几何扩散模型用于分子构象生成ICLR2022

从分子graph预测分子构象是药物发现的基本问题,生成模型在该领域取得进展。受扩散模型启发,作者提出GeoDiff用于分子构象预测。GeoDiff将每个原子视为一个粒子,并学习扩散过程(从噪声分布转为稳定构象)。
来自:GEODIFF: A GEOMETRIC DIFFUSION MODEL FOR MOLECULAR CONFORMATION GENERATION
目录
- 背景概述
- 前置内容
- GEODIFF
-
- 定义
- 等变逆向生成过程
- 训练提升
- 采样
- 实验
背景概述
图表示学习在分子建模的各种任务中取得了巨大的成功,从性质预测到分子生成,通常,分子表示为原子与键构成的图。尽管图的学习在各种应用中都很有效,但对于分子来说,更内在和信息更丰富的表示是3D几何,也称为构象(conformation),其中原子被表示为笛卡尔坐标。3D结构决定了分子的物理性质,因此在许多应用中发挥着关键作用。然而,如何预测稳定的分子构象仍然是一个具有挑战性的问题。基于分子动力学或马尔可夫链蒙特卡罗的传统方法计算成本非常高,特别是对于大分子。
机器学习方法取得了重大进展,特别是深度生成模型。例如用变分自编码器和基于流的模型预测原子距离。由于分子构象是旋转-平移不变的,后续的方法通过利用中间几何变量(如原子距离、键和扭转角)来避免直接建模原子坐标。
关于分子构象旋转-平移不变:对于一个分子的构象,我们可以将整个分子绕任意轴旋转,并且在保持分子的几何结构不变的情况下,将分子平移任意距离,得到一个新的构象。但是,这个新的构象与原始构象是等价的,因为它们具有相同的化学性质。
个人理解:研究构象的意义在于,笛卡尔坐标反映了分子的几何表达,但是这种表达应该确保旋转-平移不变。
然而,由于目前的方法都试图间接地对中间几何变量建模,导致它们在训练或推理过程中都有固有的局限性(比如SchNet)。因此,理想的解决方案仍然是直接建模原子坐标,同时考虑旋转-平移不变性(类比Uni-Mol)。
GEODIFF的一个独特优势是它直接使用原子坐标建模,完全绕过了训练和推断的中间元素使用。该设计有几个关键的优点:
- 首先,模型可以自然地进行端到端训练,而不涉及任何复杂的技术。
- 此外,与从键长或角度求解几何形状不同,GEODIFF避免了累积任何中间误差,因此可以得到更准确的预测结构。
前置内容
标记:将一个有nnn个原子的分子表示为一个无向图G=<V,E>G=<V,E>G=<V,E>,其中V={vi}i=1n,E={eij∣(i,j)⊂∣V∣×∣V∣}V=\\left\\{v_{i}\\right\\}_{i=1}^{n},E=\\left\\{e_{ij}|(i,j)\\subset|V|\\times|V|\\right\\}V={vi}i=1n,E={eij∣(i,j)⊂∣V∣×∣V∣},每个节点描述原子属性,比如化学元素类型,每条边描述原子和原子之间的连接关系,并标注了其化学类型(无连接的边类型为virtual)。对于几何,VVV中的每个原子被坐标向量c∈R3c\\in R^{3}c∈R3嵌入到三维空间,位置的全部集合(即构象)可以表示为一个矩阵C=[c1,...,cn]∈Rn×3C=[c_{1},...,c_{n}]\\in R^{n\\times 3}C=[c1,...,cn]∈Rn×3。
问题定义:分子构象生成任务是一个条件生成问题,给定一个图GGG生成稳定构象CCC。给定多个图,对于每个图GGG,根据其构象CCC作为来自底层玻尔兹曼分布的iid样本,目标是学习一个生成模型pθ(C∣G)p_{\\theta}(C|G)pθ(C∣G),它很容易从中生成样本,并近似玻尔兹曼函数。
等变性:等变性对3D建模的泛化能力至关重要,作者考虑了SE(3)群,即3D空间中旋转,平移的群。这需要不受旋转和平移变换影响的似然估计。
等变和不变的关系:在数学中,等变通常指的是某个变换(例如旋转、平移等)对某个数学对象(例如向量、函数等)不产生影响,即这个变换下,该对象保持不变。而不变则表示该对象在所有变换下都保持不变。
等变和不变之间的关系可以理解为不变是等变的一种特殊情况。如果某个对象在所有变换下都保持不变,那么它也一定在某个特定的变换下保持不变,即等变。但如果某个对象只在某些变换下保持不变,那么它就不是不变的,只能说是等变的。
CNN与等变和不变:在卷积神经网络(CNN)中,等变和不变通常指的是对输入数据的变换对应地影响着卷积层的输出。
具体来说,CNN中的卷积层使用卷积核对输入数据进行卷积运算,得到一组特征映射(feature map)。卷积层中的每个神经元只与输入数据中的一小部分相连,这个小部分通常称为感受野(receptive field)。卷积核的大小与神经元的感受野相同,这样就保证了卷积层的每个神经元只关注输入数据中的一个小区域。
在CNN中,卷积层的等变性和不变性通常与卷积核的参数共享有关。参数共享是指,卷积层使用同一组卷积核对输入数据的不同区域进行卷积运算。这种参数共享的方式导致了CNN具有一定的等变性,即对于输入数据中的某个区域,卷积层会得到一个特征映射,但如果输入数据的另一个区域与前一个区域具有相同的特征,那么卷积层也会得到一个类似的特征映射。这种等变性可以让CNN对输入数据的局部变化做出响应。
然而,CNN中的池化层通常是不变的,因为它对输入数据进行降采样,使得输入数据的空间分辨率变小,这种降采样操作会导致输入数据的某些局部变化被忽略,从而失去了一定的等变性。因此,通常建议在CNN中尽可能减少池化层的使用,或者使用其他的降采样方式来保持更多的等变性。
GEODIFF
定义
令C0C^{0}C0表示构象的Ground Truth,Ct∣t=1,..,TC^{t}|t=1,..,TCt∣t=1,..,T为具有相同维数的隐变量序列,其中,ttt为扩散步骤的index。扩散概率模型可以被描述为具有两个过程的隐变量模型:正向扩散和反向生成。扩散过程逐步向数据C0C^{0}C0注入噪声,而生成过程学习通过逐步消除噪声来恢复扩散过程以恢复GT,比如图1。

- 图1:GEODIFF的扩散和反向过程演示。对于扩散过程,来自固定后验分布q(Ct∣Ct−1)q(C^{t}|C^{t-1})q(Ct∣Ct−1)的噪声逐渐加入直到构象被破坏。对称地,对于生成过程,初始状态CTC^{T}CT从标准高斯分布中采样,并通过马尔可夫核pθ(Ct−1∣G,Ct)p_{\\theta}(C^{t-1}|G,C^{t})pθ(Ct−1∣G,Ct)逐步恢复构象。
扩散过程:根据物理学的见解,将粒子CCC建模为一个不断进化的热力学系统。随着时间的推移,稳定构象C0C^{0}C0将逐渐扩散到混沌态CtC^{t}Ct,并在TTT次迭代后最终收敛为白噪声分布。在扩散模型中,正向过程被定义为一个固定的(而不是可训练的)后验分布q(C1:T∣C0)q(C^{1:T} |C^{0})q(C1:T∣C0)。具体地说,扩散过程定义为一个根据固定方差schedule (β1,...,βT)(\\beta_{1},...,\\beta_{T})(β1,...,βT)的马尔可夫链:q(C1:T∣C0)=∏t=1Tq(Ct∣Ct−1),q(Ct∣Ct−1)=N(Ct;1−βtCt−1,βtI)q(C^{1:T}|C^{0})=\\prod_{t=1}^{T}q(C^{t}|C^{t-1}),\\\\q(C^{t}|C^{t-1})=N(C^{t};\\sqrt{1-\\beta_{t}}C^{t-1},\\beta_{t}I)q(C1:T∣C0)=t=1∏Tq(Ct∣Ct−1),q(Ct∣Ct−1)=N(Ct;1−βtCt−1,βtI)令αt=1−βt\\alpha_{t}=1-\\beta_{t}αt=1−βt,并且α‾t=∏s=1tαs\\overline{\\alpha}_{t}=\\prod^{t}_{s=1}\\alpha_{s}αt=∏s=1tαs,正向过程的一个特殊性质是,任意时间步ttt的q(Ct∣C0)=N(Ct;α‾tC0,(1−α‾t)I)q(C^{t}|C^{0})=N(C^{t};\\sqrt{\\overline{\\alpha}_{t}}C^{0},(1-\\overline{\\alpha}_{t})I)q(Ct∣C0)=N(Ct;αtC0,(1−αt)I)。这表明,当TTT足够大时,整个正向过程将C0C^{0}C0转化为白化的各向同性高斯分布,因此将p(CT)p(C^{T})p(CT)设置为标准高斯分布是自然的。
逆向过程:目标是学习从白噪声CTC^{T}CT中恢复构象C0C^{0}C0(基于给定的分子图GGG)。这个生成过程是上述扩散过程的反向,从有噪声的粒子CT∼p(CT)C^{T}\\sim p(C^{T})CT∼p(CT)开始。这种反向过程描述为具有可学习过渡的条件马尔可夫链:pθ(C0:T−1∣G,CT)=∏t=1Tpθ(Ct−1∣G,Ct),pθ(Ct−1∣G,Ct)=N(Ct−1;μθ(G,Ct,t),σt2I)p_{\\theta}(C^{0:T-1}|G,C^{T})=\\prod_{t=1}^{T}p_{\\theta}(C^{t-1}|G,C^{t}),\\\\p_{\\theta}(C^{t-1}|G,C^{t})=N(C^{t-1};\\mu_{\\theta}(G,C^{t},t),\\sigma_{t}^{2}I)pθ(C0:T−1∣G,CT)=t=1∏Tpθ(Ct−1∣G,Ct),pθ(Ct−1∣G,Ct)=N(Ct−1;μθ(G,Ct,t),σt2I)其中,μθ\\mu_{\\theta}μθ为参数化神经网络,用于估计均值,σt\\sigma_{t}σt为user定义的方差。初始分布p(CT)p(C^{T})p(CT)设为标准高斯分布。给定一个图GGG,首先从p(CT)p(C^{T})p(CT)中绘制混沌粒子CTC^{T}CT来生成其3D结构。然后通过反向马尔可夫核pθ(Ct−1∣G,Ct)p_{\\theta}(C^{t-1}|G,C^{t})pθ(Ct−1∣G,Ct)进行迭代优化。
边际似然可以由pθ(C0∣G)=∫p(CT)pθ(C0:T−1∣G,CT)dC1:Tp_{\\theta}(C^{0}|G)=\\int p(C^{T})p_{\\theta}(C^{0:T-1}|G,C^{T})dC^{1:T}pθ(C0∣G)=∫p(CT)pθ(C0:T−1∣G,CT)dC1:T得出。
等变逆向生成过程
作者考虑构建对旋转和平移不变的概率密度函数pθ(C0)p_{\\theta}(C^{0})pθ(C0)。直观地说,这需要不受平移和旋转影响的似然。设TgT_{g}Tg为群元素g∈SE(3)g\\in SE(3)g∈SE(3)的旋转-平移的变换,则有:
- 命题1:令p(xT)p(x_{T})p(xT)为一个SE(3)-不变的密度函数,比如p(xT)=p(Tg(xT))p(x_{T})=p(T_{g}(x_{T}))p(xT)=p(Tg(xT))。如果马尔可夫变换p(xt−1∣xt)p(x_{t-1}|x_{t})p(xt−1∣xt)为SE(3)-等变,比如p(xt−1∣xt)=p(Tg(xt−1)∣Tg(xt))p(x_{t-1}|x_{t})=p(T_{g}(x_{t-1})|T_{g}(x_{t}))p(xt−1∣xt)=p(Tg(xt−1)∣Tg(xt)),然后我们有密度pθ(x0)=∫p(xT)pθ(x0:T−1∣xT)dx1:Tp_{\\theta}(x_{0})=\\int p(x_{T})p_{\\theta}(x_{0:T-1}|x_{T})dx_{1:T}pθ(x0)=∫p(xT)pθ(x0:T−1∣xT)dx1:T也是SE(3)-不变的。
这个命题表明,从不变初始密度函数p(CT)p(C^{T})p(CT)开始沿等变高斯马尔可夫核pθ(Ct−1∣G,Ct)p_{\\theta}(C^{t-1}|G,C^{t})pθ(Ct−1∣G,Ct)可以得到不变密度pθ(C0)p_{\\theta}(C^{0})pθ(C0)。现在,可以基于去噪扩散框架提供了一个GEODIFF的实现。
不变初始密度函数p(CT)p(C^{T})p(CT):首先介绍不变分布p(CT)p(C^{T})p(CT),它将用于等变马尔可夫链。定义p(CT)p(C^{T})p(CT)为CoM-free standard density ρ^(C)\\widehat{\\rho}(C)ρ(C)。通过考虑CoM-free系统,ρ^(C)\\widehat{\\rho}(C)ρ(C)被构造为旋转-平移不变密度函数。
等变马尔可夫核pθ(Ct−1∣G,Ct)p_{\\theta}(C^{t-1}|G,C^{t})pθ(Ct−1∣G,Ct):与先验密度相似,作者也考虑将所有中间结构CtC^{t}Ct设为CoM-free系统。具体来说,给定均值μθ(G,Ct,t)\\mu_{\\theta}(G,C^{t},t)μθ(G,Ct,t)和方差σt\\sigma_{t}σt,Ct−1C^{t-1}Ct−1的似然被计算为ρ^(Ct−1−μθ(G,Ct,t)σt)\\widehat{\\rho}(\\frac{C^{t-1}-\\mu_{\\theta}(G,C^{t},t)}{\\sigma_{t}})ρ(σtCt−1−μθ(G,Ct,t))。CoM-free高斯函数保证了马尔可夫核的平移不变性。因此,为了实现命题1中定义的等变性质,作者将重点放在旋转等变上。
总的来说,关键的要求保证均值μθ(G,Ct,t)\\mu_{\\theta}(G,C^{t},t)μθ(G,Ct,t)为旋转等变。考虑参数化μθ\\mu_{\\theta}μθ如下:μθ(Ct,t)=1αt(Ct−βt1−α‾tϵθ(G,Ct,t))\\mu_{\\theta}(C^{t},t)=\\frac{1}{\\sqrt{\\alpha_{t}}}(C^{t}-\\frac{\\beta_{t}}{\\sqrt{1-\\overline{\\alpha}}_{t}}\\epsilon_{\\theta}(G,C^{t},t))μθ(Ct,t)=αt1(Ct−1−αtβtϵθ(G,Ct,t))其中,ϵθ\\epsilon_{\\theta}ϵθ为神经网络。直观地,ϵθ\\epsilon_{\\theta}ϵθ学习预测破坏构象所必需的噪声。
现在的问题是将ϵθ\\epsilon_{\\theta}ϵθ设为平移-旋转等变的。作者使用graph field network(GFN)作为网络。在第lll层,GFN采用节点嵌入hl∈Rn×bh^{l}\\in R^{n\\times b}hl∈Rn×b(bbb为特征维数)和对应的坐标嵌入xl∈Rn×3x^{l}\\in R^{n\\times 3}xl∈Rn×3作为输入,输出hl+1h^{l+1}hl+1和xl+1x^{l+1}xl+1:mij=Φm(hil,hjl,∣∣xil−xjl∣∣2,eij;θm)hil+1=Φh(hil,∑j∈N(i)mij;θh)xil+1=∑j∈N(i)1dij(ci−cj)Φx(mij;θx)m_{ij}=\\Phi_{m}(h_{i}^{l},h_{j}^{l},||x_{i}^{l}-x_{j}^{l}||^{2},e_{ij};\\theta_{m})\\\\h_{i}^{l+1}=\\Phi_{h}(h_{i}^{l},\\sum_{j\\in N(i)}m_{ij};\\theta_{h})\\\\x_{i}^{l+1}=\\sum_{j\\in N(i)}\\frac{1}{d_{ij}}(c_{i}-c_{j})\\Phi_{x}(m_{ij};\\theta_{x})mij=Φm(hil,hjl,∣∣xil−xjl∣∣2,eij;θm)hil+1=Φh(hil,j∈N(i)∑mij;θh)xil+1=j∈N(i)∑dij1(ci−cj)Φx(mij;θx)其中,Φ\\PhiΦ为前向网络,dijd_{ij}dij为原子间的距离。N(i)N(i)N(i)为节点iii的邻居节点,包括连接的原子和半径阈值τττ内的其他原子,这使模型能够显式地捕捉长范围的相互作用,并支持具有断开部分的分子图。初始嵌入h0h^{0}h0是原子嵌入(来自GGG)和时间步嵌入(来自ttt)的组合,x0x^{0}x0是原子坐标。该网络与其他GNN的不同在于,xxx的更新结合了径向方向的权重,并且权重直接从构象的坐标进行建模。这可以确保xLx^{L}xL是旋转等变的。
直观地说,已知hlh^{l}hl已经不变且xlx^{l}xl等变,消息嵌入mmm也将是不变的,因为它只依赖于不变特征。由于xxx是用不变特征加权的相对差ci−cjc_i−c_jci−cj来更新的,因此它将是平移不变和旋转等变的。并且在每一层直接使用构象坐标建模,避免了误差累积,可以得到更准确的表示。
训练提升
在制定了生成过程和模型参数化之后,现在考虑反向的实际训练目标。对于生成过程,由于直接优化精确的对数似然是难以处理的,作者转而最大化变分下界(ELBO)。
先验概率,似然,后验概率的具体含义是根据贝叶斯公式灵活变动的,通常,后验概率正比于似然×先验概率,设ppp为某个概率密度:p(Ct∣Ct−1)∝p(Ct−1∣G,Ct)p(G,Ct)p(C^{t}|C^{t-1})∝p(C^{t-1}|G,C^{t})p(G,C^{t})p(Ct∣Ct−1)∝p(Ct−1∣G,Ct)p(G,Ct)在变分推理中,后验分布是很难计算的,我们使用近似的概率分布(该分布是可参数化的已知分布),尝试在给定被观测变量Ct−1C^{t-1}Ct−1情况下,估计隐变量CtC^{t}Ct概率分布的过程称为变分推理。如果我们对隐变量进行采样,并且在给定隐变量的情况下,使用似然对被观测变量进行采样,就称为生成过程。
首先,对数边际似然的期望为:E[log(pθ(C0∣G))]=E[logEq(C1:T∣C0)pθ(C0:T∣G)q(C1:T∣C0)]≥−Eq[∑t=1TDKL(q(Ct−1∣Ct,C0)∣∣pθ(Ct−1∣Ct,G))]E[log(p_{\\theta}(C^{0}|G))]=E[logE_{q(C^{1:T}|C^{0})}\\frac{p_{\\theta}(C^{0:T}|G)}{q(C^{1:T}|C^{0})}]\\\\\\geq -E_{q}[\\sum_{t=1}^{T}D_{KL}(q(C^{t-1}|C^{t},C^{0})||p_{\\theta}(C^{t-1}|C^{t},G))]E[log(pθ(C0∣G))]=E[logEq(C1:T∣C0)q(C1:T∣C0)pθ(C0:T∣G)]≥−Eq[t=1∑TDKL(q(Ct−1∣Ct,C0)∣∣pθ(Ct−1∣Ct,G))]其中,q(Ct−1∣Ct,C0)q(C^{t-1}|C^{t},C^{0})q(Ct−1∣Ct,C0)为易于分析的N(α‾t−1βt1−α‾tC0+αt(1−α‾t−1)1−α‾tCt,1−α‾t−11−α‾tβt)N(\\frac{\\sqrt{\\overline{\\alpha}_{t-1}}\\beta_{t}}{1-\\overline{\\alpha}_{t}}C^{0}+\\frac{\\sqrt{\\alpha_{t}}(1-\\overline{\\alpha}_{t-1})}{1-\\overline{\\alpha}_{t}}C^{t},\\frac{1-\\overline{\\alpha}_{t-1}}{1-\\overline{\\alpha}_{t}}\\beta_{t})N(1−αtαt−1βtC0+1−αtαt(1−αt−1)Ct,1−αt1−αt−1βt)。最大化ELBO等价于最小化每一步的KL散度:L=∑t=1TγtE(C0,G)∼q(C0,G),ϵ∼N(0,I)[∣∣ϵ−ϵθ(G,Ct,t)∣∣22]L=\\sum_{t=1}^{T}\\gamma_{t}E_{(C^{0},G)\\sim q(C^{0},G),\\epsilon\\sim N(0,I)}[||\\epsilon-\\epsilon_{\\theta}(G,C^{t},t)||_{2}^{2}]L=t=1∑TγtE(C0,G)∼q(C0,G),ϵ∼N(0,I)[∣∣ϵ−ϵθ(G,Ct,t)∣∣22]其中,Ct=α‾tC0+1−α‾tϵC^{t}=\\sqrt{\\overline{\\alpha}_{t}}C^{0}+\\sqrt{1-\\overline{\\alpha}_{t}}\\epsilonCt=αtC0+1−αtϵ,γt=βt2αt(1−α‾t−1)\\gamma_{t}=\\frac{\\beta_{t}}{2\\alpha_{t}(1-\\overline{\\alpha}_{t-1})}γt=2αt(1−αt−1)βt。注意,每一步中的噪声没有设计为等变方差,这会违反前面设计的ϵθ\\epsilon_\\thetaϵθ的性质。最终,作者设计噪声为:ϵ^=∂Ctdt(dt−α‾td01−α‾t)\\widehat{\\epsilon}=\\partial_{C^{t}}d^{t}(\\frac{d^{t}-\\sqrt{\\overline{\\alpha}_{t}}d^{0}}{\\sqrt{1-\\overline{\\alpha}_{t}}})ϵ=∂Ctdt(1−αtdt−αtd0)其中,dtd^{t}dt为3D结构的不变特征,比如原子间距离。
采样
基于训练后的反向过程ϵθ(G,Ct,t)\\epsilon_{\\theta}(G,C^{t},t)ϵθ(G,Ct,t),可以得到均值μθ(G,Ct,t)\\mu_{\\theta}(G,C^{t},t)μθ(G,Ct,t),因此,给定一个图GGG,其构象C0C^{0}C0由第一个采样混沌粒子CT∼p(CT)C^{T}\\sim p(C^{T})CT∼p(CT)生成。然后渐进式采样Ct−1∼pθ(Ct−1∣G,Ct)=N(Ct−1;μθ(Ct,G,t),σt2I)C^{t-1}\\sim p_{\\theta}(C^{t-1}|G,C^{t})=N(C^{t-1};\\mu_{\\theta}(C^{t},G,t),\\sigma_{t}^{2}I)Ct−1∼pθ(Ct−1∣G,Ct)=N(Ct−1;μθ(Ct,G,t),σt2I)。
实验
作者在两个标准基准上测试GEODIFF:构象生成和性质预测。
数据集:作者使用了GEOM-QM9和GEOM-Drugs,前者含有小分子,后者是中等大小的有机化合物。对于两个数据集,训练分割由40000个分子组成,每个分子有5个构象,结果总共有20万个构象,验证分割与训练分割共享相同的大小,测试分割包含200个不同的分子,QM9有22408种构象,Drugs有14324种构象。
基线:作者将GEODIFF与6个最近或最先进的基线进行比较。对于ML方法,测试了文献报告性能最高的模型:CVGAE,GRAPHDG,CGCF,CONFVAE和CONFGF。还测试了经典的RDKIT方法,其是最流行的构象生成开源软件。
构象生成评价指标:该任务旨在测量不同模型生成的构象的质量和多样性。形式上,令SgS_{g}Sg和SrS_{r}Sr分别表示某个分子生成的和参考的构象集,则覆盖度Coverage和匹配度Matching为(基于RMSD均方根误差):COV(Sg,Sr)=1∣Sr∣∣{C∈Sr∣RMSD(C,C^)≤δ,C^∈Sg∣}∣MAT(Sg,Sr)=1∣Sr∣∑C∈SrminC^∈SgRMSD(C,C^)COV(S_{g},S_{r})=\\frac{1}{|S_{r}|}|\\left\\{C\\in S_{r}|RMSD(C,\\widehat{C})\\leq\\delta,\\widehat{C}\\in S_{g}|\\right\\}|\\\\MAT(S_{g},S_{r})=\\frac{1}{|S_{r}|}\\sum_{C\\in S_{r}}min_{\\widehat{C}\\in S_{g}}RMSD(C,\\widehat{C})COV(Sg,Sr)=∣Sr∣1∣{C∈Sr∣RMSD(C,C)≤δ,C∈Sg∣}∣MAT(Sg,Sr)=∣Sr∣1C∈Sr∑minC∈SgRMSD(C,C)其中,δδδ分别为QM9和Drugs数据集的0.5Å和1.25Å。一般来说,较高的COV或较低的MAT表明产生了更真实的构象。
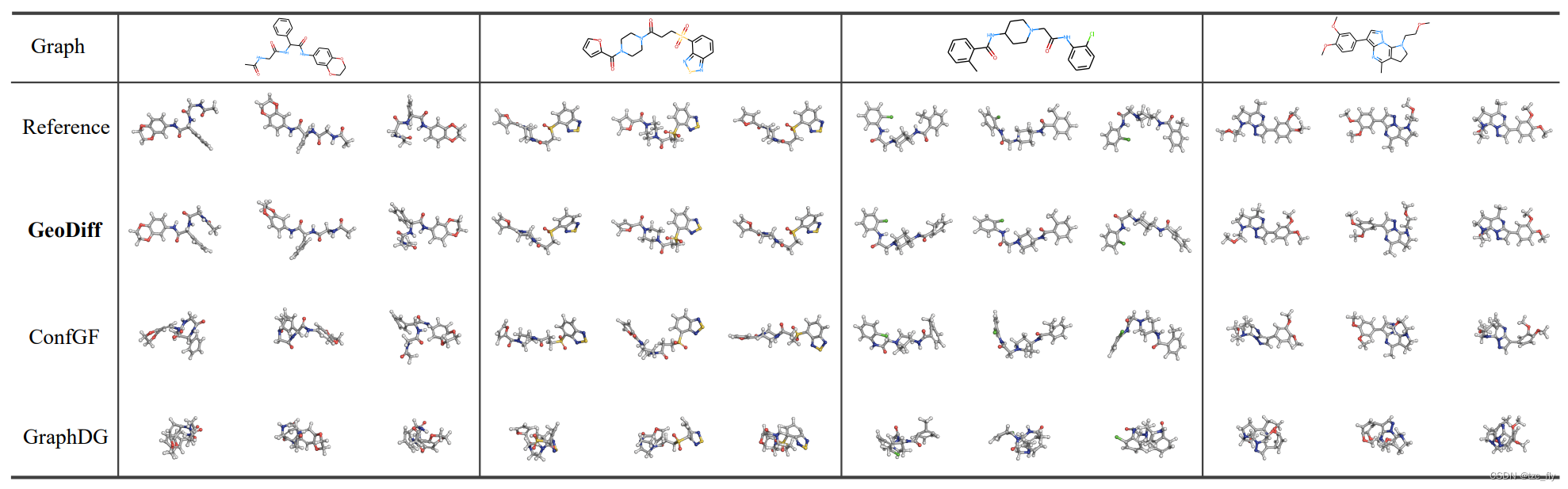
- 图2:从Drugs数据集生成的结构示例。对于每个模型,都展示了最符合GT的构象。
属性预测评价指标:这项任务估计了一组生成构象的分子集合属性。这可以直接评估生成的样品的质量。作者从GEOM-QM9中提取了一个涵盖30个分子的split,并为每个分子生成50个样本。然后使用化学工具包PSI4计算每个分子的属性,并与Ground Truth进行对比。