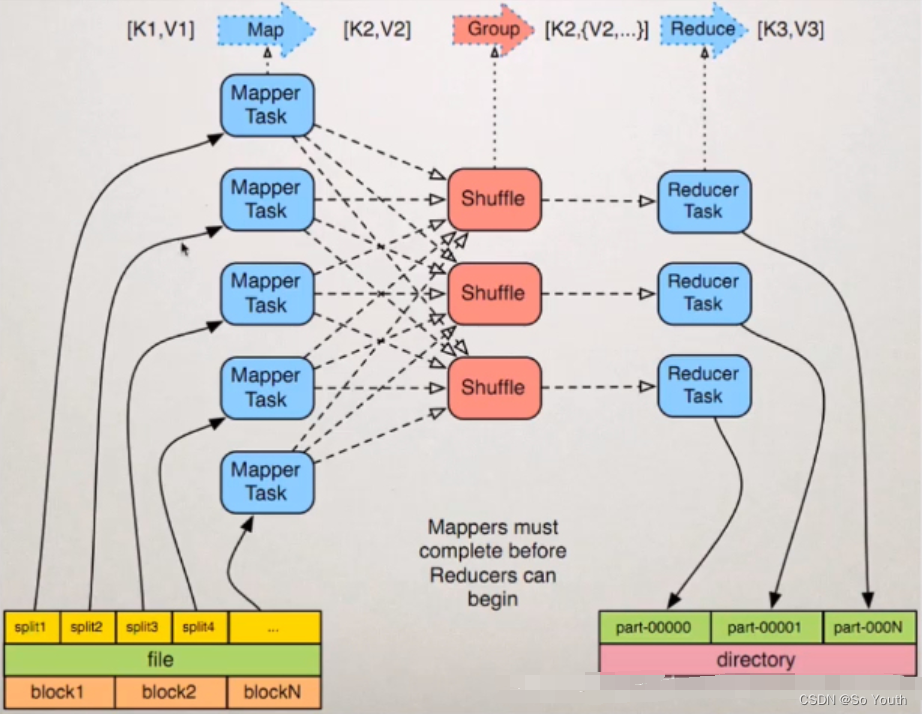
原始数据-->map(Key,Value)-->Reduce
分布式计算将大的数据切分成多个小数据,交给更多的节点参与运算
计算向数据靠拢将计算传递给有数据的节点上进行工作
MapReduce架构
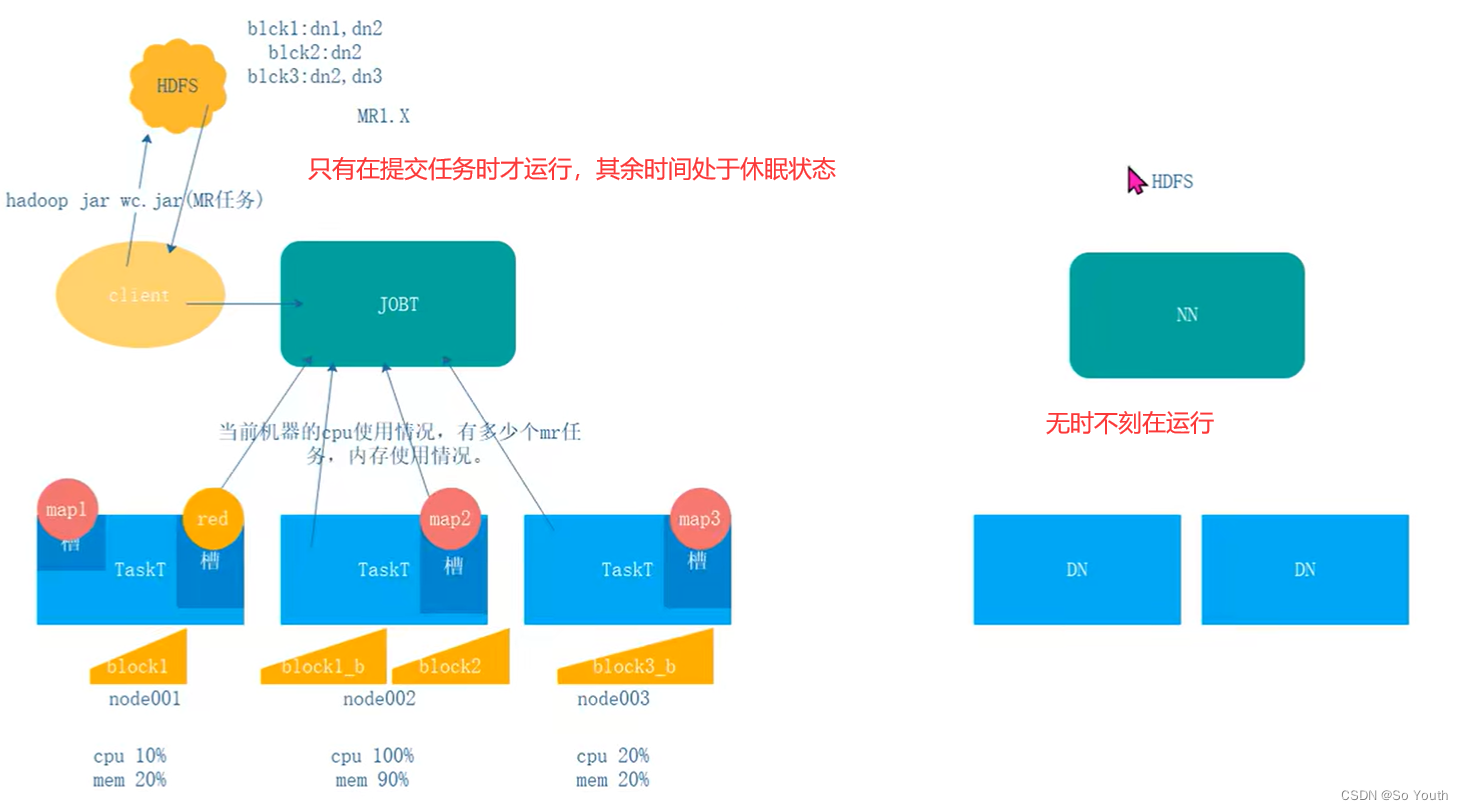
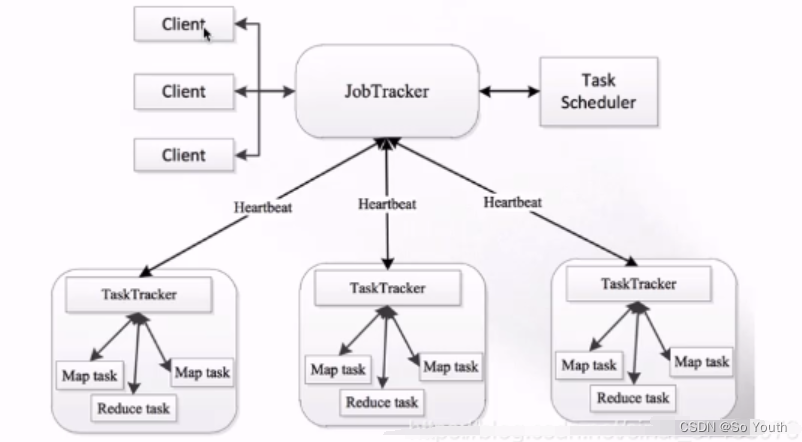
MapReduce1.x
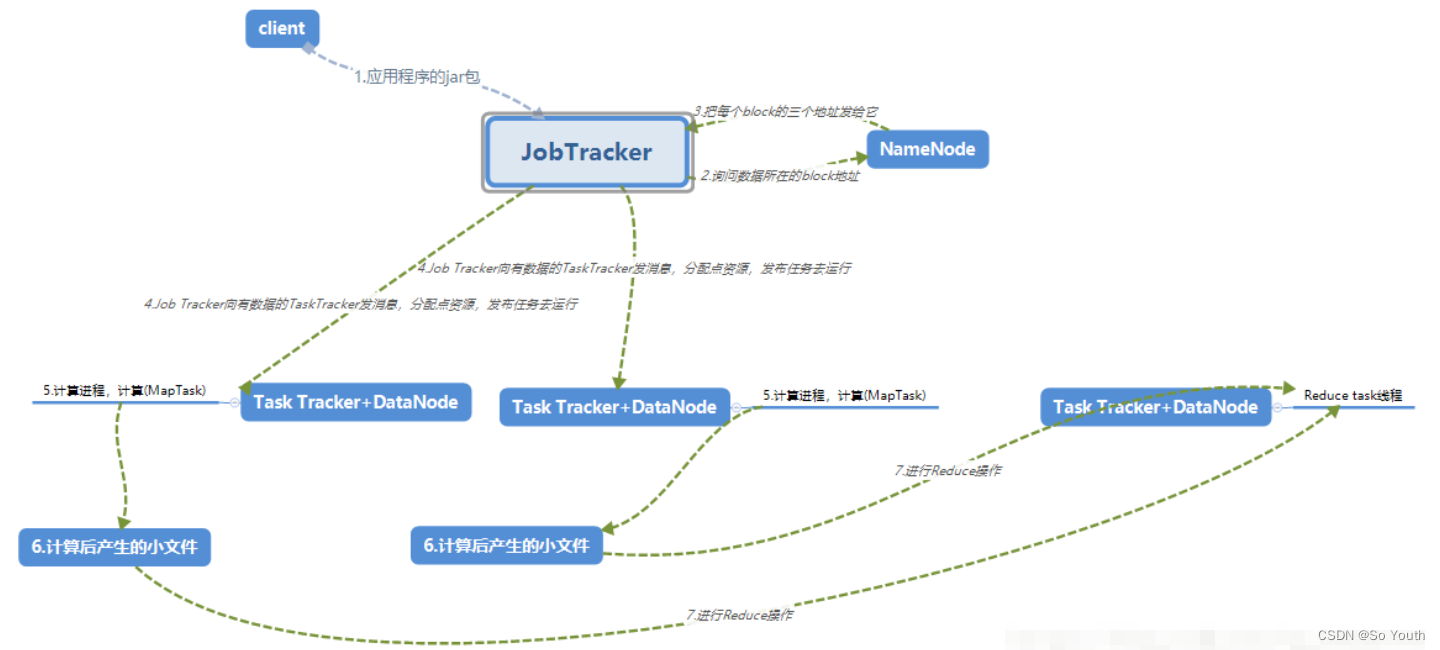
client客户端发送mr任务到集群客户端的种类有很多种hadoop jar wordcount.jar
JobTracker作业的管理者:接受客户端的mr任务将作业分解成一堆任务:Task(MapTask和ReduceTask)将任务分派给TaskTracker运行作业的监控、容错处理(task挂了,重启task机制)与TaskTracker保持心跳,接受汇报信息:在一定时间间隔内,JT没有收到TT的心跳信息,TT可能挂了,TT上运行的任务会被指派到其他TT上执行TaskTracker任务的执行者:在TT上执行Task(MapTask和ReduceTask),实时监控并汇报(资源情况、健康状态)保持心跳:发送心跳信息给JT
Slot(槽)属于JobTracker分配的资源不管任务大小,资源是恒定的,不灵活但是好管理
Task(MapTask--ReduceTask)开始按照MR的流程执行业务当任务完成时,JobTracker告诉TaskTracker回收资源
缺点:单点故障内存扩展业务瓶颈只能执行MR的操作如果其他框架需要运行在Hadoop上,需要独立开发自己的资源调度框架
各种颜色的豆子,统计每种豆子数目(类似)
MapReduce2.x
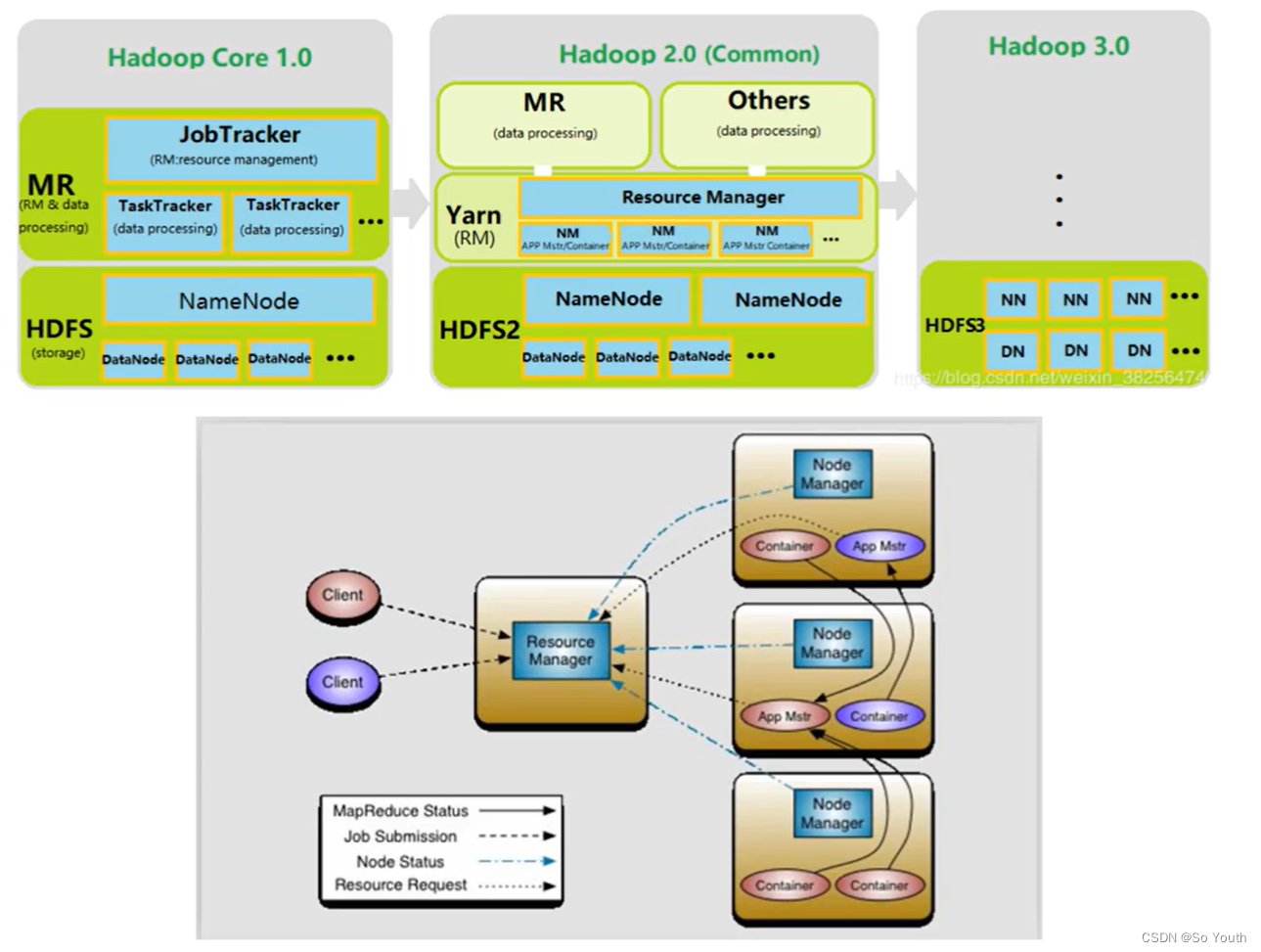
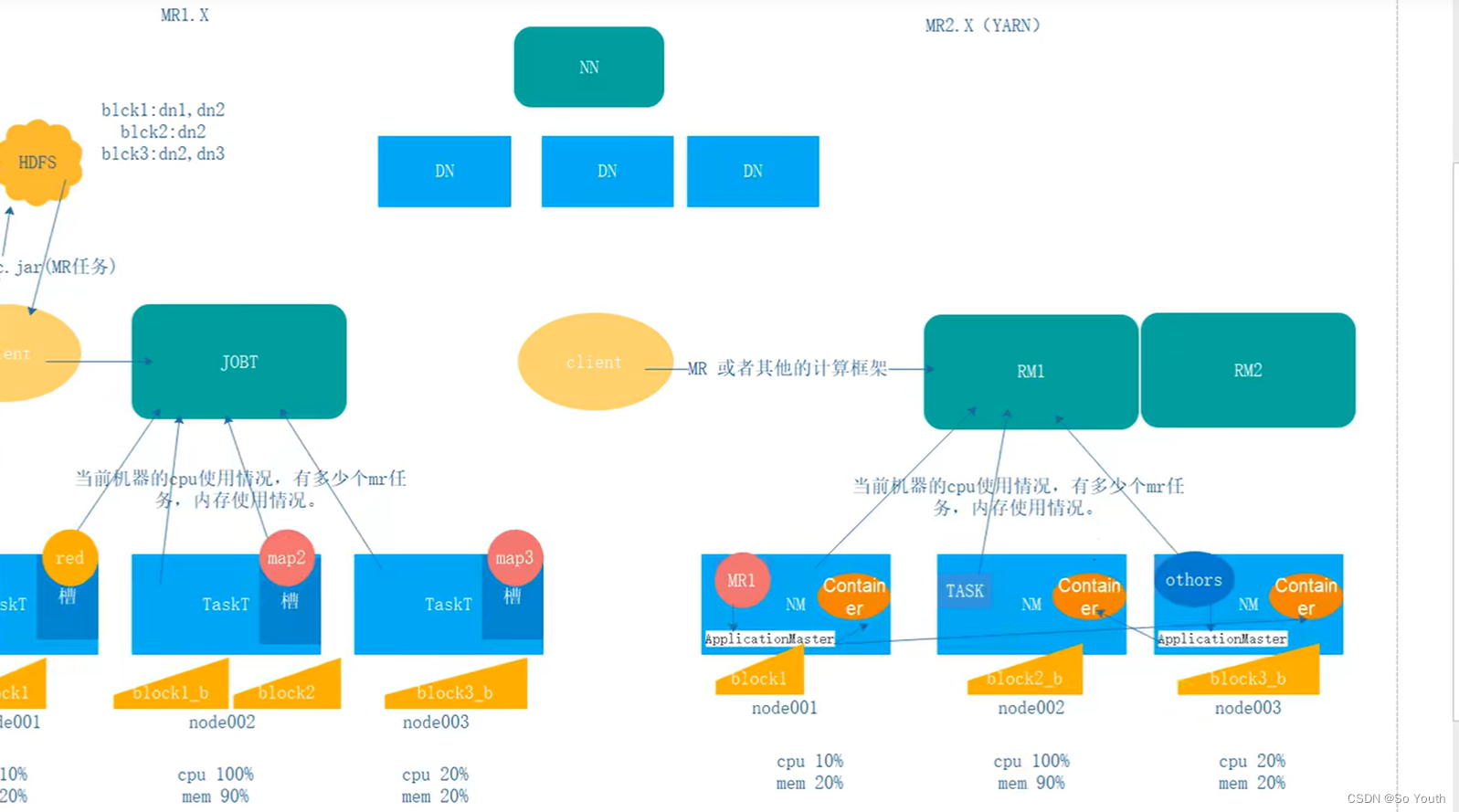
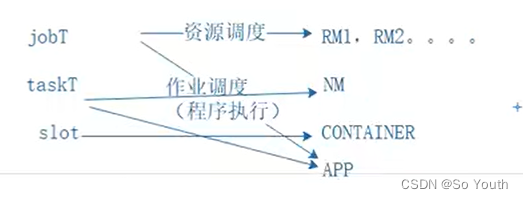
2.x开始使用Yarn(Yet Another Resource Negotiator,另一种资源协调者)统一管理资源
以后其他的计算框架可以直接访问yarn获取当前集群的空闲节点
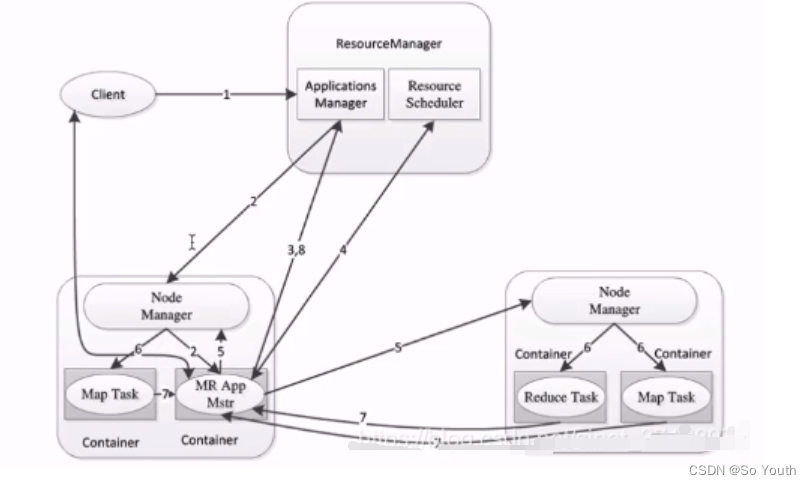
没有了JobTracker和TaskTracker,出现了Resoure manager和Node manager。
client客户端发送mr任务到集群客户端的种类有很多种hadoop jar wordcount.jar
ResourceManager资源协调框架的管理者分为主节点和备用节点(防止单点故障)主备的切换基于Zookeeper进行管理时刻与NodeManager保持心跳,接受NodeManager的汇报NodeManager汇报当前节点的资源情况当有外部框架要使用资源的时候直接访问ResourceManager即可如果有MR任务,先去ResourceManager申请资源,ResourceManager根据汇报相对灵活分配资源资源在NodeManager1,NodeManager1要负责开辟资源
NodeManagerYet Another Resource Negotiator(另一种资源协调者)资源协调框架的执行者每一个DataNode上默认有一个NodeManagerNodeManager汇报自己的信息到ResourceManager
Container (开辟空间的名字)2.x资源的代名词Container动态分配的
ApplicationMaster我们本次JOB任务的主导者负责调度本次被分配的资源Container (将MR划分为多个并分配执行)当所有的节点任务全部完成,application告诉ResourceManager请求杀死当前ApplicationMaster线程本次任务所有的资源都会被释放
Task(MapTask--ReduceTask)开始按照MR的流程执行业务当任务完成时,ApplicationMaster接收到当前节点的回馈
Hadoop搭建yarn环境

yarn环境搭建基于HA环境
[root@node001 ~]# jps
[root@node001 ~]# stop-dfs.sh (关闭集群,zookeeper可以不关)
[root@node001 ~]# vim /opt/hadoop-3.1.2/etc/hadoop/hadoop.env.shexport JAVA_HOME=/usr/java/jdk1.8.0_231-amd64export HDFS_NAMENODE_USER=rootexport HDFS_DATANODE_USER=rootexport HDFS_ZKFC_USER=rootexport HDFS_JOURNALNODE_USER=rootexport YARN_RESOURCEMANAGER_USER=rootexport YARN_NODEMANAGER_USER=root
[root@node001 ~]# vim /opt/hadoop-3.1.2/etc/hadoop/mapred-site.xml
mapred-site.xml
<!-- 指定mr框架为yarn方式 -->
<property><name>mapreduce.framework.name</name><value>yarn</value>
</property>
<!-- 指定mapreduce jobhistory地址 -->
<property><name>mapreduce.jobhistory.address</name><value>node001:10020</value>
</property>
<!-- 任务历史服务器的web地址 -->
<property><name>mapreduce.jobhistory.webapp.address</name><value>node001:19888</value>
</property>
<!-- 配置运行过的日志存放在hdfs上的存放路径 -->
<property><name>mapreduce.jobhistory.done-dir</name><value>/history/done</value>
</property>
<!-- 配置正在运行中的日志在hdfs上的存放路径 -->
<property><name>mapreudce.jobhistory.intermediate.done-dir</name><value>/history/done/done_intermediate</value>
</property>
<property><name>mapreduce.application.classpath</name><value>/opt/hadoop-3.1.2/etc/hadoop,/opt/hadoop-3.1.2/share/hadoop/common/*,/opt/hadoop-3.1.2/share/hadoop/common/lib/*,/opt/hadoop-3.1.2/share/hadoop/hdfs/*,/opt/hadoop-3.1.2/share/hadoop/hdfs/lib/*,/opt/hadoop-3.1.2/share/hadoop/mapreduce/*,/opt/hadoop-3.1.2/share/hadoop/mapreduce/lib/*,/opt/hadoop-3.1.2/share/hadoop/yarn/*,/opt/hadoop-3.1.2/share/hadoop/yarn/lib/*</value>
</property>
[root@node001 ~]# vim /opt/hadoop-3.1.2/etc/hadoop/yarn-site.xml
yarn-site.xml
<!-- 开启RM高可用 -->
<property><name>yarn.resourcemanager.ha.enabled</name><value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property><name>yarn.resourcemanager.cluster-id</name><value>yarn-bdp</value>
</property>
<!-- 指定RM的名字 -->
<property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value>
<property>
</property>
<property><name>yarn.resourcemanager.hostname.rm2</name><value>node003</value>
</property>
<property><name>yarn.resourcemanager.webapp.address.rm1</name><value>node001:8088</value>
</property>
<property><name>yarn.resourcemanager.webapp.address.rm2</name><value>node003:8088</value>
</property>
<!-- 指定zk集群地址 -->
<property><name>yarn.resourcemanager.zk-address</name><value>node001:2181,node002:2181,node003:2181</value>
</property>
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property>
<!-- 开启日志聚合 -->
<property><name>yarn.log-aggregation-enable</name><value>true</value>
</property>
<property><name>yarn.log-aggregation.retain-seconds</name><value>86400</value>
</property>
<!-- 启用自动恢复 -->
<property><name>yarn.resourcemanager.recovery.enabled</name><value>true</value>
</property>
<!-- 制定resourcemanager的状态信息存储在zookeeper集群上 -->
<property><name>yarn.resourcemanager.store.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- Whether virtual memory limits will be enforced for containers. -->
<property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value>
</property>
<property><name>yarn.nodemanager.vmem-pmem-ratio</name><value>3</value>
</property>
[root@node001 ~]# scp /opt/hadoop-3.1.2/etc/hadoop/yarn-site.xml node002:/opt/hadoop-3.1.2/etc/hadoop/
[root@node001 ~]# scp /opt/hadoop-3.1.2/etc/hadoop/yarn-site.xml node003:/opt/hadoop-3.1.2/etc/hadoop/
[root@node001 ~]# scp /opt/hadoop-3.1.2/etc/hadoop/mapred-site.xml node002:/opt/hadoop-3.1.2/etc/hadoop/
[root@node001 ~]# scp /opt/hadoop-3.1.2/etc/hadoop/mapred-site.xml node003:/opt/hadoop-3.1.2/etc/hadoop/
[root@node001 ~]# start-dfs.sh(开启集群)
[root@node001 ~]# start-yarn.sh (开启yarn)
[root@node01 hadoop]# mr-jobhistory-daemon.sh start historyserver(开启history)
[root@node001 ~]# hadoop fs -put zookeeper.out /bdp (上传文件zookeeper到集群的bdp目录下)
[root@node001 mapreduce]# hadoop jar /opt/hadoop-3.1.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.2.jar wordcount /bdp/zookeeper.out /bdp/outputzookeeper/
[root@node001 mapreduce]# hadoop fs -ls /bdp/*/*-rw-r--r-- 2 root supergroup 0 2023-03-31 21:47 /bdp/outputzookeeper/_SUCCESS-rw-r--r-- 2 root supergroup 5331 2023-03-31 21:47 /bdp/outputzookeeper/part-r-00000-rw-r--r-- 2 root supergroup 20758178 2023-03-31 04:02 /bdp/tmp/winutils-master.zip
[root@node001 mapreduce]# hadoop fs -cat /bdp/outputzookeeper/part-r-00000
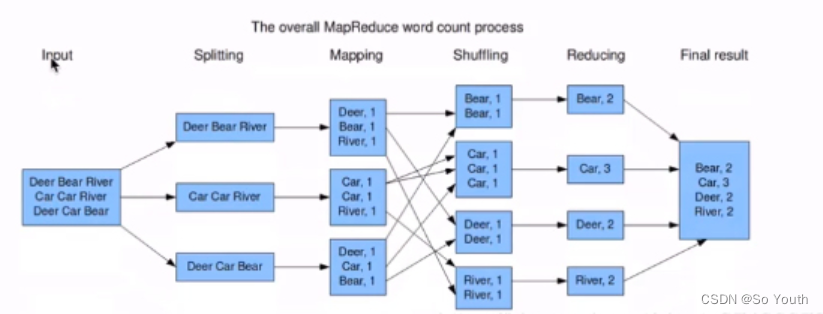
MR的计算流程
计算1T数据中每个单词出现的次数--> wordcount
原始数据File
1T数据被切分成块存放在HDFS上,每一个块有128M大小
数据块Block
hdfs上数据存储的一个单元,同一个文件中块的大小都是相同的
因为数据存储到HDFS上不可变,所以有可能块的数量和集群的计算能力不匹配
我们需要一个动态调整本次参与计算节点数量的一个单位
我们可以动态的改变这个单位--》参与的节点
切片Split
切片是一个逻辑概念
在不改变现在数据存储的情况下,可以控制参与计算的节点数目
通过切片大小可以达到控制计算节点数量的目的有多少个切片就会执行多少个Map任务
一般切片大小为Block的整数倍(2 1/2)防止多余创建和很多的数据连接
如果Split>Block ,计算节点少了
如果Split<Block ,计算节点多了
默认情况下,Split切片的大小等于Block的大小 ,默认128M
一个切片对应一个MapTask
MapTask

map默认从所属切片读取数据,每次读取一行(默认读取器)到内存中
我们可以根据自己书写的分词逻辑(空格分隔,就是分隔符).计算每个单词出现的次数
这是就会产生 (Map<String,Integer>)临时数据,存放在内存中
但是内存大小是有限的,如果多个任务同时执行有可能内存溢出(OOM(Out of Memory))
如果把数据都直接存放到硬盘,效率太低
我们需要在OOM和效率低之间提供一个有效方案可以现在内存中写入一部分,然后写出到硬盘
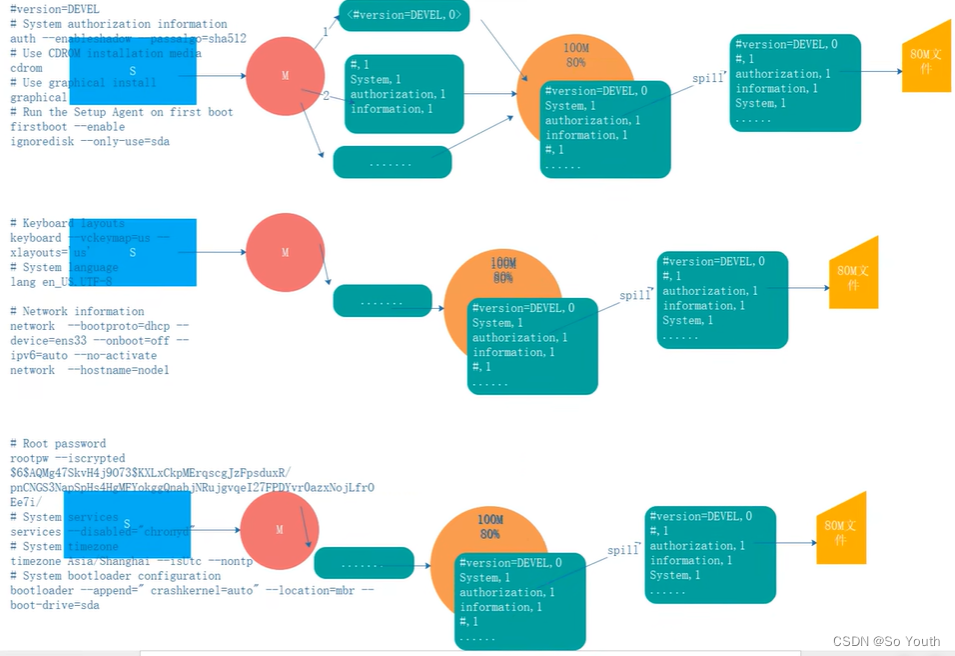

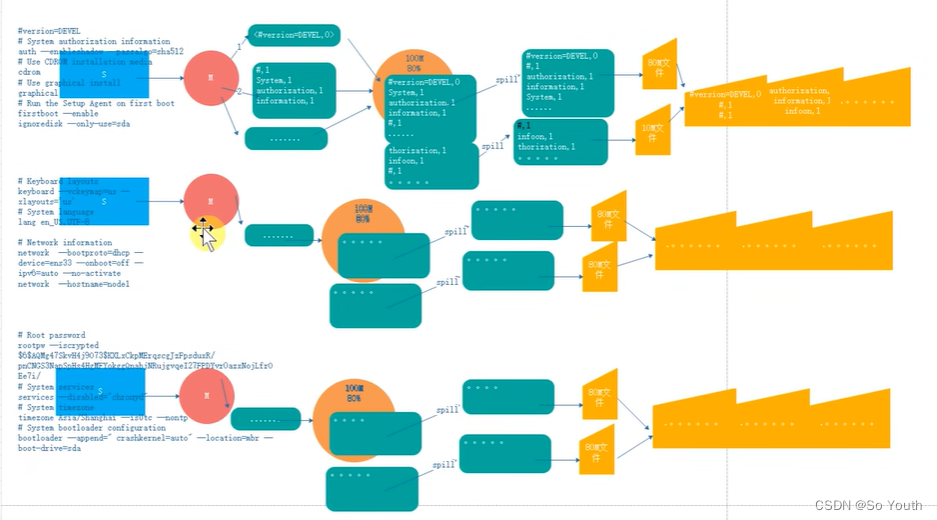
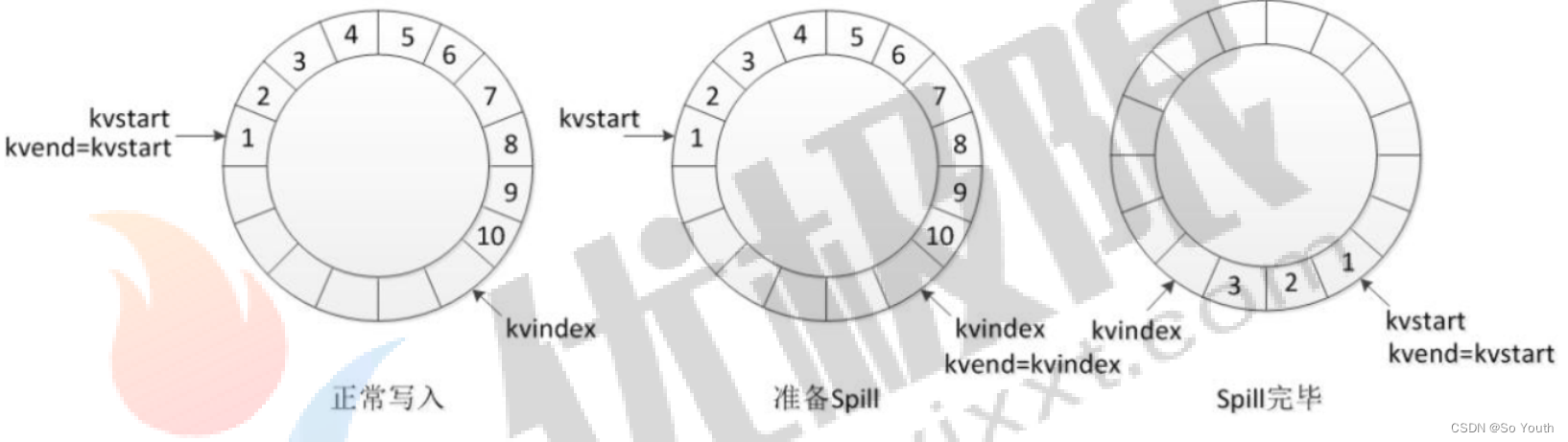
环形数据缓冲区
可以循环利用这块内存区域,减少数据溢写时map的停止时间每一个Map可以独享的一个内存区域在内存中构建一个环形数据缓冲区(kvBuffer),默认大小为100M设置缓冲区的阈值为80%,当缓冲区的数据达到80M开始向外溢写到硬盘溢写的时候还有20M的空间可以被使用效率并不会被减缓而且将数据循环写到硬盘,不用担心OOM问题
分区Partation
根据Key直接计算出对应的Reduce
分区的数量和Reduce的数量是相等的
hash(key) % partation = num
默认分区的算法是Hash然后取余Object的hashCode()---equals()如果两个对象equals,那么两个对象的hashcode一定相等如果两个对象的hashcode相等,但是对象不一定equlas
排序Sort
对要溢写的数据进行排序(QuickSort)
按照先Partation后Key的顺序排序-->相同分区在一起,相同Key的在一起
我们将来溢写出的小文件也都是有序的
溢写Spill
将内存中的数据循环写到硬盘,不用担心OOM问题
每次会产生一个80M的文件
如果本次Map产生的数据较多,可能会溢写多个文件
合并Merge
因为溢写会产生很多有序(分区 key)的小文件,而且小文件的数目不确定
后面向reduce传递数据带来很大的问题
所以将小文件合并成一个大文件,将来拉取的数据直接从大文件拉取即可
合并小文件的时候同样进行排序(归并排序),最终产生一个有序的大文件
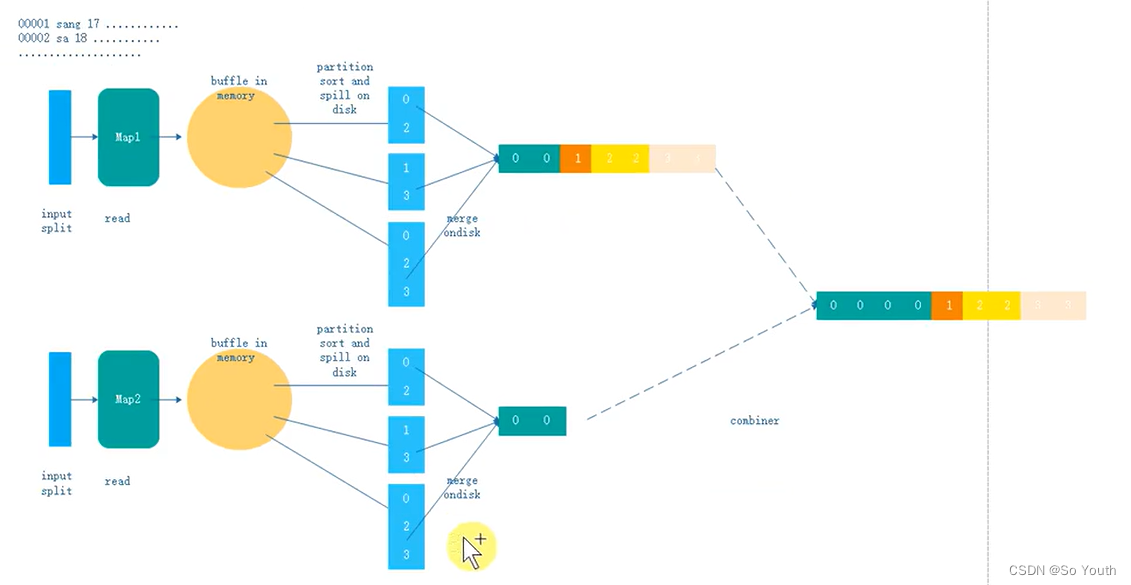
组合器combiner
- 集群的带宽限制了mapreduce作业的数量,因此应该尽量避免map和reduce任务之间的数据传输。hadoop允许用户对map的输出数据进行处理,用户可自定义combiner函数(如同map函数和reduce函数一般),其逻辑一般和reduce函数一样,combiner的输入是map的输出,combiner的输出作为reduce的输入,很多情况下可以直接将reduce函数作为conbiner函数来使用(job.setCombinerClass(FlowCountReducer.class);)。- combiner属于优化方案,所以无法确定combiner函数会调用多少次,可以在环形缓存区溢出文件时调用combiner函数,也可以在溢出的小文件合并成大文件时调用combiner。但要保证不管调用几次combiner函数都不会影响最终的结果,所以不是所有处理逻辑都可以使用combiner组件,有些逻辑如果在使用了combiner函数后会改变最后rerduce的输出结果(如求几个数的平均值,就不能先用combiner求一次各个map输出结果的平均值,再求这些平均值的平均值,这将导致结果错误)。- combiner的意义就是对每一个maptask的输出进行局部汇总,以减小网络传输量。原先传给reduce的数据是 a1 a1 a1 a1 a1第一次combiner组合之后变为a{1,1,1,1,..}第二次combiner后传给reduce的数据变为a{4,2,3,5...}
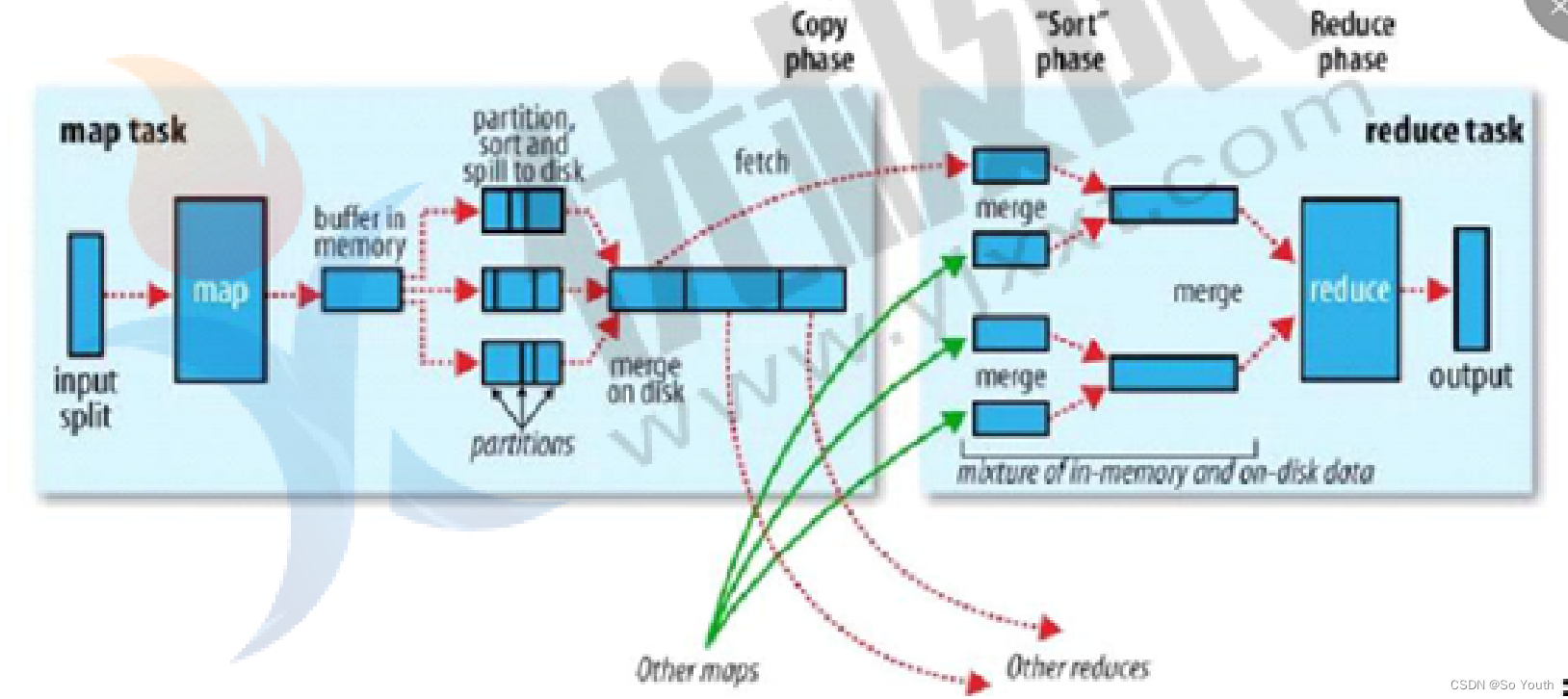
拉取Fetch
我们需要将Map的临时结果拉取到Reduce节点
原则:相同的Key必须拉取到同一个Reduce节点但是一个Reduce节点可以有多个Key
未排序前拉取数据的时候必须对Map产生的最终的合并文件做全序遍历而且每一个reduce都要做一个全序遍历
如果map产生的大文件是有序的,每一个reduce只需要从文件中读取自己所需的即可
合并Merge
因为reduce拉取的时候,会从多个map拉取数据
那么每个map都会产生一个小文件,这些小文件(文件与文件之间无序,文件内部有序)
为了方便计算(没必要读取N个小文件),需要合并文件
归并算法合并成2个
相同的key都在一起
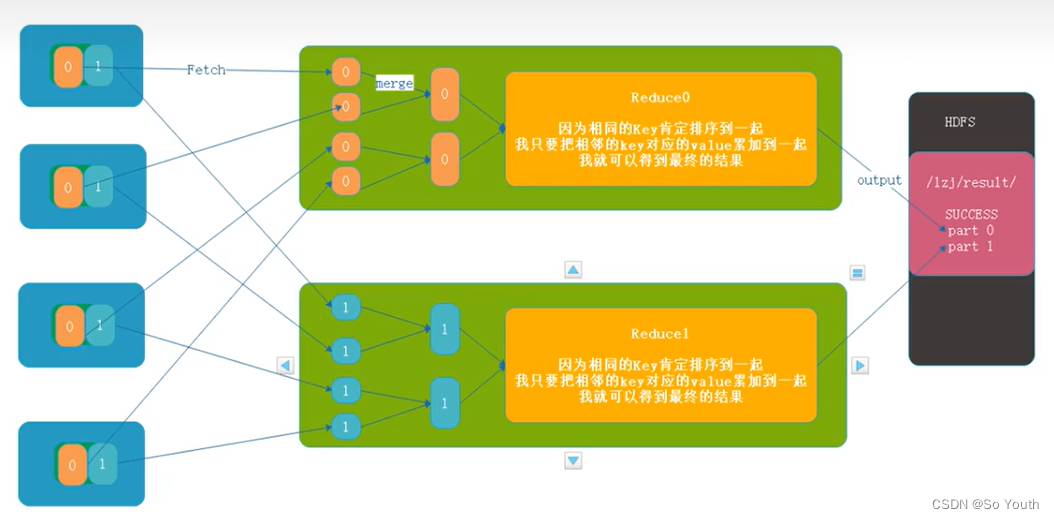
归并Reduce
将文件中的数据读取到内存中
一次性将相同的key全部读取到内存中
直接将相同的key得到结果-->最终结果
写出Output
每个reduce将自己计算的最终结果都会存放到HDFS上
MapReduce过程截图
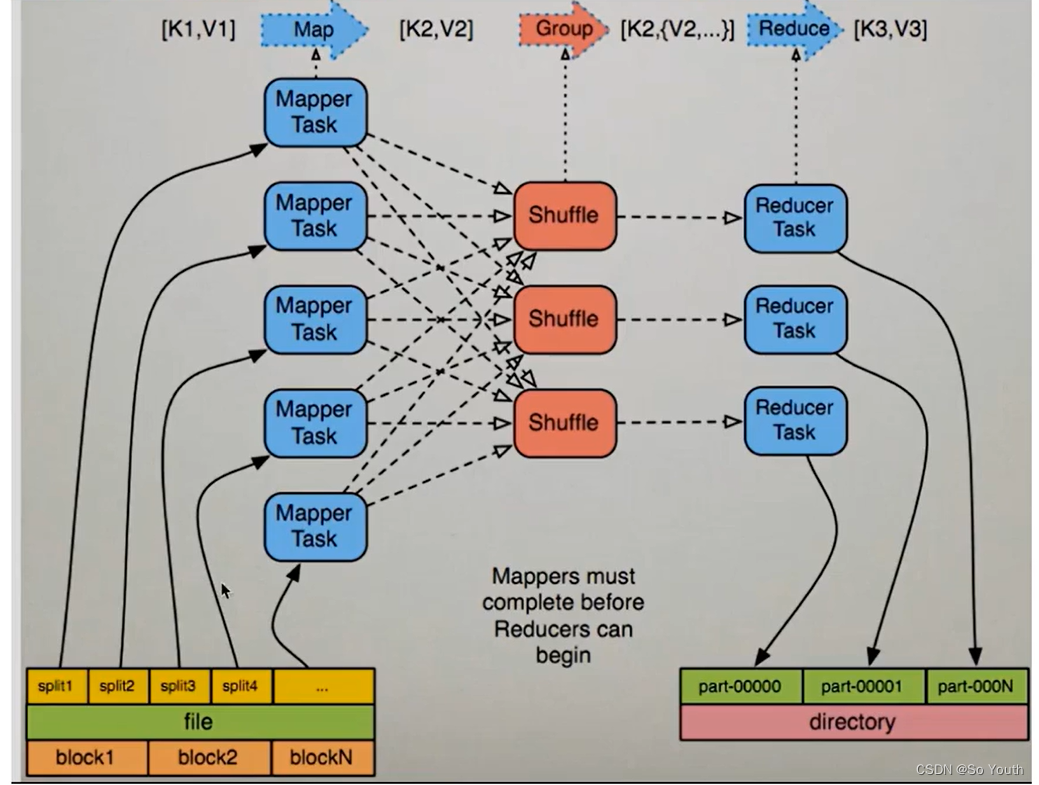
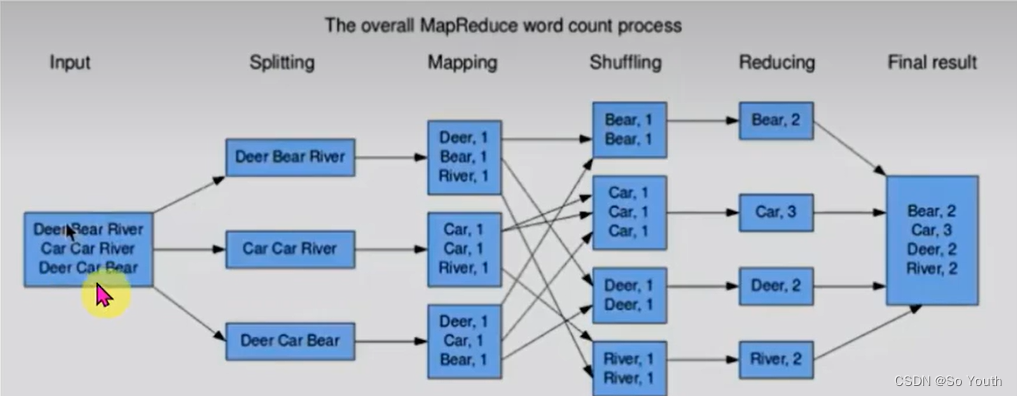
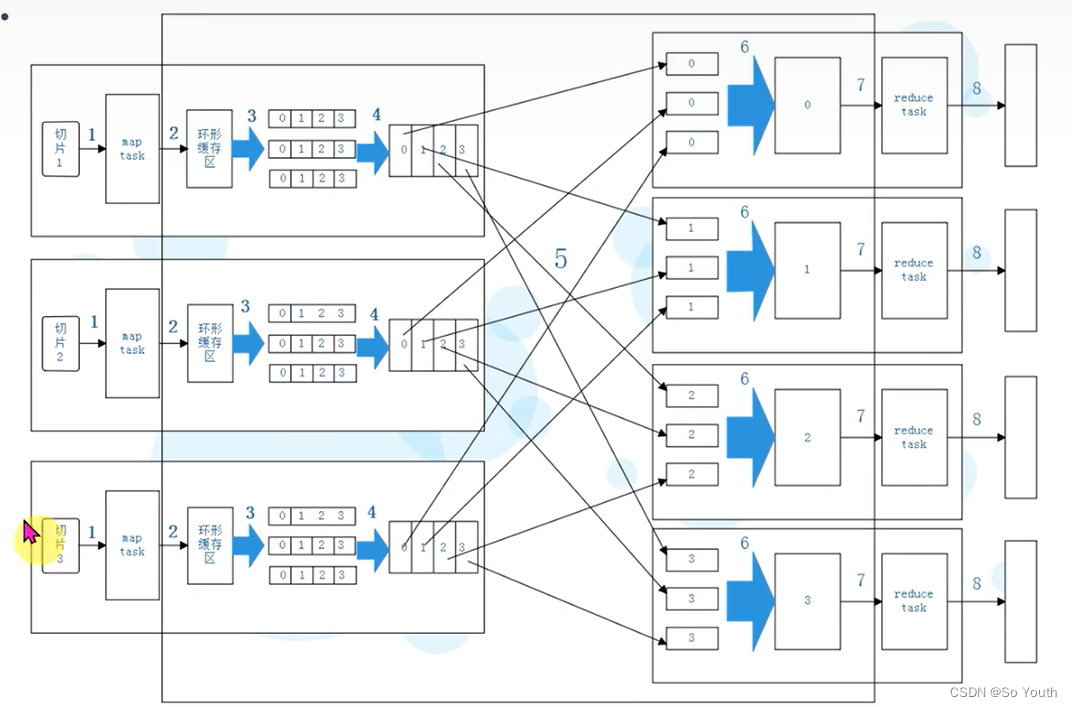
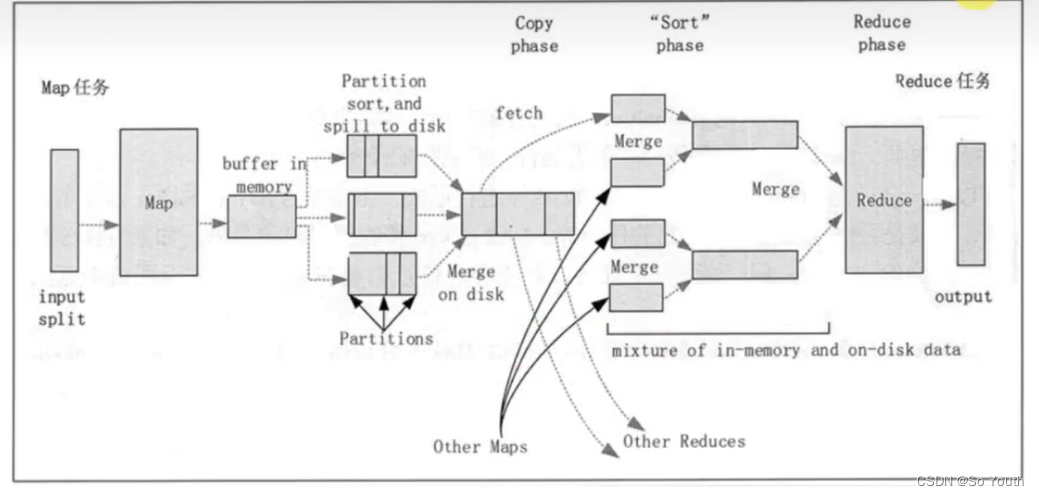
MapReduce案例
WordCount项目
[root@node001 ~]# zkServer.sh start (启动zookeeper)
[root@node001 ~]# zkServer.sh status (查看zookeeper状态)
[root@node001 ~]# start-dfs.sh (启动集群)
[root@node001 ~]# start-yarn.sh (启动yarn)
[root@node001 ~]# jps31730 NameNode31875 DataNode32277 DFSZKFailoverController33125 Jps31450 QuorumPeerMain32794 ResourceManager32107 JournalNode32939 NodeManager
[root@node001 ~]# mr-jobhistory-daemon.sh start historyserver (启动history)
[root@node001 ~]# hadoop fs -put anaconda-ks.cfg / (上传文件到集群)
[root@node001 ~]# cd /opt/hadoop-3.1.2/etc/hadoop/
[root@node001 hadoop]sz core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml (拷贝文件到桌面)
pom.xml
<properties><maven.compiler.source>19</maven.compiler.source><maven.compiler.target>19</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><!-- Hadoop版本控制 --><hadoop.version>3.1.2</hadoop.version><!-- commons-io版本控制 --><commons-io.version>2.4</commons-io.version></properties><dependencies><!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>${hadoop.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>${hadoop.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-common --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-common</artifactId><version>${hadoop.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-core --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>${hadoop.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-jobclient --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-jobclient</artifactId><version>${hadoop.version}</version></dependency><!-- https://mvnrepository.com/artifact/commons-io/commons-io --><dependency><groupId>commons-io</groupId><artifactId>commons-io</artifactId><version>${commons-io.version}</version></dependency><dependency><groupId>com.janeluo</groupId><artifactId>ikanalyzer</artifactId><version>2012_u6</version></dependency></dependencies>
WordCountJob类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountJob {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {//获取配置文件Configuration configuration = new Configuration(true);//本地模式运行configuration.set("mapreduce.framework.name", "local");//创建任务Job job = Job.getInstance(configuration);//设置任务主类job.setJarByClass(WordCountJob.class);//设置任务job.setJobName("bdp-wordcount-" + System.currentTimeMillis());//设置Reduce的数量job.setNumReduceTasks(2);//设置数据的输入路径FileInputFormat.setInputPaths(job, new Path("/anaconda-ks.cfg"));//设置数据的输出路径FileOutputFormat.setOutputPath(job, new Path("/2023-4-1/" + System.currentTimeMillis()));//设置Map的输入的key和value类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);//设置Map和Reduce的处理类job.setMapperClass(WordCountMapper.class);job.setReducerClass(WordCountReducer.class);//提交任务job.waitForCompletion(true);}
}
WordCountMapper
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {//创建对象private IntWritable one = new IntWritable(1);@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//替换特殊字符String valueString = value.toString();valueString = valueString.replaceAll("[^a-zA-Z0-9'\\\\s]", "");//切分字符串String[] values = valueString.split(" ");//向里面添加数据for (String val : values) {context.write(new Text(val), one);}}
}
WordCountReducer
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Iterator;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {//获取迭代器Iterator<IntWritable> iterator = values.iterator();//声明一个计数器int count = 0;while (iterator.hasNext()) {count += iterator.next().get();}//输出数据context.write(key, new IntWritable(count));}
}

打包和运行jar包
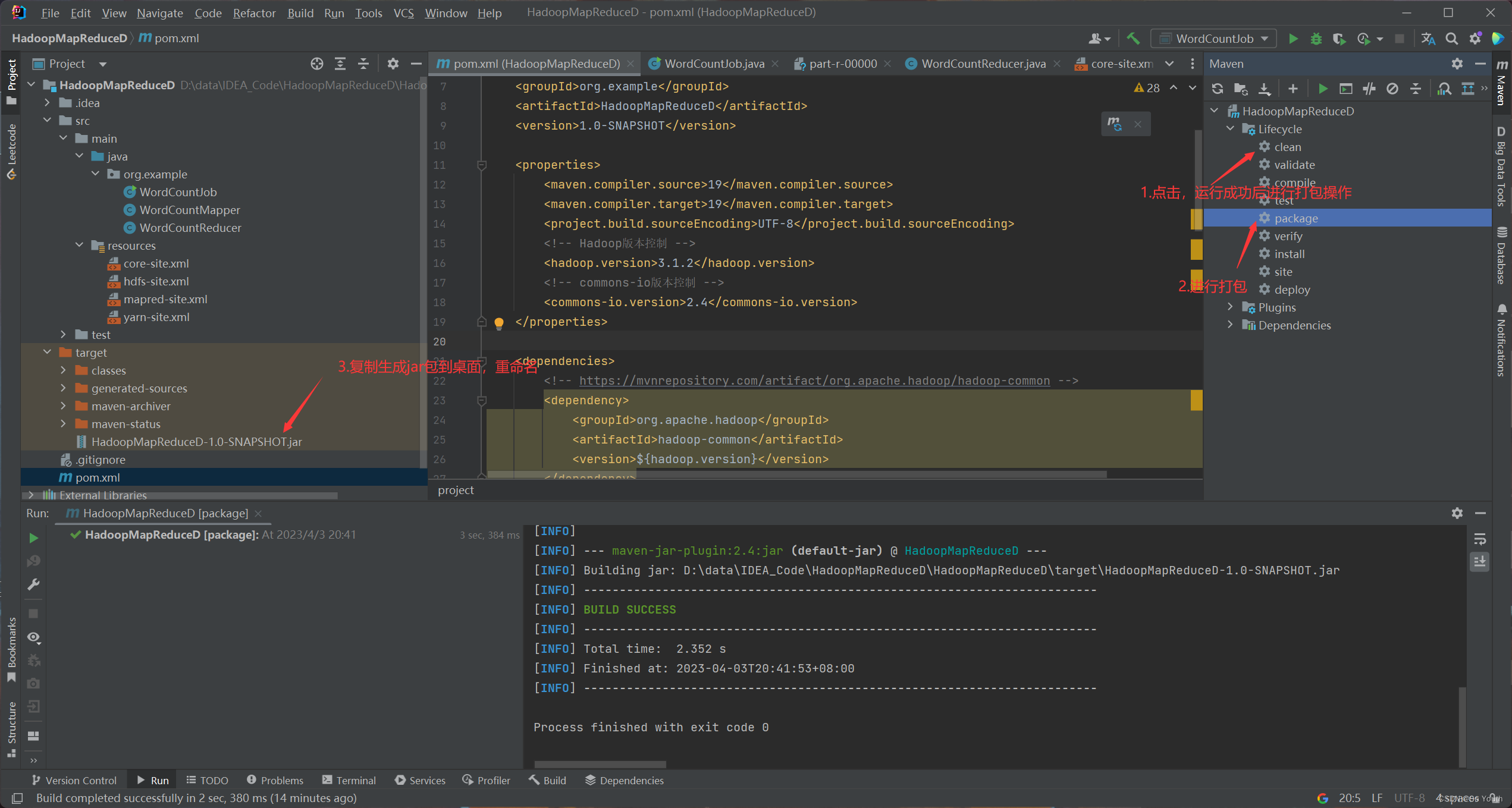
[root@node001 mapreduce]# cd /opt/hadoop-3.1.2/share/hadoop/mapreduce (查看很多jar包)
[root@node001 mapreduce]# cd
[root@node001 ~]# rz (上传打包的jar包)
[root@node001 ~]# hadoop jar HadoopMapReduce_WordCount_0.1.jar org.WordCountJob ( hadoop jar jar包 org.运行主类(包含main))
[root@node001 ~]# cd ..
[root@node001 /]# find -name ntpdate./etc/sysconfig/ntpdate./usr/sbin/ntpdate
[root@node001 /]# crontab -e*/5 * * * * /usr/sbin/ntpdate cn.ntp.org.cn (每5min运行一次)*/2 * * * * sh /root/logs/wordcount01.sh (每2min运行一次)
[root@node001 ~]# cd logs
[root@node001 logs]# vim wordcount01.sh
[root@node001 logs]# cat wordcount01.sh#!/bin/bashecho "$(date)" >> /root/logs/wc.log/opt/hadoop-3.1.2/bin/hadoop jar /root/HadoopMapReduce_WordCount_0.1.jar org.WordCountJob >> /root/logs/wc.log
[root@node001 logs]# /opt/hadoop-3.1.2/bin/hadoop jar /root/HadoopMapReduce_WordCount_0.1.jar org.WordCountJob >> /root/logs/wc.log
[root@node001 ~]# systemctl restart crond.service (重新加载定时服务)
[root@node001 ~]# cd /logs
[root@node001 logs]# tail -F wc.log
[root@node001 ~]# systemctl stop crond.service (停止定时服务)
[root@node001 ~]# systemctl start crond.service (开始定时服务)